




 本文介绍了知识感知图神经网络(KGNN-LS)在推荐系统中的应用,通过个性化关系评分函数将知识图谱转化为用户特定的加权图,结合图神经网络和标签平滑正则化来提升推荐性能。标签平滑假设相邻项目具有相似的用户兴趣,通过标签传播优化边缘权重,实现端到端可训练的推荐模型。
本文介绍了知识感知图神经网络(KGNN-LS)在推荐系统中的应用,通过个性化关系评分函数将知识图谱转化为用户特定的加权图,结合图神经网络和标签平滑正则化来提升推荐性能。标签平滑假设相邻项目具有相似的用户兴趣,通过标签传播优化边缘权重,实现端到端可训练的推荐模型。
Wang H , Zhang F , Zhang M , et al. Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems[C]// the 25th ACM SIGKDD International Conference. ACM, 2019.
1 摘要
知识图谱能捕获结构化信息和一组实体或项目之间的关系。因此,知识图是一个可靠的信息来源,可以有助于改进推荐系统。然而,该领域现有的方法依赖于手动提取特征工程,不允许端到端训练。在这里,作者提出了具有标签光滑度正则化(KGNN-LS)的知识感知图神经网络来提供更好的推荐。从概念上讲,作者的方法首先应用能识别给定用户在知识图谱中重要关系的可训练函数来计算特定用户的项目嵌入。(也就是用特定项目来表示该用户)。通过这种方法,将知识图谱转换为一个特定于用户的加权图,然后应用一个图神经网络来计算个性化的项目嵌入。为了提供更好的偏好,作者依赖于标签平滑性假设,该假设假设知识图中的相邻项目很可能有相似的用户相关性标签/分数。标签平滑提供了边缘权值的正则化,并证明了它等价于图上的标签传播方案。
机器学习中什么是端到端的学习(end-to-end learning)?_cs24k1993的博客-CSDN博客_什么是端到端
2 介绍
在本文中,开发了具有标签平滑正则化(KGNN-LS)的知识感知图神经网络,将GNNs结构扩展到知识图,以同时捕获项目之间的语义关系以及个性化的用户偏好和兴趣。知识图谱中的异构型解释如下:使用一个可训练和个性化的关系评分函数,将KG转换为一个特定于用户的加权图,它既描述了KG的语义信息,以及用户的个性化兴趣。例如,在电影推荐设置中,关系评分功能可以了解到一个给定的用户真的关心电影和“导演”关系,而有的用户则更关心电影和“主演”之间的关系。利用这个个性化的加权图,然后应用一个图神经网络,对于每个项目节点,在他的局部网络邻域上聚合节点特征信息来计算其嵌入。通过这种方式,嵌入的每个项目将以用户个性化的方式捕获它的局部KG结构。
本文的方法与传统gnn之间的一个显著区别是,gnn图中的边权值没有作为输入。本文以有监督的方式训练的用户特定的关系评分函数来设置边权值。然而,增加的边权值的灵活性使得学习过程容易过拟合,因为关系评分函数的唯一监督信号来源来自用户-项交互(一般稀疏)。为了解决这个问题,本文开发了一种边缘权值正则化技术,从而导致更好的泛化。作者开发了一种基于标签平滑度的方法,该方法假设KG中的相邻实体很可能具有相似的用户相关性标签/分数。在上下文中,这种假设意味着用户倾向于与KG附近的项目有相似的偏好。作者证明了标签光滑性正则化等价于标签传播,并设计了一个用于标签传播的leave-one-out损失函数,为学习边缘评分函数提供额外的监督信号。作者表明,知识感知图神经网络和标签平滑性正则化可以在同一框架下统一,其中标签平滑性可以被视为知识感知图神经网络上正则化的自然选择。
3 任务制定
首先描述kg感知的推荐问题,并引入符号。在一个典型的推荐场景中,有一组用户U和一组项目v。用户-项交互矩阵Y是根据用户的隐式反馈来定义的,其中yuv=1表明用户u参与了项目v,如点击、观看或购买实体E集由项目V(V⊆E)和非项目E\V(例如对应于项目/产品属性的节点)组成。还有一个知识图G={(h,r,t)},其中h∈E、r∈R和t∈E分别表示知识三重体的头部、关系和尾部,E和R分别是知识图中的实体和关系集。给定用户-项目交互矩阵Y和知识图G,本文的任务是预测用户u是否对他/她以前没有参与过的项目v有潜在的兴趣。下表为本文的一些符合。

4 模型方法
4.1 知识感知图神经网络
方法的第一步是将一个异构知识图转换为一个描述用户偏好的用户个性化加权图。为此,作者使用了一个特定于用户的关系评分函数Su(r),它提供了关系r对用户u:Su(r)=g(u,r)的重要性,其中u和r分别是用户u和关系类型r的特征向量,g是一个可微函数,如内部积。直观地说,Su(r)描述了关系r对用户u的重要性。例如,一个用户可能对电影导演更感兴趣,但另一个用户可能更关心电影的主角。
给定用户u的用户特定的关系评分函数Su(·),知识图G因此可以转换为用户特定的邻接矩阵,其中
表示实体ei和ej之间的关系。如果如果ei和ej之间没有关系,则为
.如图一的前两个子图。
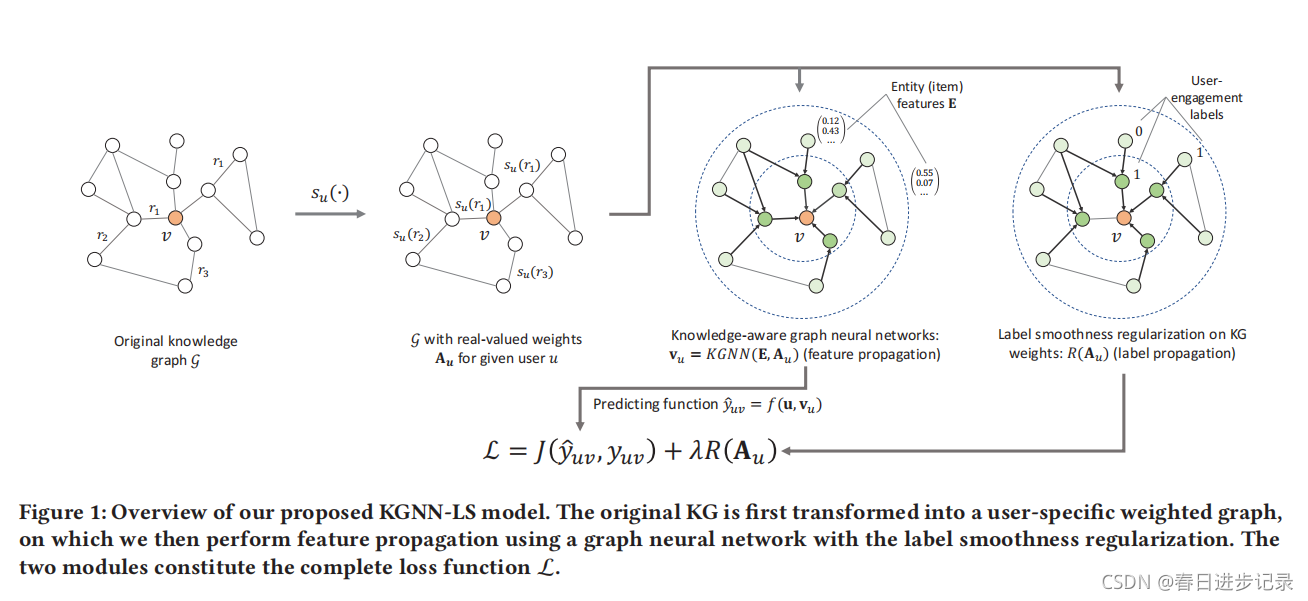
作者还将实体的原始特征矩阵表示为,其中d0为原始实体特征的维数。然后,使用多个前馈层,通过聚合相邻实体的表示来更新实体表示。具体来说,一层的正向传播可以表示为
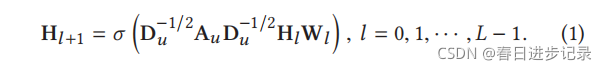
在本篇文章中,将G视为一个无向图,所以Au是一个对称矩阵。如果三元组(h、r1、t)和(t、r2、h)都存在,只考虑r1和r2中的一个。这是由于:(1)r1和r2是相反的,语义相关;(2)视Au为对称矩阵将大大增加矩阵密度。
对于本文的模型的体系结构有几个候选设计,例如,GCN或GraphSAGE。这里使用GCN作为基础模型。
Hl是第l层中实体的隐藏表示矩阵,H0=E。Au是聚合相邻实体的表示向量。在本文中,设置了Au←Au+I,即向每个实体添加自连接,以确保在更新实体表示时考虑到实体本身的旧表示向量。Du是一个Au矩阵的度矩阵,是对角矩阵,因此,使用Du−1/2对Au进行归一化,保持实体表示矩阵Hl稳定。Wl∈Rdl×dl+1是一个层特定的可训练权值矩阵,σ是一个非线性激活函数,L是一个层数。
单个GNN层结合自身和KG中的近邻的表示结合来计算实体的表示。因此,可以自然地将模型扩展到多层,以更广泛、更深的方式探索用户的潜在兴趣。最终输出为Hl∈R|E|×dl。这是混合自己和邻居的初始特征的实体表示,直到L。最后,用户u与项目v的预测接触概率由yˆuv=f(u,vu)计算,其中vu(即HL的第v行)是项目v的最终表示向量,f是一个可微预测函数,例如,内积或多层感知器。请注意,vu是特定于用户的,因为邻接矩阵Au是特定于用户的。此外,需要注意的是,该系统是端到端可训练的,其中梯度从f(·)通过GNN(参数矩阵W)流到g(·),并最终流到用户u和项目v的表示。
4.2 标签平滑度正则化
值得注意的是,本文的模型和gnn之间存在显著差异。在传统的GNN中,输入图的边权值是固定的;但在我们的模型中,方程中的边权值为Du−1/2AuDu−1/2是可学习的(包括函数g的参数和用户和关系的特征向量),也需要像W这样的监督训练。虽然提高了模型的拟合能力,但这将不可避免地使优化过程容易发生过拟合,因为监督信号的唯一来源是来自GNN层外的用户-项目交互。
此外,边缘权值确实在图上的表示学习中发挥着重要作用,正如之前的大量工作所强调的那样。因此,需要对边缘权值进行正则化来帮助学习实体表示,并帮助更有效地推广到未观察到的交互。
让我们看看一个理想的边权值集应该是什么样子的。考虑G上的一个标签函数lu:E→R,它被限制在节点v∈V⊆E处取一个特定的值lu(v)=yuv。在本文中,如果user u发现item v相关并与之交互,则lu(v)=1,则lu(v)=0。直观地说,我们希望KG中的相邻实体很可能有相似的相关性标签,这被称为标签平滑性假设。这激发了我们选择能量函数E:
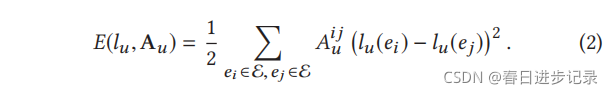
通过以下定理证明了最小能量标签函数是调和函数(满足拉普拉斯算子):

(看不懂没关系,只要知道)这表明,每个非项目实体ei∈E\V处的l∗u值是其相邻实体的平均值,这导致了以下标签传播方案




我照着简单推了一下

定理2提供了一种达到相关标签函数E最小值的方法。然而,L∗u没有提供任何更新边权矩阵Au的信号,因为l∗u有标签的部分,等于它们的真实相关性标签Y[u,V];此外,不知道未标记节点l∗u(E\V)的真正相关性标签。
为了解决这个问题,使用最小化留一法损失。假设我们拿出一个项目v,并处理它不带标记。然后,我们通过使用其余的(标记)项目和(未标记)非项目实体来预测其标签。预测过程与定理2中的标签传播相同,但项目v的标签是隐藏的,需要计算。这样,v(即相关标签的yuv)与预测标签l*u(v)之间的差异可以作为正则化边缘权值的监督信号:
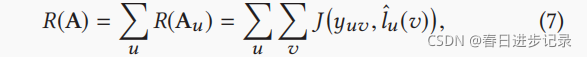
其中J是交叉熵损失函数。给定式7中的正则化,一个理想的边权值矩阵A应该再现每个保留项目的真实相关性标签,同时也满足相关性标签的平滑性.
4.3 损失函数
结合知识感知图神经网络和LS正则化,得到以下完全损失函数:
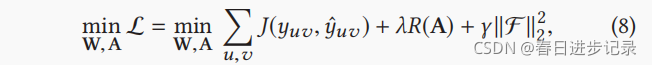
其中F是l2正则化器,λ和γ是超参数。第一项对应于GNN中同时学习转换矩阵W和边权值A的部分,第二项R(·)对应于标签平滑部分,可以看作是对边权值A的约束。因此,R(·)在A上的正则化,帮助GNN学习边缘权值。
值得注意的是,第一项可以看作是在KG上的特征传播,而第二项R(·)可以看作是在KG上的标签传播。对特定用户u,推荐器实际上是从项目特征到用户-项目交互标签的映射,即Fu:Ev→yuv,其中Ev是项目v的特征向量。因此,式子(8)利用Fu的特征和标签的KG的结构信息来捕获用户的高阶偏好。
4.4 讨论
知识图如何帮助找到用户的兴趣?为了直观地理解KG的作用,作者与物理平衡模型进行了一个类比,如图2所示
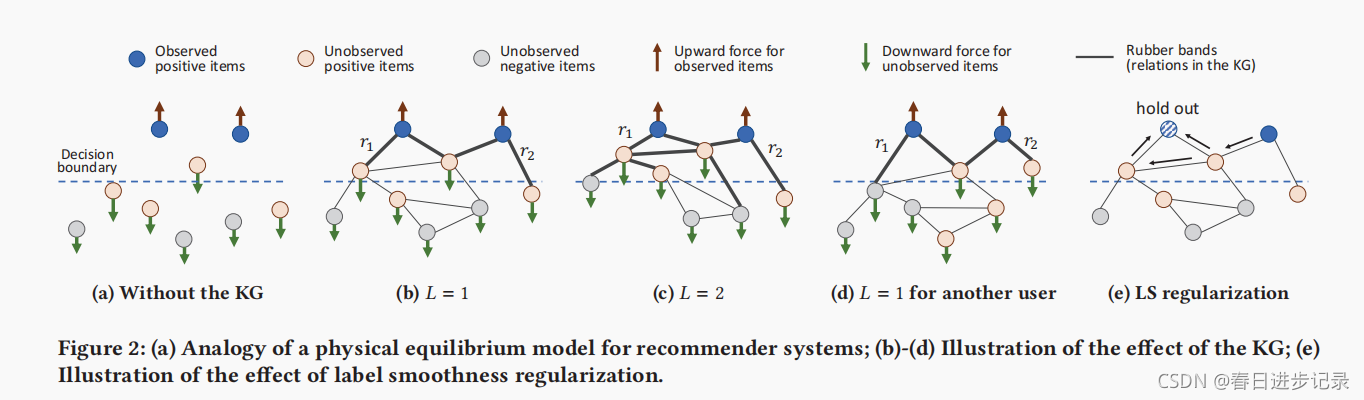
每个实体/项目都被视为一个粒子,而受监督的正用户相关信号作为将观察到的正项目从决策边界向上拉上来的力,而负项目信号作为将未观察到的项目向下推下去的力。如果没有KG(图2a),这些项目只能通过协同过滤效果松散地连接(为了清晰起见,这里没有绘制)。相比之下,KG中的边缘可以作为对连接实体施加明确约束的橡皮带。当层数为L=1(图2b)时,每个实体的表示都是其自身和近邻的混合表示,因此,对正项的优化将同时将它们的近邻拉在一起。随着L的增加,KG的上升力更深(图2c),这有助于探索用户的高阶兴趣,并拉出更多积极的项目。值得注意的是,KG施加的接近约束是个性化的,因为橡皮带的强度(即Su(r))是特定用户和关系的:一个用户可能更喜欢关系r1(图2b),而另一个用户(具有相同的观察项目但不同的未观察项目)可能更喜欢关系r2(图2d)。尽管KG中的边缘施加了力,但边缘权重可能设置不适当,例如,太小,无法拉出未观察到的项目(即橡皮带太弱)。接下来,通过图2e展示了标签平滑度假设如何有助于正则化边缘权值的学习。假设在左上角保留了阳性样本,我们打算用其他的项目来重现它的标签。由于保留样本的真正相关性标签是1,右上角样本有最大的标签值,LS正则化R(A)将强制有箭头的边很大,这样标签可以尽可能地从蓝色“流”到条纹的。因此,这将收紧橡皮筋(用箭头表示),并鼓励模型在更大程度上拉出两个上粉色项目。
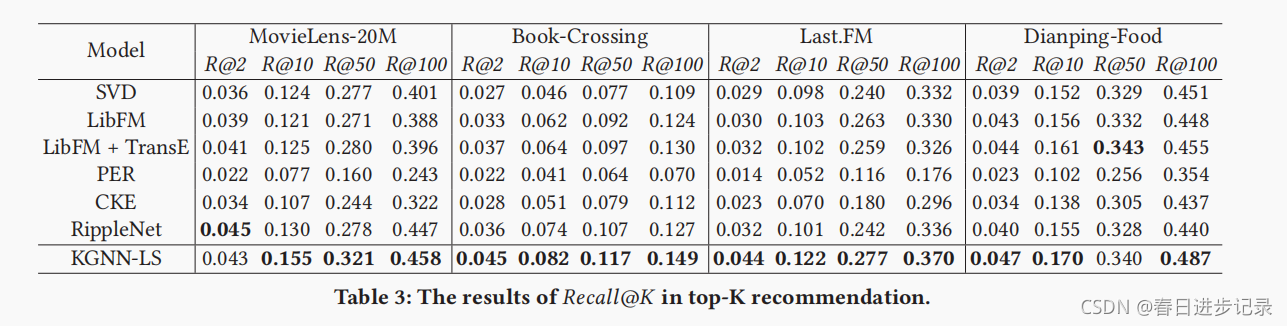
5 实验
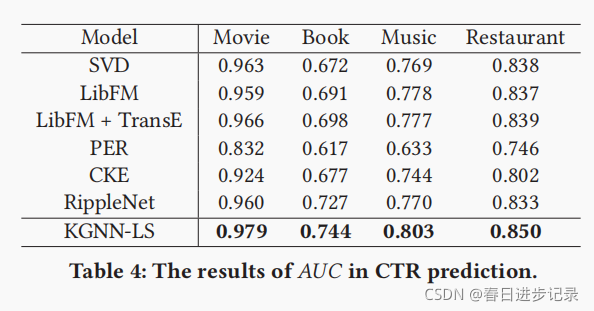
6 个人总结与思考
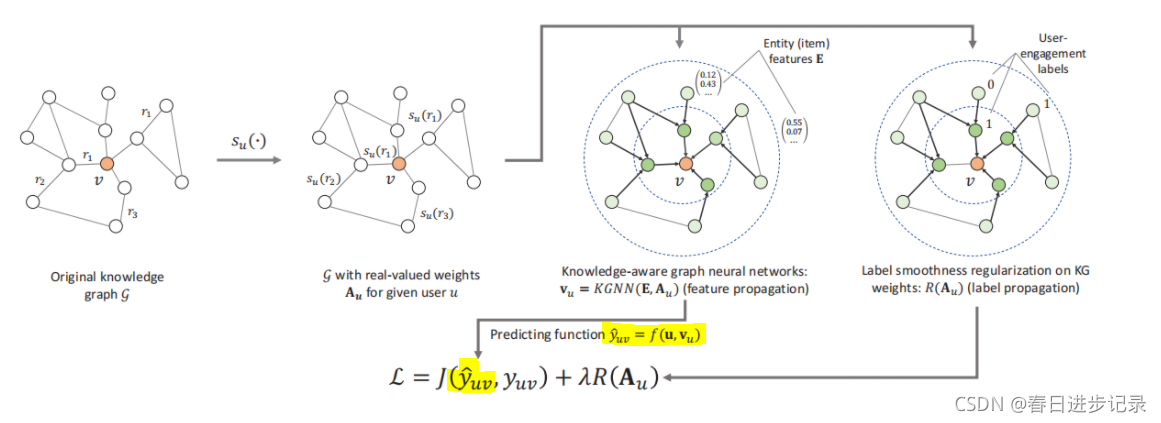
我个人的理解也不一定正确,欢迎指出问题。本文首先用GCN提取特征,通过聚合相邻实体的表示来更新实体表示。使用更新过的用户特定的项目表示与用户矩阵进行计算得到的值。(如上图的黄色部分)采用标签标签平滑作为正则化优化边缘权值,使用留一法,拿出一个项目,隐藏它的标签,使用它的邻居采用标签传播策略得到它的表示,代入式子7。这样它真实标签与标签传播预测出标签l*u(v)之间的差异可以作为正则化边缘权值的监督信号.。标签平滑的意思就是说知识图中的相邻项目很可能有相似的用户相关性标签/分数。
关于上图,我个人理解(不一定正确)。观察到的正项目可能是与用户交互过的项目,未关察到的正项目可能是由用户特定关系所联系到的项目(比如用户更看重导演,那么该电影的导演实体就算作未观察到的正项目)未观察到的负项目,应该就是没有与观察到的正项目有联系的项目。根据用户对关系的评分将无权值知识图谱转换为带权值特定用户图,这些权值表示了该关系对用户的重要性。通过聚合与优化也就是式子8中的第一项,使未观察到的正项目具有更多被推荐的概率。而标签平滑正则化如上图e所示,蓝色条纹的真实值被隐藏,R(A)优化边权值会使带箭头的边权值变大,这样蓝色标签和条纹标签的联系就更紧密了,从而会使旁边的蓝色标签流向蓝色条纹(因为标签平滑认为知识图中的相邻项目很可能有相似的用户相关性标签/分数)。
总的来说,本文利用了KG上的特征传播和KG上的标签传播。

















 7750
7750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









