







1.与简单线性回归区别:
多个自变量(x)
2.多元回归模型:
y=β0+β1x1+β2x2+ ... +βpxp+ε
其中:β0,β1,β2... βp是参数
ε是误差值
3.多元回归方程:
E(y)=β0+β1x1+β2x2+ ... +βpxp
4.估计多元回归方程:
y_hat=b0+b1x1+b2x2+ ... +bpxp
一个样本被用来计算β0,β1,β2... βp的点估计b0, b1, b2,..., bp
5.估计流程(与简单线性回归相似)

6.估计方法
使sum of squares最小
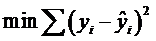
7.例子
一家快递公司送货: x1:运输里程: x2:运输次数 Y:总运输时间
Driving Assignment | X1=Miles Traveled | X2=Number of Deliveries | Y= Travel Time (Hours) |
1 | 100 | 4 | 9.3 |
2 | 50 | 3 | 4.8 |
3 | 100 | 4 | 8.9 |
4 | 100 | 2 | 6.5 |
5 | 50 | 2 | 4.2 |
6 | 80 | 2 | 6.2 |
7 | 75 | 3 | 7.4 |
8 | 65 | 4 | 6.0 |
9 | 90 | 3 | 7.6 |
10 | 90 | 2 | 6.1 |
8.描述参数含义
b0: 平均每多运送一英里,运输时间延长0.0611 小时
b1: 平均每多一次运输,运输时间延长 0.923 小时
9.预测
如果一个运输任务是跑102英里,运输6次,预计多少小时?
Time = -0.869 +0.0611 *102+ 0.923 * 6 = 10.9 (小时)
10.如果自变量中有分类型变量(categorical data),怎么处理?
| 英里数 | 次数 | 车型 | 时间 |
| 100 | 4 | 1 | 9.3 |
| 50 | 3 | 0 | 4.8 |
| 100 | 4 | 1 | 8.9 |
| 100 | 2 | 2 | 6.5 |
| 50 | 2 | 2 | 4.2 |
| 80 | 2 | 1 | 6.2 |
| 75 | 3 | 1 | 7.4 |
| 65 | 4 | 0 | 6 |
| 90 | 3 | 0 | 7.6 |
误差ε是一个随机变量,均值为0
ε的方差对于所有的自变量来说相等
所有ε的值是独立的
ε满足正态分布,并且通过β0+β1x1+β2x2+ ... +βpxp反映y的期望值
12.例子程序实现
(1)首先将数据导入csv文件

程序:
# -*- coding: utf-8 -*-
from numpy import genfromtxt
from sklearn import linear_model
datapath=r"Delivery.csv" #r的意思是认为后面的东西是完整的字符串,忽略斜杠和特殊字符
data=genfromtxt(datapath,delimiter=",") #导入数据,并转换为numpyarray格式,第一个参数是文件的路径,第2个参数是文件的分隔符,因为是csv文件,所以是逗号
print data
x=data[:,:-1] #取所有行,前两列
y=data[:,-1] #取所有行,最后一列
mlr=linear_model.LinearRegression() #调用线性回归模型
mlr.fit(x,y)
print mlr #
print "coef:"
print mlr.coef_ #模型中的参数预测,b1,b2....
print "intercept"
print mlr.intercept_ #模型中的参数预测,b0
xPredict=[102,6]
yPredict=mlr.predict(xPredict)
print"predict:"
print yPredict(2)自变量中有分类型变量
用三列来代表三种车型

# -*- coding: utf-8 -*-
from numpy import genfromtxt
from sklearn import linear_model
datapath=r"Delivery_Dummy.csv" #r的意思是认为后面的东西是完整的字符串,忽略斜杠和特殊字符
data=genfromtxt(datapath,delimiter=",") #导入数据,并转换为numpyarray格式,第一个参数是文件的路径,第2个参数是文件的分隔符,因为是csv文件,所以是逗号
print data
x=data[1:,:-1] #取所有行,前两列
y=data[1:,-1] #取所有行,最后一列
mlr=linear_model.LinearRegression() #调用线性回归模型
mlr.fit(x,y)
print mlr #
print "coef:"
print mlr.coef_ #模型中的参数预测,b1,b2....
print "intercept"
print mlr.intercept_ #模型中的参数预测,b0
xPredict=[90,2,0,0,1]
yPredict=mlr.predict(xPredict)
print"predict:"
print yPredict














 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









