







上一篇博客中,我们已经介绍了图像检索的原理与实现,这篇要介绍图像分类,什么是图像分类呢?图像分类就是输入一张图像,找到它属于哪一类。比如拍照识花,我们拍一张花的图像上传系统,然后系统就会告诉你这是什么花。那么图像分类是怎么怎么实现的呢?
一、KNN算法
1.算法概述
KNN(K-Nearest Neighbor,KNN)算法,又叫K最近邻分类算法,是著名的模式统计学方法。在分类方法中,KNN算法是最简单且用的最多的一种方法之一。
2.基本思想
KNN算法的基本思想是在特征空间中,如果要分类的对象(例如一个特征向量),在它的k个最近邻的已知对象中,大多数属于一个类别,则该要它也属于这个类别,并具有这个类别样本的特性。其基本思想示意图如下:
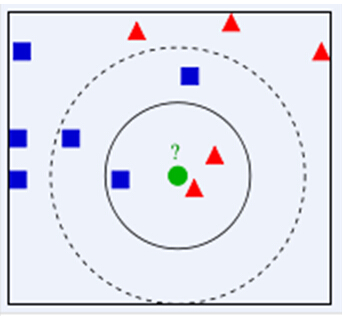
如图所示,已知红色三角和蓝色正方形都是已知对象,那么绿色圆圈属于哪一类呢?如果我们取K=1,我们可以很清楚的看见离它最近的是红色的三角,那么它就属于红色三角的那类;如果我们取K=5,在离它最近的5个已知对象中,有2个红色三角和3个蓝色正方形,蓝色正方形的数量大于红色三角的数量,所以它属于蓝色正方形。从这里我们也可以看到,K值的选取,对于分类的好坏起着至关重要的作用。K值过小,整体模型会变得复杂,容易过拟合;K值过大,会增加误差。
3.算法流程
KNN算法的流程如下:
- 输入训练数据和标签,输入测试数据,设置K值
- 计算测试数据与各个训练数据之间的距离(本文选取欧式距离,大家也可以选取其他距离)
- 按照距离的递增关系进行排序,选取距离最近的K个点
- 确定前K个点所在类别的出现频率,返回频率最高的那个类别作为测试数据的类别
4.算法的优缺点
KNN算法的优点:
- KNN可以用来做分类也可以用来做回归;
- 可用于非线性分类;
- 训练时间复杂度比支持向量机之类的算法低,仅为O(n);
- KNN与朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感;
- KNN方法主要靠周围有限个邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合;
- KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分;
- 特别适合于多分类问题(对象具有多个类别标签),KNN要比SVM表现要好。
KNN算法的缺点:
- 特征数比较多时,计算量很大;
- 样本各类别数量不平衡时,对稀有类别的预测准确率低;
- KD树,球树的模型建立需要大量的内存空间;
- 预测时需要现算预测点到训练集中所有点的距离,因此预测速度比逻辑回归算法要慢。
5.用KNN实现简单的二维数据分类
(1)随机生成二维的训练数据和测试数据
# -*- coding: utf-8 -*-
from numpy.random import randn
import pickle
from pylab import *
###生成数据
# 创建二维样本数据
n = 200
#两个正态分布的数据集
class_1 = 0.5 * randn(n,2)
class_2 = 1.5 * randn(n,2) + array([5,1])
labels = hstack((ones(n),-ones(n)))
#用Pickle模块保存
with open('points_normal.pkl', 'wb') as f:
#with open('points_normal_test.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
#正态分布,并使数据成环绕状分布
print ("save OK!")
class_1 = 0.5 * randn(n,2)
r = 1.0 * randn(n,1) + 5
angle = 2*pi * randn(n,1)
class_2 = hstack((r*cos(angle),r*sin(angle)))
labels = hstack((ones(n),-ones(n)))
#用Pickle模块保存
with open('points_ring.pkl', 'wb') as f:
#with open('points_ring_test.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
print ("save OK!")
根据上面的代码,运行两次,我们可以得到四个数据集,其中两个是训练集,两个是测试集,规模都是200,我们将前100个数据定义标签为-1,剩下的100个数据定义标签是1。两个训练集的不同之处在于一个是正态分布,另一个是环绕状分布。有个训练集和测试集,我们就可以用KNN来实现分类啦。
(2)KNN算法实现分类
# -*- coding: utf-8 -*-
import pickle
from pylab import *
from PCV.classifiers import knn
from PCV.tools import imtools
pklist=['points_normal.pkl','points_ring.pkl']
figure()
#用Pickle载入二维数据点
for i, pklfile in enumerate(pklist):
with open(pklfile, 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 用Pickle模块打开测试数据
with open(pklfile[:-4]+'_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
model = knn.KnnClassifier(labels,vstack((class_1,class_2)))
#在数据集的第一个数据点上进行测试
print (model.classify(class_1[0]))
#定义绘图函数
def classify(x,y,model=model):
return array([model.classify([xx,yy]) for (xx,yy) in zip(x,y)])
#绘制分类边界
subplot(1,2,i+1)
imtools.plot_2D_boundary([-6,6,-6,6],[class_1,class_2],classify,[1,-1])
titlename=pklfile[:-4]
title(titlename)
show()
上述代码,首先载入训练集和测试集,然后调用knn算法进行训练,其中K值默认为3,我们也可以根据自己的需要修改K值。最后根据测试结果绘制图像和边界。
knn算法的实现方法classify
ef classify(self,point,k=3):
""" 在训练数据上采用k近邻分类,返回标记 """
# 计算所有训练数据点的距离
dist = array([L2dist(point,s) for s in self.samples])
# 对他们进行排序
ndx = dist.argsort()
# 用字典存储k近邻
votes = {}
for i in range(k):
label = self.labels[ndx[i]]
votes.setdefault(label,0)
votes[label] += 1
return max(votes, key=lambda x: votes.get(x))该方法中,首先计算所有训练数据点距离测试点的距离,然后对距离按从小到大进行排序,统计前k个距离的训练测试点标签的频率,取频率最高的标签作为测试点的标签。
实验结果:

从结果图中,我们可以看到,左图中的蓝色类内有一个红色的点,说明这个点分类错误。从图中我们可以看出,这个点明显离蓝色类更近,但是却被标记为了红色,说明这个点很可能是噪声点,应该剔除。还有一种可能就是我们我们训练集规模不够大,训练的不够好,导致测试结果不够好。
二、dense SIFT算法
1.算法原理
在前面的博客中,我们已经讲过sift特征提取,SIFT特征是对整张图像进行处理,不能很好的表征不同类之间的差异,达不到所需分类要求。而Dense SIFT算法(稠密SIFT算法)是一种对输入图像分块处理,再进行SIFT特征提取的过程,可以根据可调参数,来满足不同分类任务下对图像特征表征能力。
dense sift算法与SIFT算法相比具有3个特点:
- 保持SIFT特征对尺度缩放、旋转以及亮度变化的不变性,对于视角变换、仿射变换以及噪声也具有一定的稳定性。
- 时间开销相对SIFT算法有一定的减少。
- 相对SIFT 特征点来说,分布更加均匀,提取的特征点更适用于图像拼接。
2.算法流程
(1)用一个patch块在图像中以step大小的步长滑动,自左到右、自上而下的计算每个patch块的SIFT特征
其中patch为窗体大小,是SIFT采样区域,step是patch移动的步长。其示意图如下图所示:
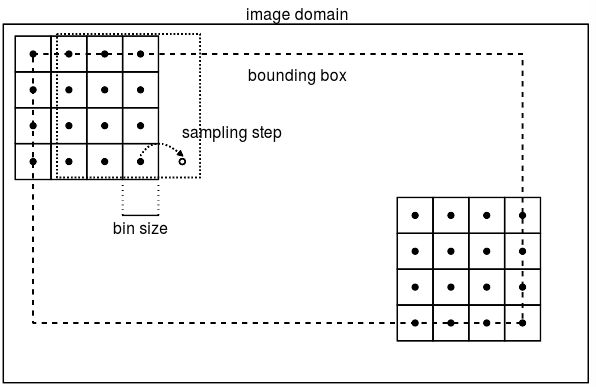
图中,patch大小是4bins*4bins.,其中bins大小可以自己修改,bounding box是SIFT特征点的范围。
(2)计算每个像素梯度(同sift),统计每个bin内的像素点在8个方向上的梯度直方图,这样就生成了4*4*8维的sift特征。

3.实现
# -*- coding: utf-8 -*-
from PCV.localdescriptors import sift, dsift
from pylab import *
from PIL import Image
dsift.process_image_dsift('gesture/eating.jpg','eating.dsift',40,20,True)
l,d = sift.read_features_from_file('eating.dsift')
im = array(Image.open('gesture/eating.jpg'))
sift.plot_features(im,l,True)
title('dense SIFT')
show()上述代码中我们设置patch大小为40,步长为20,结果如下:

接下来,我们修改patch大小10,步长为30,结果如下:

由上述两次结果对比可知,当patch越大时,sift特征提取的范围越大;当步长越大时,相邻两次sift特征提取的距离越远。
我们可以通过调节这两个参数的大小,来调节特征提取效果,这是分类的第一步。
三、图像分类:手写数字集识别
老师要求做手势识别的分类,但是我想到上学期有用到tenseflow进行手写数字集识别,所以我就把手势识别换成了手写数字集识别,我要作那不一样的烟火。
1.对图像进行Dense SIFT特征提取
# -*- coding: utf-8 -*-
import os
from PCV.localdescriptors import sift, dsift
from pylab import *
from PIL import Image
imlist=['gesture/train1/0-uniform02.ppm','gesture/train1/1-uniform01.ppm',
'gesture/train1/2-uniform01.ppm','gesture/train1/3-uniform01.ppm',
'gesture/train1/4-uniform01.ppm','gesture/train1/5-uniform01.ppm']
figure()
for i, im in enumerate(imlist):
print (im)
dsift.process_image_dsift(im,im[:-3]+'dsift',7,3,True)
l,d = sift.read_features_from_file(im[:-3]+'dsift')
dirpath, filename=os.path.split(im)
im = array(Image.open(im))
#显示手势含义title
titlename=filename[:-14]
subplot(2,3,i+1)
sift.plot_features(im,l,True)
title(titlename)
show()结果:

2.建立分类器进行手写数字集识别
(1)提取所有训练数据的dsift特征
(2)根据训练数据及其标记作为输入,创建分类器
(3)遍历整个测试集进行分类,并计算分类的正确率。
# -*- coding: utf-8 -*-
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
def get_imagelist(path):
""" Returns a list of filenames for
all jpg images in a directory. """
return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.ppm')]
def read_gesture_features_labels(path):
# 对所有以.dsift为后缀的文件创建一个列表
featlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.dsift')]
# 读取特征
features = []
for featfile in featlist:
l,d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
# 创建标记
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features,array(labels)
def print_confusion(res,labels,classnames):
n = len(classnames)
# confusion matrix
class_ind = dict([(classnames[i],i) for i in range(n)])
confuse = zeros((n,n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]],class_ind[test_labels[i]]] += 1
print ('Confusion matrix for')
print (classnames)
print (confuse)
filelist_train = get_imagelist('gesture/train')
filelist_test = get_imagelist('gesture/test')
imlist=filelist_train+filelist_test
# 将图像尺寸调为(50,50),然后进行处理
for filename in imlist:
featfile = filename[:-3]+'dsift'
dsift.process_image_dsift(filename,featfile,10,5,resize=(50,50))
features,labels = read_gesture_features_labels('gesture/train/')
test_features,test_labels = read_gesture_features_labels('gesture/test/')
classnames = unique(labels)
# 测试KNN
k = 1
knn_classifier = knn.KnnClassifier(labels,features)
res = array([knn_classifier.classify(test_features[i],k) for i in
range(len(test_labels))])
# 准确率
acc = sum(1.0*(res==test_labels)) / len(test_labels)
print ('Accuracy:', acc)
print_confusion(res,test_labels,classnames)
本次实验中,选用mnist手写数字集,共有0-5六个分类,每类约有30个训练集和30个测试集:实验结果如下:
(1)第一次实验结果:
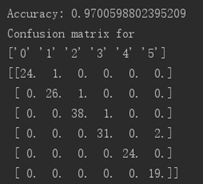
此次结果的准确率达到0.97,说明训练效果已经很好了。我们看混淆矩阵中,主对角线为正确分类的个数,其余为误判。有一个“1”被误判成0,一个“2”误判为1,一个“3”误判为2,两个“5”误判为3.
(2)第二次实验结果(将训练集和测试集互换):
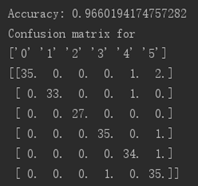
此次结果的准确率达到0.96,说明训练效果也已经很好了。我们看混淆矩阵中,主对角线为正确分类的个数,其余为误判。有一个“4”被误判成0,一个“4”误判为1,两个“5”误判为0,一个“5”误判为3,一个“5”误判为4.
(3)自己手写

上面是我自己手写的数字,有一些故意写的难易辨认,就是为了增加干扰项。
测试结果:

上面两个测试结果正确率都在90%以上,高到怀疑人生,所以我自己写了几个数字测试了一下。不出所望,正确率终于降到了0.62,这也有我故意写的难易区分的原因。我们看混淆矩阵中,主对角线为正确分类的个数,其余为误判。有一个“0”被误判成4,一个“0”误判为5;一个“1”误判为3,一个“1”误判为4;三个“2”误判为4,这比正确的个数还要高;一个“3”误判为2;两个“5”误判为3。错误率提高的原因是我们训练的不够好,一个原因是我们dsift选取的patch大小和步长参数没有设置好,另一个原因是我们训练数据过少,每类才30个左右,而且没有包含相似性,导致错误率提高。
参考:
https://blog.csdn.net/zgcr654321/article/details/85219121
https://blog.csdn.net/qq_38554218/article/details/83042189
https://blog.csdn.net/langb2014/article/details/48738669















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









