






引言
早期网络强调追踪时空中感兴趣的目标,虽然快速,简单,但是容易忽略低级的线索(角和高强度峰值)。随着高性能检测器的出现,便出现先检测后追踪模式,将检测和追踪分为两步:首先在每帧中找到所有目标,然后追踪的任务就变成了一个边界框关联。因为给定了检测的结果,只需要关注如何将相同的目标连接起来(轨迹)即可。但是大多数的关联策略都是复杂的,高计算量的。
本文提出了一种基于点的联合检测和跟踪框架,称为CenterTrack,每个对象都由其边界框中心的单个点表示,然后通过时间跟踪这个中心点,如图1所示:

作者使用CenterNet检测器来定位对象中心,将检测器设置在两个连续的帧上,以及用点表示的先验轨迹的热图上。训练的检测器也输出一个从当前对象中心到它在前一帧的中心的偏移向量,这个偏移量作为中心点的一个属性,只需要一点点额外的计算成本,仅仅基于这个预测偏移量和前一帧中检测到的中心点之间的距离的一个贪婪的匹配,就足以实现对象关联。跟踪器是端到端的可训练和可微的。
这种方法简化了跟踪条件检测和对象间的时间关联,CenterTrack纯粹是局部的,它只关联相邻帧中的对象,而不重新初始化丢失的远程轨迹,它以换取简单、快速和高精度。
相关工作
Tracking-by-detection:
大多数的跟踪算法都是基于这种思想,一个检测器首先找到每一帧中的所有物体,那么跟踪就是一个边界框关联的问题,使用卡尔曼滤波器对跟踪边界盒进行排序,并使用二部匹配将每个边界盒与其当前帧中的最高重叠检测关联起来。最近的方法侧重于增加对象关联的健壮性,《Multiple people tracking by lifted multicut and person re-identification》利用了人再识别特征和人体姿势特征。《Spatial-temporal relation networks for multi-object tracking》随着时间的推移利用了空间位置。《Beyond pixels: Leveraging geometry and shape cues for online multi-object tracking》使用额外的3D形状信息来跟踪车辆。
不过这种方法有两个缺点:①数据关联的时候直接放弃了图片外观特征或者需要极大的计算力来进行特征提取②检测与跟踪分离。
Joint detection and tracking:
多目标跟踪的一个最新趋势是将现有的检测器转换为跟踪器,并在同一框架中结合这两个任务。
《Detect to track and track to detect》使用siamese网络,以当前和过去的帧作为输入,并预测边框之间的帧间偏移量。《Integrated object detection and tracking with tracklet-conditioned detection》使用跟踪的边界盒作为额外的区域建议来增强检测,其次是基于双方匹配的边界盒关联。《Tracking without bells and whistles》通过使用边界框回归直接传播区域建议的标识来移除框关联。在视频对象检测方面,《Object detection in videos with tubelet proposal networks》将堆叠的连续帧送入网络,对整个视频段进行检测。《Flow-guided feature aggregation for video object detection》使用流来扭曲之前帧的中间特征,从而加速推理,本文方法提供了跟踪预测作为额外的基于点的热图输入到网络。然后,这个网络就能够推理和匹配接收域中任何地方的对象,即使这些box根本没有重叠。
Motion prediction:
运动预测是跟踪系统的另一个重要组成部分。早期的方法使用卡尔曼滤波器来建模物体速度。《Learning to track at 100 fps with deep regression networks》使用回归网络来预测帧间边框偏移的四个标量,用于单目标跟踪。《Simple baselines for human pose estimation and tracking》利用光流估计网络更新人体姿态跟踪中的关节位置。《Mots:Multi-object tracking and segmentation》学习高维嵌入向量的目标身份,同时目标跟踪和分割。本文方法类似于稀疏光流,它是与检测网络一起学习的,不需要密集的监督。
Heatmap-conditioned keypoint estimation:
关键点的热图(《Human pose estimation with iterative error feedback》、《Learning to refine human pose estimation》、《Posefix: Model-agnostic general human pose refinement network》、《Auto-context and its application to high-level vision tasks》在跟踪中特别有吸引力,原因有二:首先,前一帧中的信息是免费可用的,并且不会减慢检测器的速度。第二,条件跟踪可以推理出在当前帧中可能不再可见的遮挡对象。跟踪器可以简单地学习从周围的前一帧保存这些检测。
3D object detection and tracking:
3D跟踪器用单目图像或3D点云的3D检测代替了标准跟踪系统中的目标检测组件,然后跟踪使用现成的身份关联模型。例如,3DT检测2D边界框,估计3D运动,并使用深度和顺序线索进行匹配。AB3D通过结合卡尔曼滤波器和精确的3D检测[37],实现了最先进的性能。
方法
CenterTrack中将跟踪看做一个从局部角度观察的问题,比如当一个目标离开画面或被遮挡又重新出现时,跟踪模型不会记住它,而是会重新给它分配一个新的ID. 因此,CenterTrack将跟踪建模成了一个在连续帧之间传递检测结果ID的问题
存在有两个挑战:一是如何在每一帧中找出所以的对象,甚至包含被遮挡的对象;二是如何在时间上为这些对象建立联系。
Tracking-conditioned detection;
作为一个检测器,CenterNet已经能够给出跟踪所需的很多信息,如位置、大小和得分。但是它不具备预测未直接出现在当前帧的目标的功能,所以在CenterTrack中,将当前帧及其上一帧图像共同输入模型当中,旨在帮助网络估计场景中对象的变化并根据上一帧图像提供的线索恢复当前帧中可能未观察到的对象。此外,CenterTrack还将上一帧图像的检测结果添加到输入中,具体做法是根据上一帧的检测结果绘制一张单通道heatmap,其中peak位置对应目标中心点,并使用与训练CenterNet过程中相同的高斯核渲染办法(根据目标大小调整高斯参数)进行模糊处理,为了降低误报概率,作者只对检测结果中得分高于一定阈值的目标进行渲染(即得分低的目标不会体现在新生成的heatmap上)。CenterTrack的架构如图2所示:

Association through offsets:
为了能够在时间上建立检测结果直接的联系,CenterTrack添加了2个额外的输出通道,用于预测一个2维的偏移向量,即描述的是各对象在当前帧中的位置相对于其在前一帧图像当中的位置的X/Y方向的偏移量。此处的训练监督方式与CenterNet中对目标对象长宽或中心偏移情况的部分训练方式相同。本文使用与大小或位置细化相同的回归目标来学习这个偏移量:
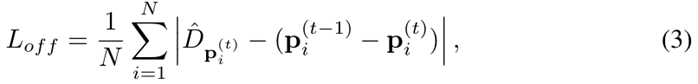
有了足够好的偏移量预测,一个简单的贪婪匹配算法可以跨时间关联对象。
Training on video data:
CenterTrack本质上也是一个检测器,所以其训练方法也和训练CenterNet类似,也就允许可以从一个预训练好的CenterNet上微调出一个CenterTrack。具体做法是,首先根据常规做法,在当前视频数据上训练一个CenterNet模型,然后从它当中拷贝所有权重,并为新添加的部分结构进行随机初始化参数,而后遵循CenterNet的训练方法进行训练,并且额外加上对偏移量分支的监督。
在训练CenterTrack过程中一个最主要的挑战是如何生成一张接近真实情况的tracklets heatmap的问题:在模型推理期间,tracklets heatmap是根据模型预测结果渲染而来的,可能会存在数量不定的missing tracklets、错误定位的目标以及还可能有误检的目标存在。而这些情况在Ground Truth中是不存在的,也就是说如果我们直接利用基于Ground Truth渲染出的heatmap,是无法模拟这种实际情况的,也就会导致模型效果不佳。
在实践中,先前帧不需要是前一个帧,它可以是同一视频序列的不同帧。本文实验中,在t附近随机采样帧,以避免帧速率过拟合。
Training on static image data:
如果没有带标注的视频数据,我们还可以标准检测基准上模拟跟踪,通过随机缩放和变换当前图像,来模拟生成先前帧,从而达到模拟目标运动的目的。实验证明这一trick很有效,几乎不会影响跟踪模型的效果。
End-to-end 3D object tracking:
为了实现单摄像头3D跟踪,采用CenterNet的单摄像头3D检测形式,具体来说,使用输出头预测目标的depth、 rotation和3D extent。
实验
在MOT17和KITTI跟踪基准上评估2D多目标跟踪,在nuScenes上评估3D跟踪。评价指标2D用MOTA和IDF1;3D用AMOTA。实验基于CenterNet,使用DLA作为网络backbone,优化器使用学习率为1,25e-4的Adam,batchsize为32。数据增强使用随机水平翻转,随机大小裁剪和颜色抖动。
在MOT上的测试比较结果如表1:

在KITTI上的比较结果如表2:

在nuScenes上的比较结果如表3所示:

消融实验如表4-6所示:



总结
在Tracking-by-Detection里,MOT的跟踪时间是检测的时间加上关联追踪的时间,JDE是将embedding和检测结果一起输出,但还是需要再进行关联操作,相当于两个阶段。本文提出的CenterTrack基于CenterNet,合并检测与匹配阶段,依靠预测的偏移量和上一个帧中检测到的中心点之间的距离进行对象关联。CenterTrack网络需要三个输入,当前帧和前一帧的图片,以及前一帧中物体中心分布的热力图,最后得到四个输出:检测框中心点位置分布热力图、相关点为前景中心的置信度图、点对应的检测框的宽高、检测框中心点在前后帧的位移。这篇论文和FairMOT都利用到了热力图。














 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









