






目录
简介
使用此云服务器的优势
- 学生认证,省钱
- 可无卡模式启动,省钱
- 上传数据比较方便
使用流程
租借
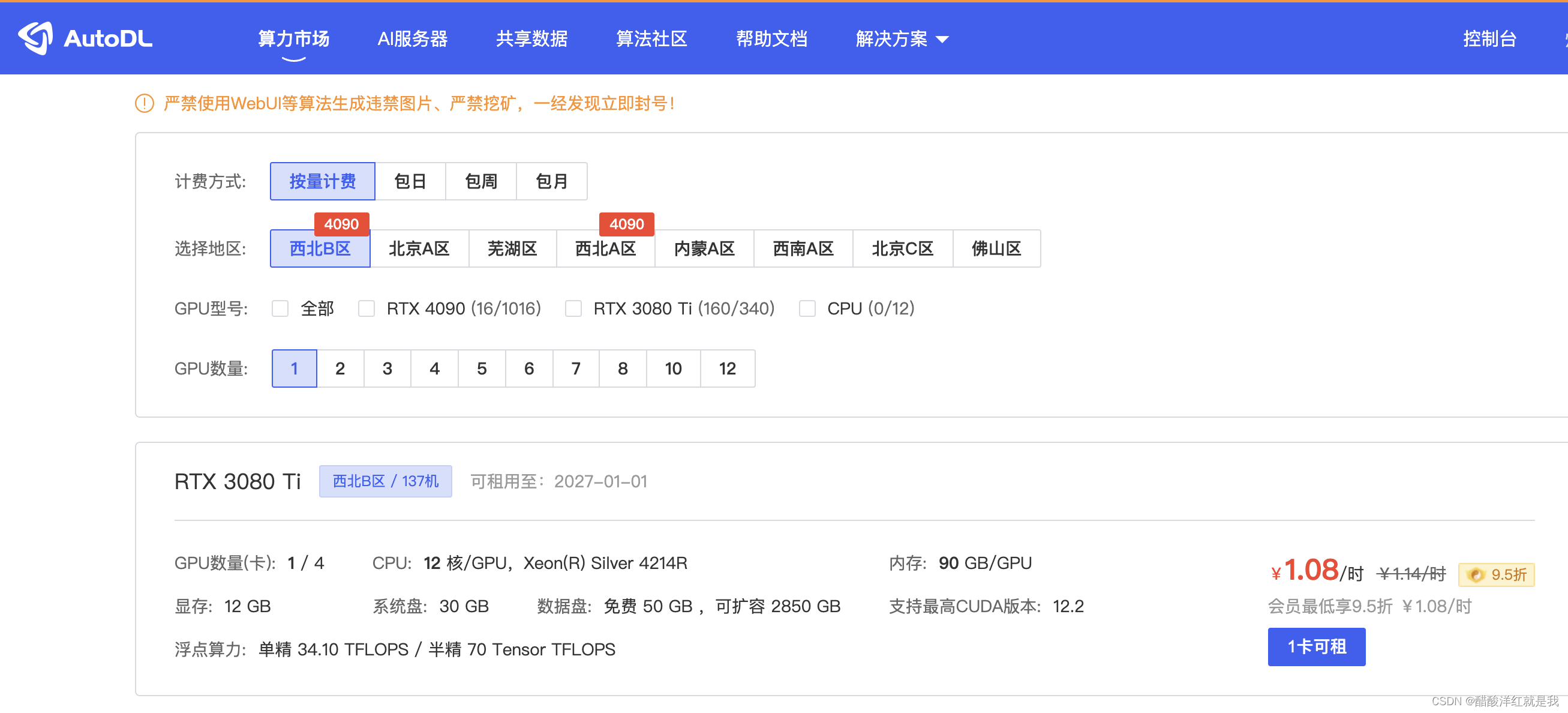
进入算力市场,选择适合自己的任务的GPU进行租借,租借成功会显示登录指令和密码

连接服务器
我是使用pycharm进行连接
注意:只有pycharm专业版才支持ssh连接方式,社区版不支持
在pycharm中按ctrl+,(mac为command+,)调出python解释器,在右边添加解释器中点击SSH
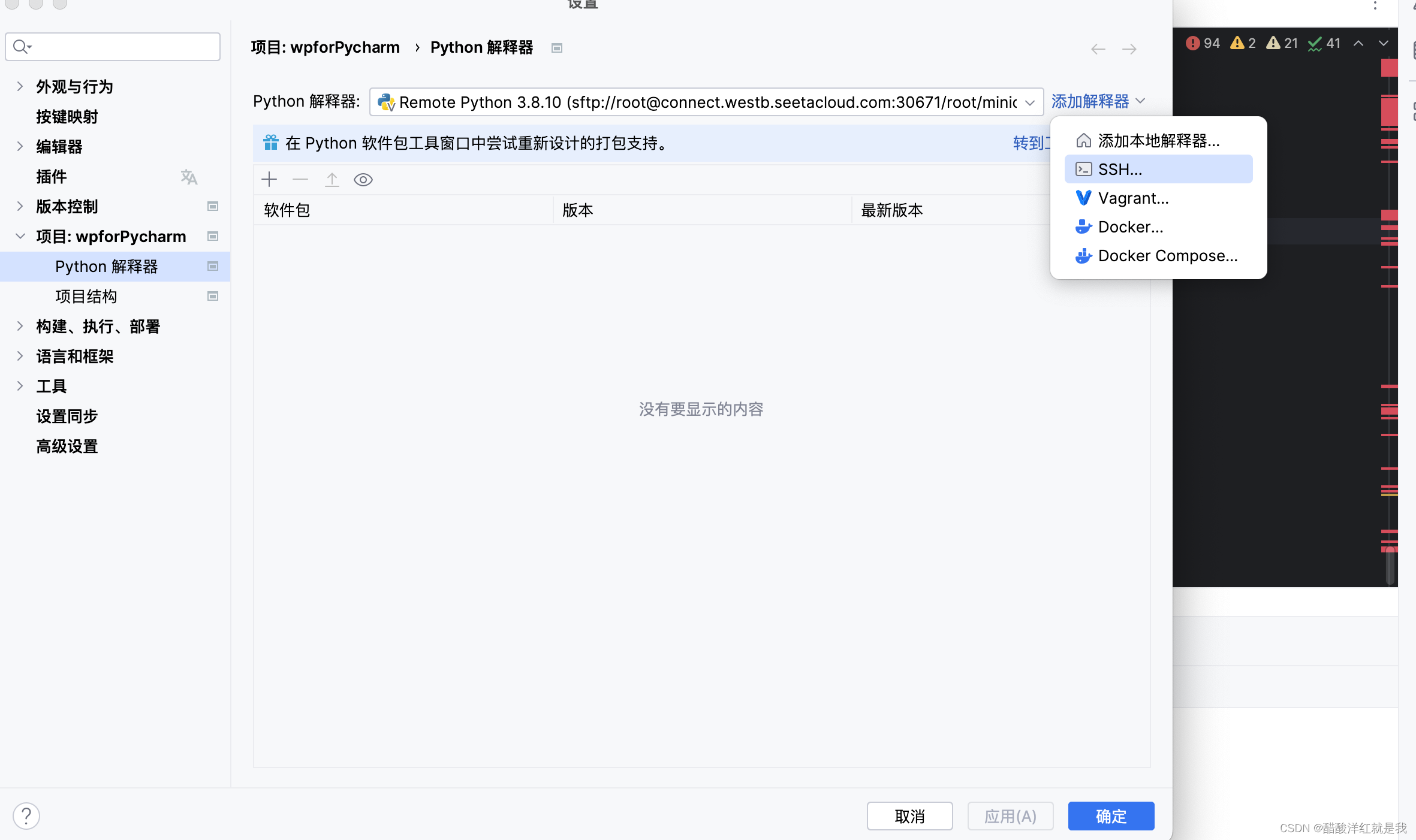
输入登录指令以及密码
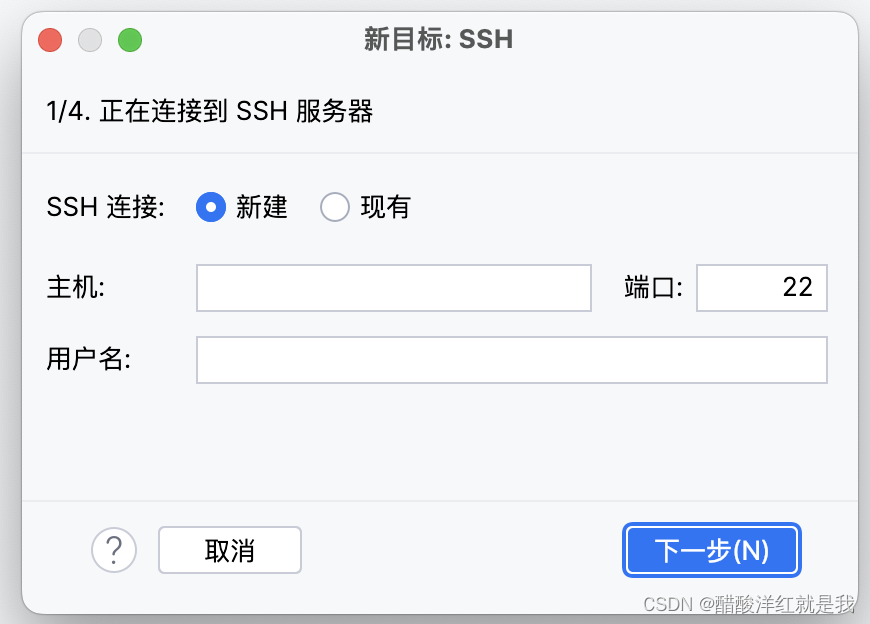
登录指令解析
ssh -p 22337 root@connect.westb.seetacloud.com
其中22337是端口号,主机为删除ssh -p 22337 root@后的内容,用户名为root
输入后再将密码输入即可
设置服务器环境和同步文件
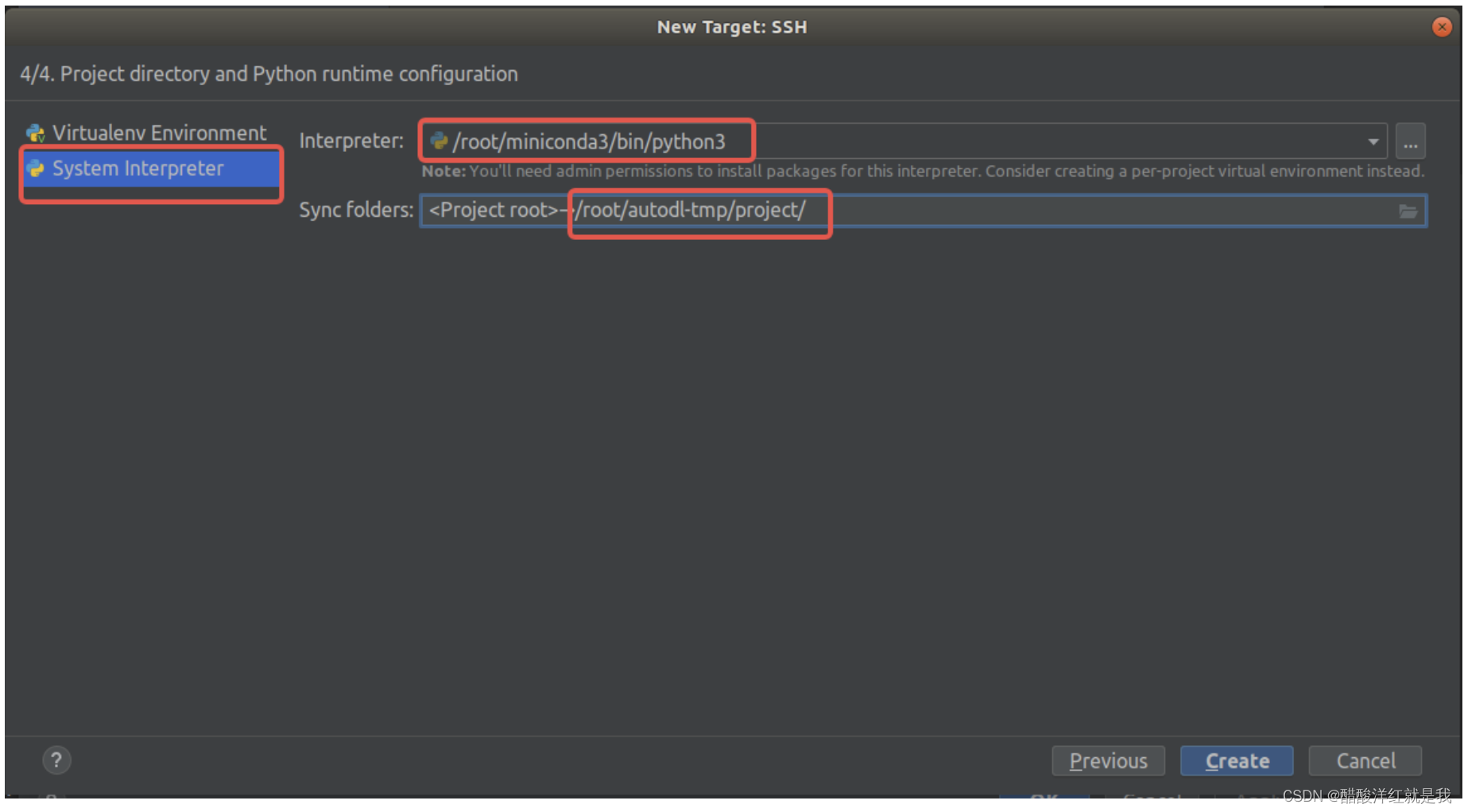
点左边第二个,然后第一个选择如图所示的解释器,第二个为同步位置(本地文件夹与云服务器端文件夹),建议服务器端使用/root/autodl-tmp/下的文件
此时就连接完成
使用技巧
查看远程主机资源
上传下载数据
见官方文档,我是用百度云盘的方法,比较方便和快捷
网站
解压和压缩详见autodl帮助文档中(数据——压缩/解压或最佳实践——Linux基础——压缩和解压)
解压
我的习惯是打开云服务器端的Jupyter lab,然后运行终端,安装解压工具
# 下载安装工具
curl -L -o /usr/bin/arc http://autodl-public.ks3-cn-beijing.ksyun.com/tool/arc && chmod +x /usr/bin/arc
然后通过cd指令进入到需要解压的地方中,输入解压指令
# 解压
arc decompress xxx.zip
或者解压到指定目录
arc decompress xxx.zip path/to/directory
压缩
# 压缩/打包
arc compress xxx.zip path/to/directory
使用pycharm连接autodl中的Jupyter lab运行
首先同步文件
在pycharm中建立一个含有Jupyter notebook文件,然后与服务器一个文件夹进行同步
运行单元格
会报一个错,然后进入终端安装
pip install -U "jupyter-server<2.0.0"
修改文件
先运行如下代码生成配置文件
jupyter notebook --generate-config
然后vim打开并修改代码(按a是插入,然后ESC退出编辑模式,输入:wq加回车键退出)
vim /root/.jupyter/jupyter_notebook_config.py
修改如下地方
#c.NotebookApp.allow_root = False ,将该行注释去掉,参数改为True
绝对路径和相对路径
服务器端
服务器端的路径pwd为jupyter文件所在的位置
pycharm端
pycharm端的路径pwd为一个tmp文件夹,需要将读入的数据写为绝对路径,例如
root='/root/VOC2012'
也就是root打头
也就是说最好在服务器端也写成绝对路径,就不会出现这个问题了
我的心得
将大文件用百度云盘上传,小文件通过同步区域上传
在使用时,我习惯将checkpoint和dataset通过网盘上传到云端,然后再连接服务器,将剩下的代码放入同步区域
跨实例拷贝数据
在当前实例中选择,选的是被拷贝的实例(源实例),拷贝入的实例(目标实例)需要是开机状态(也就是不需要的关机并点更多选择跨实例拷贝数据,需要用的开机后不用点它)
如果本实例没GPU选择其他实例
通过跨实例拷贝数据拷贝数据盘的内容(也就是代码和数据),环境的话使用保存镜像和更换镜像实现
训练周期长的话使用Jupyter Lab里的终端跑
懂得都懂
运行完代码自行关机
终端里输入
python train.py && /usr/bin/shutdown
使用tensorboard查看训练情况
autodl提供了接口,只需要指定写入地址为/root/tf-logs/
以下是一段简短代码
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter('/root/tf-logs/')
total_loss=0
for epoch in range(max_epoches):
for iteration, data_batch in enumerate(train_loader):
#...
total_loss+=loss.item()
writer.add_scalar('Loss/train',total_loss/64,epoch)
writer.close()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











