






流程
- 修改模块地址
- 打包项目
- 上传到kaggle Datasets
- 创建code文件,导入数据与项目
- 粘贴train.py文件,调整超参数,选择GPU
- save version,后台训练
- 查看训练结果
详细步骤
打开kaggle网站,点击dataset下的new dataset上传项目,如果使用的是自己的数据集,也需要一并上传(传打包好的)
然后进入code代码区,创建一个notebook
点击右边的add data,选择刚才上传的项目
再将原本项目的train文件下的代码复制粘贴到上图中的代码区,但需要做如下修改
- 文件开头加入如下代码
import sys
sys.path.append('../input')
- 导包的时候需要改成当前路径
#例如
#原本
from net import vgg16,vgg16_bn
#现在
from yolov1.yolov1.net import vgg16,vgg16_bn
- 代码里使用的本地地址也需要更改成kaggle里的地址
最后选择GPU或者TPU来运行
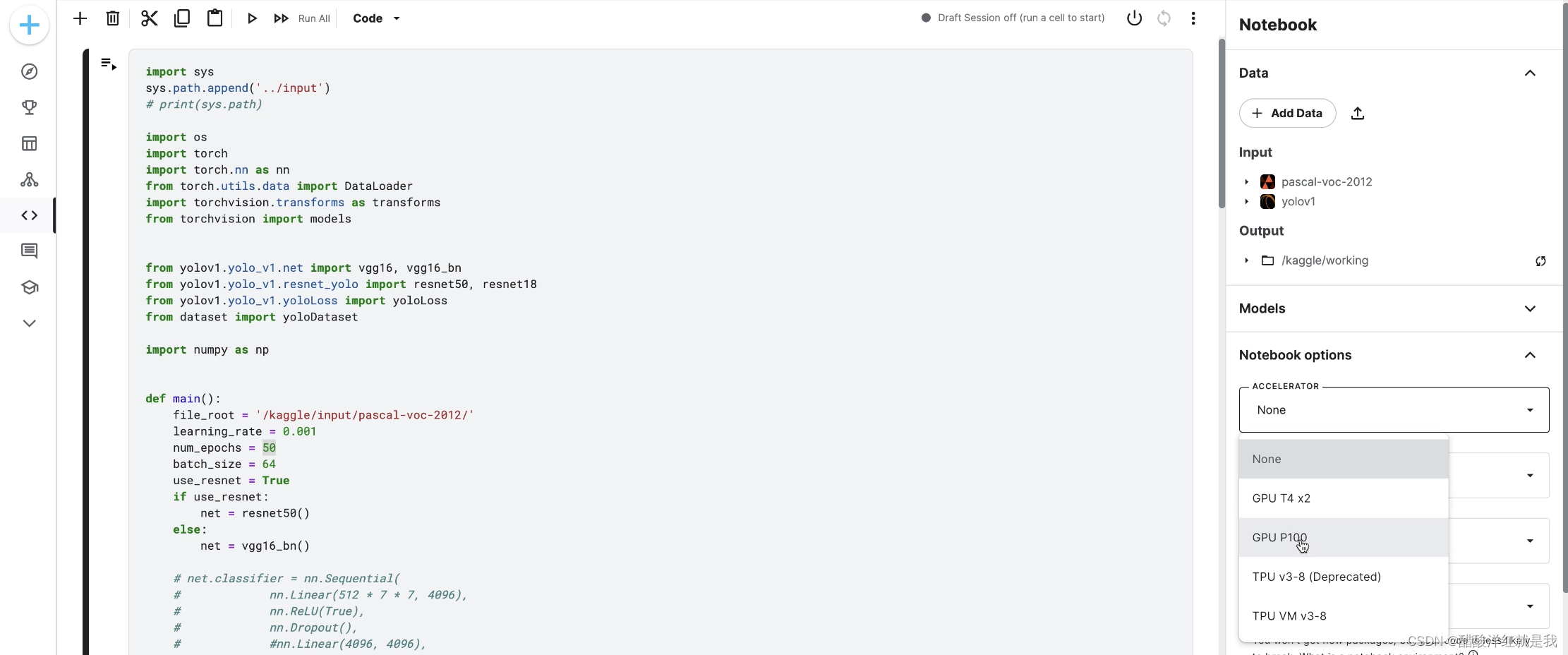
要放到后台运行,点击右上角的save version,具体原因见最后
注意事项
- 每周30个小时GPU+20小时TPU
- 每个用户最多同时使用一个GPU
- 不提交使用后台运行的话,1小时掉线一次
- 提交后台运行,最多使用6小时,结果可保存


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











