









一篇文章讲清楚如何DeepSeek本地部署,解决下载慢问题
已经测试机型:
| 显卡 | 模型效果 |
|---|---|
| 1050~1050Ti | 1.5b的最好 |
| 1650 | 7b用多了会卡 |
| 3090ti | 14b稳稳拿捏 |
| 4090 | 32b轻松拿捏 |
| 4090 | 70b报错cuda问题 |
安装Ollama
Ollama地址
安装Ollama
- Ollama没有选择安装地址,默认装在C盘,后期下载AI模型也会下到C盘,不建议用默认安装,想装到别的盘的话请看下方
- 在D盘创建一个文件夹随便起名字就可以
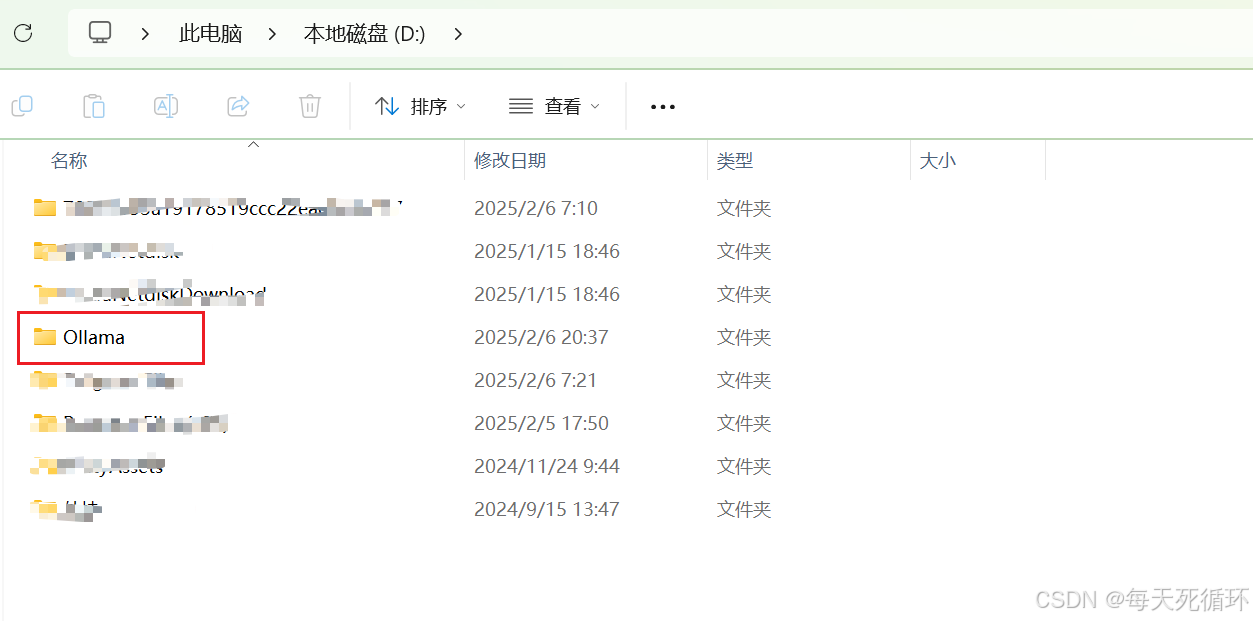
- 点住Shift键然后右键选择在终端打开
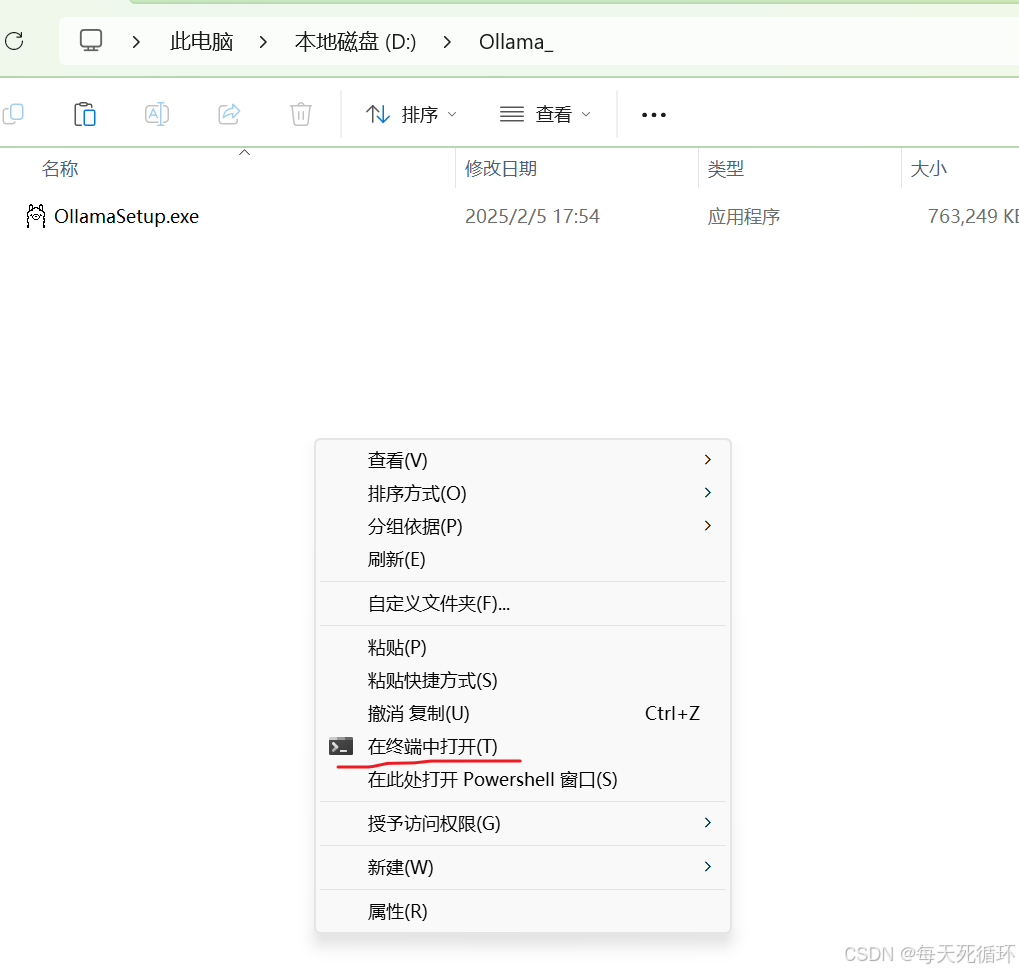
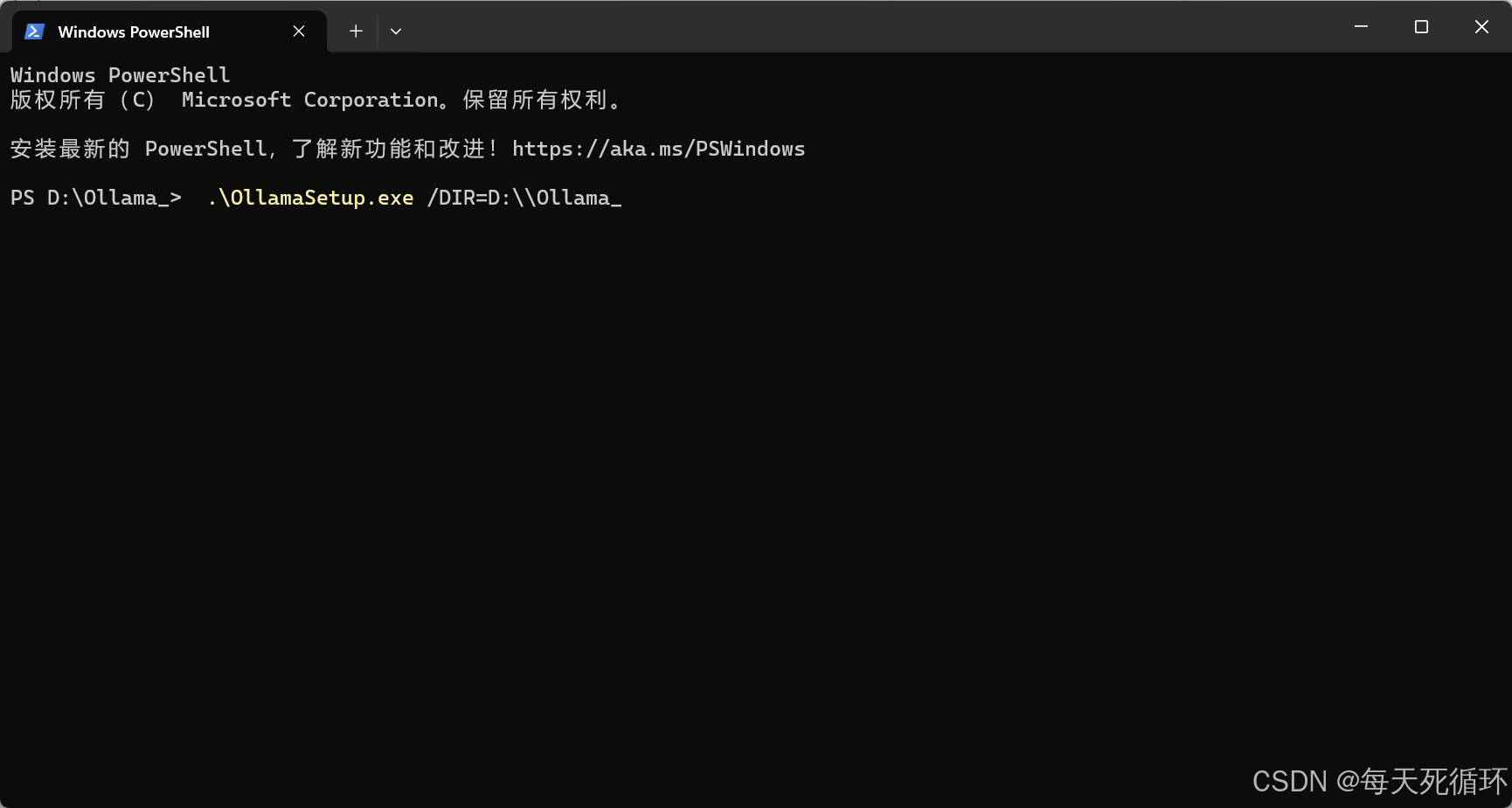
- 输入 “.\OllamaSetup.exe /DIR=D:\Ollama_”,然后点击回车键
- 解释:“.\OllamaSetup.exe /DIR=” 这个命令用于显示当前目录中的文件和子目录的列表,ollama安装到这个**“D:\Ollama_”*目录里面
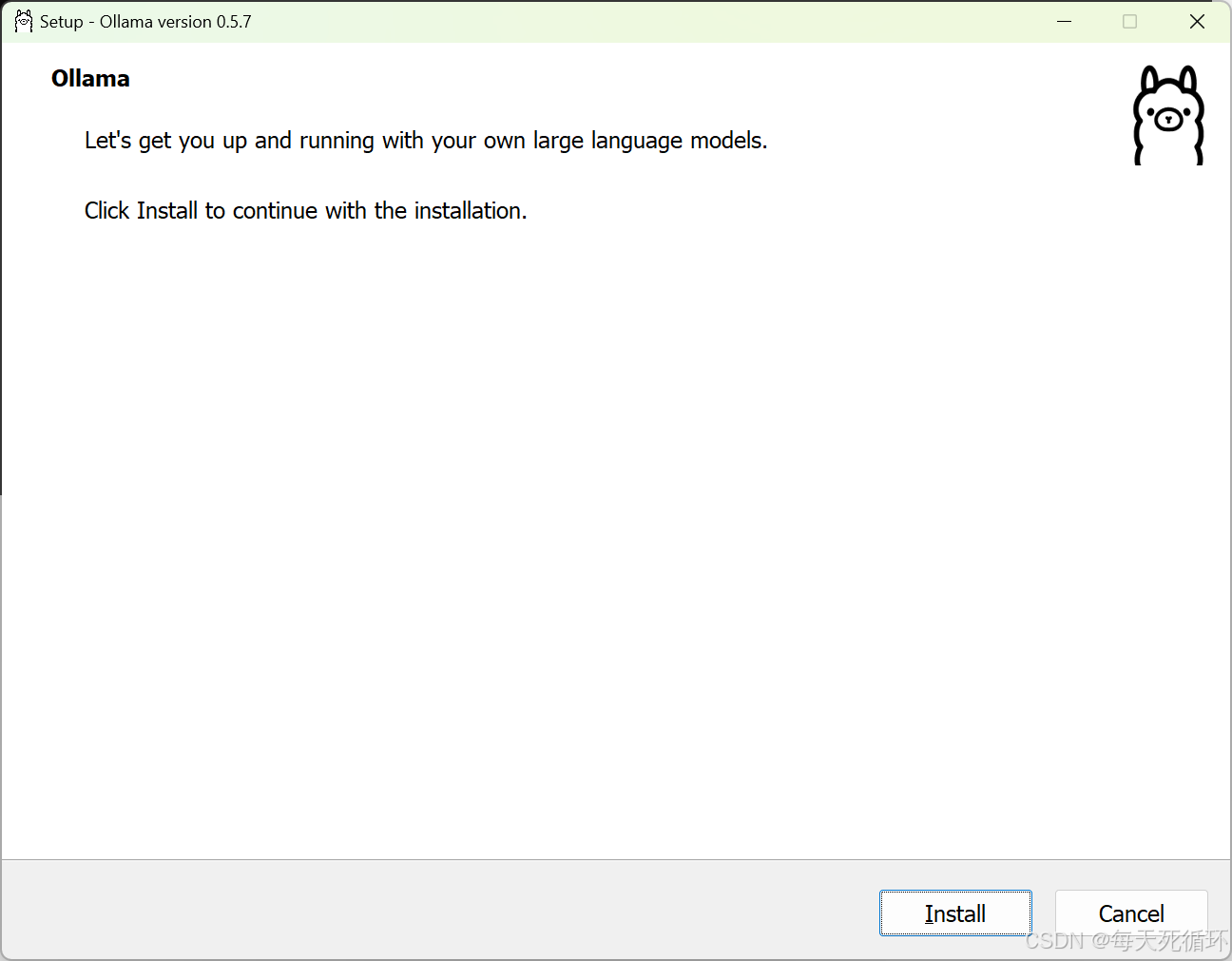
- 出现以下界面说明成功了,点击Install开始安装
安装webUI
- 下载Page Assist,在谷歌商店里面查找Page Assist 点我下载安装
2.安装成功之后记得点上固定
3.然后点击ollama
4.进入到这个页面之后查看
5.设置中文
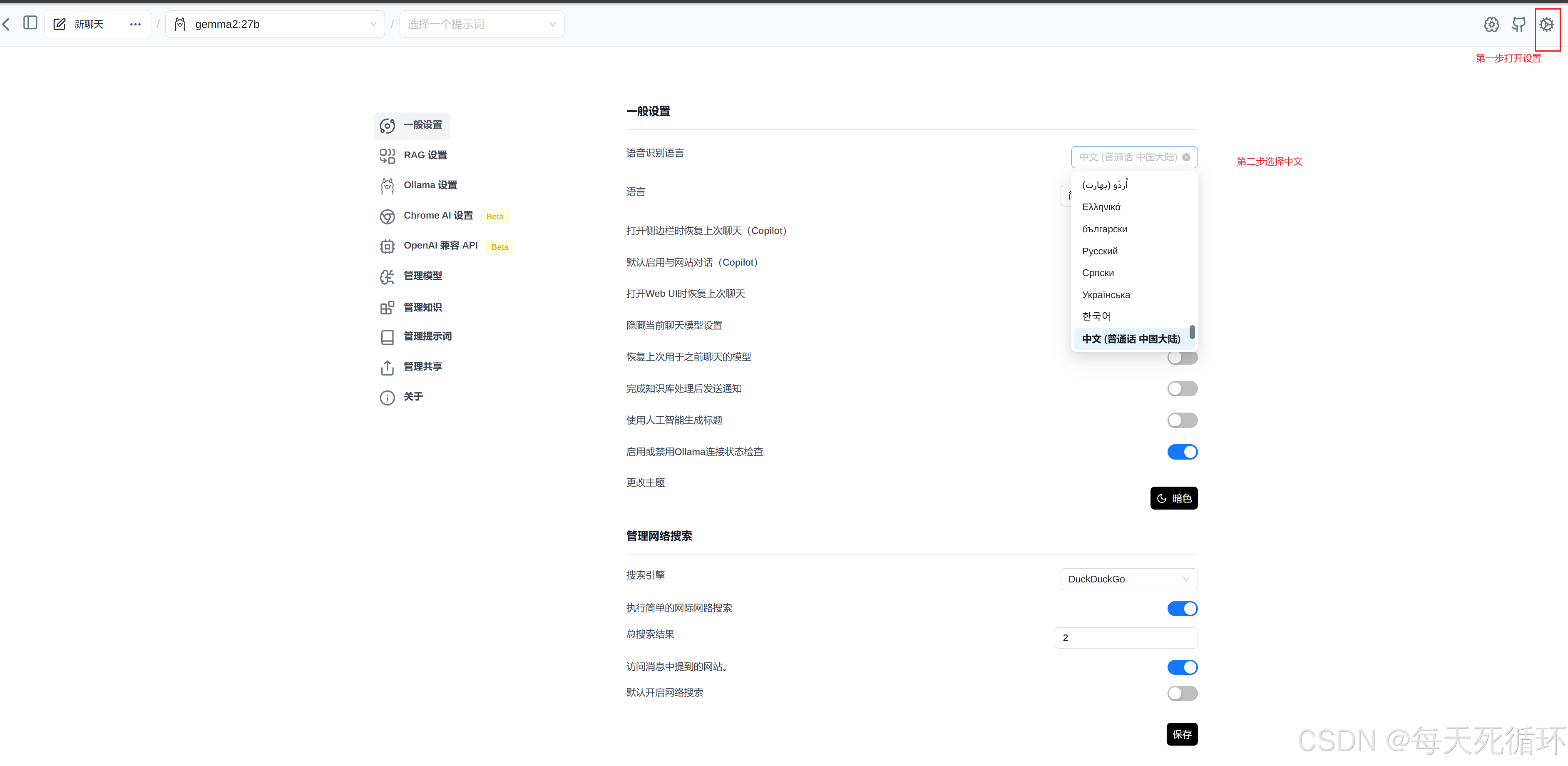
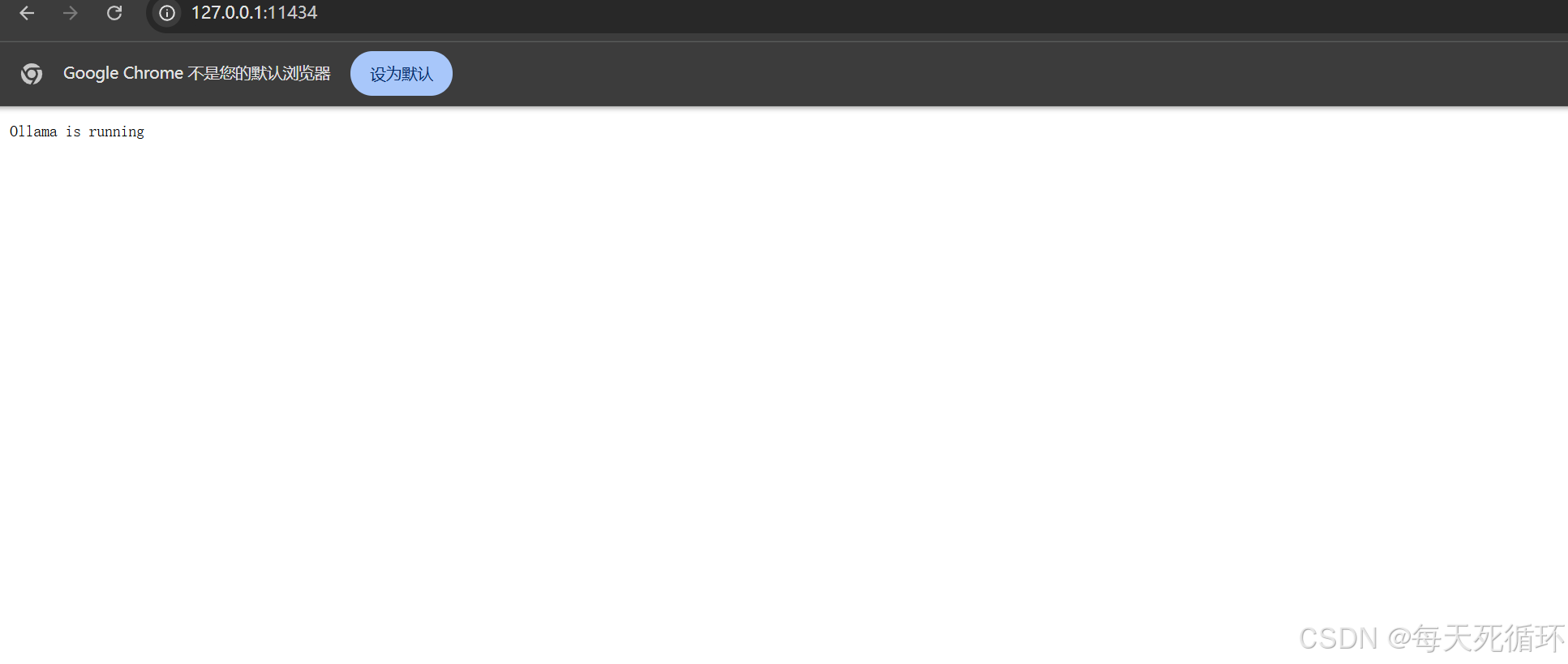
6.测试ollama是否正常访问这个链接 http://127.0.0.1:11434,ollama的端口号是11434,后面我们做成局域网会用到
修改DeepSeek模型或者其他AI模型存放位置
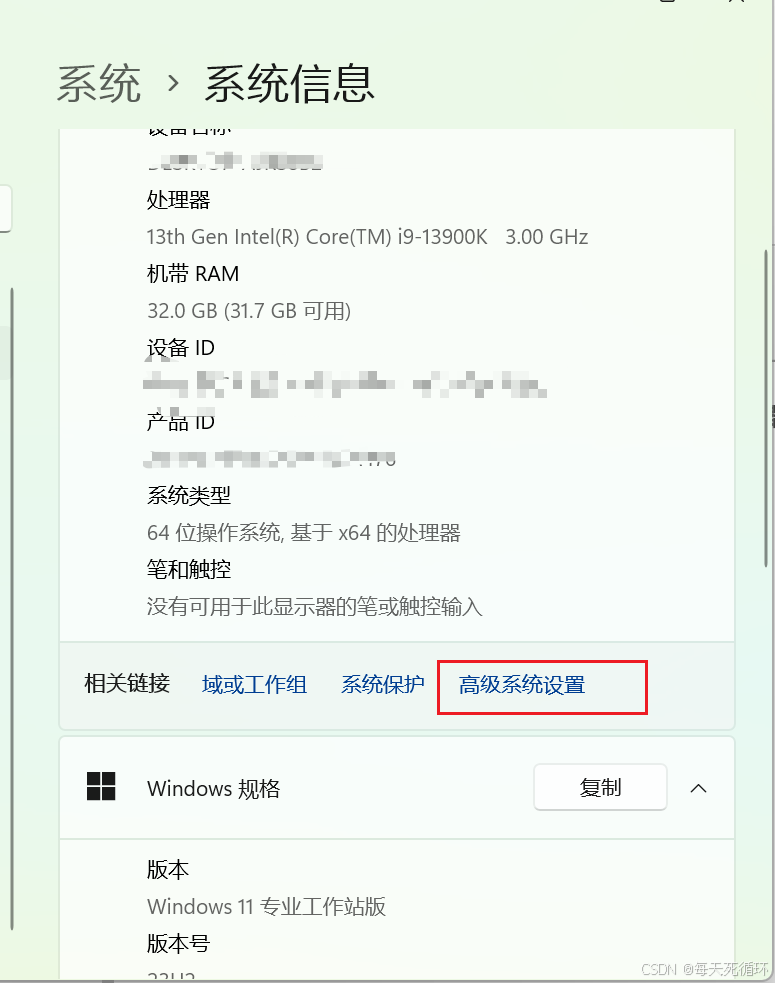
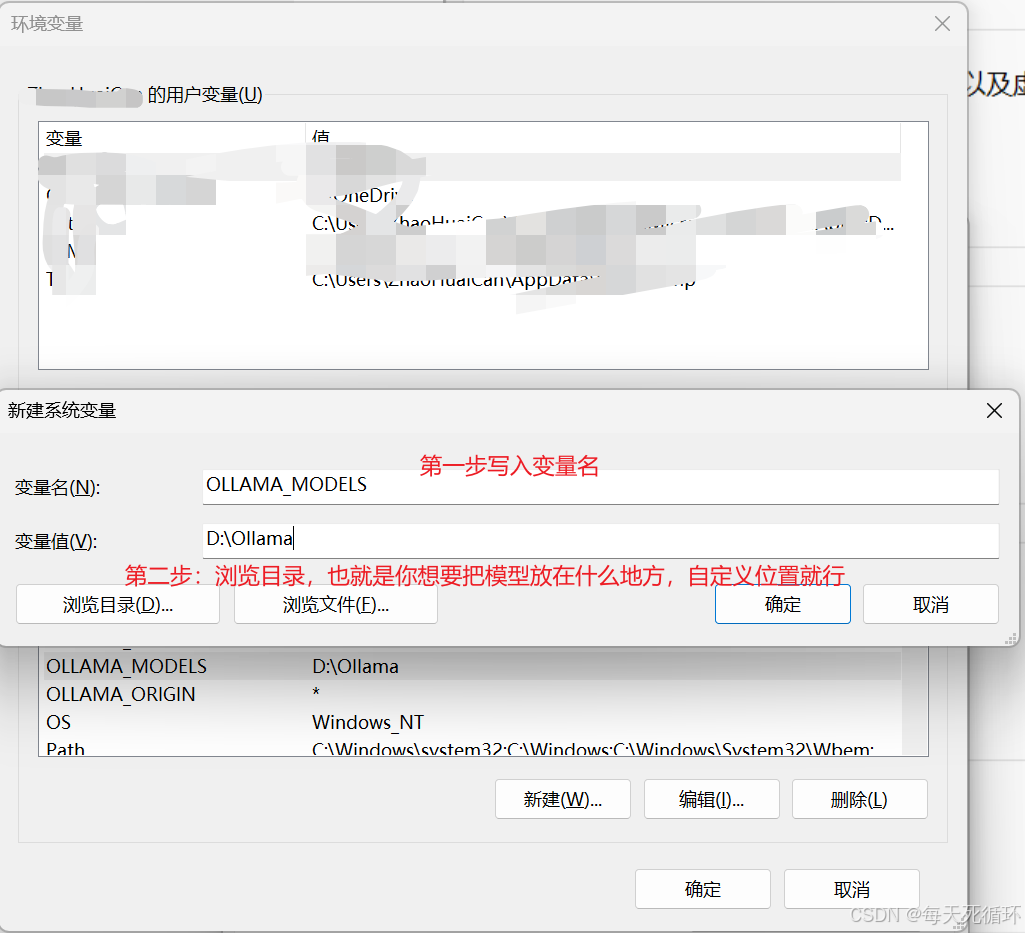
- 安装成功之后,默认AI模型放到C盘/user/.Ollama这个路径里面,不过我们要修改模型安装位置,点击高级系统设置
- 点击环境变量
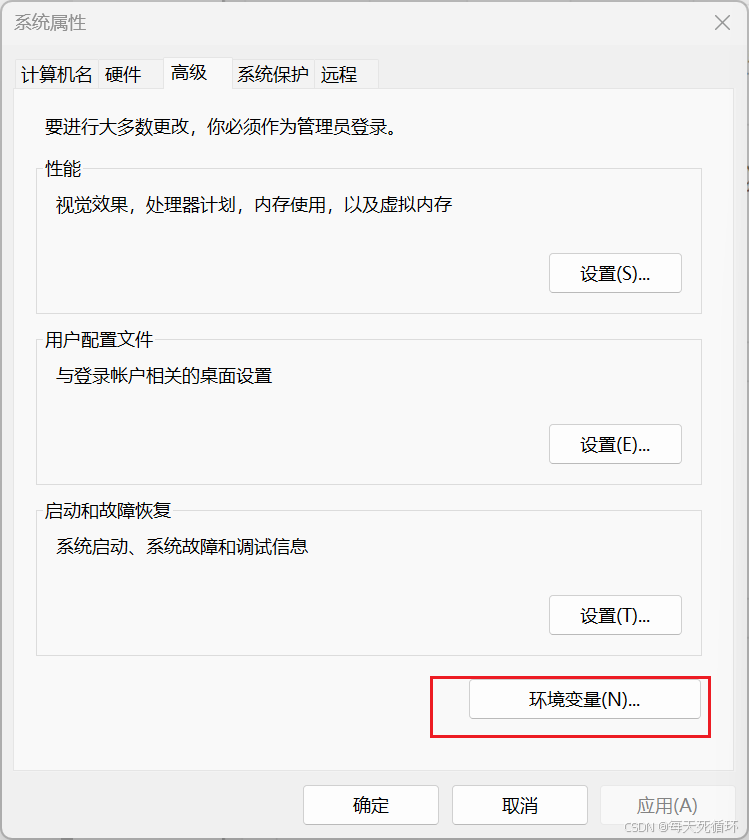
- 点击新建环境变量,写入OLLAMA_MODELS,然后浏览目录写入变量值也就是你要存在什么位置,输入成功之后,点击确定,然后在点击确定依次点击然后就设置模型位置成功了,重启电脑!重启电脑!。
下载模型
1.打开命令提示符,选择模型,进行下载,下面是每个模型的命令行
| 下载模型命令行 | 模型占用内存 |
|---|---|
| ollama run deepseek-r1:1.5b | 1.1GB |
| ollama run deepseek-r1:7b | 4.7GB |
| ollama run deepseek-r1:8b | 4.9GB |
| ollama run deepseek-r1:14b | 9.0GB |
| ollama run deepseek-r1:32b | 20GB |
| ollama run deepseek-r1:70b | 43GB |
| ollama run deepseek-r1:671b | 404GB |
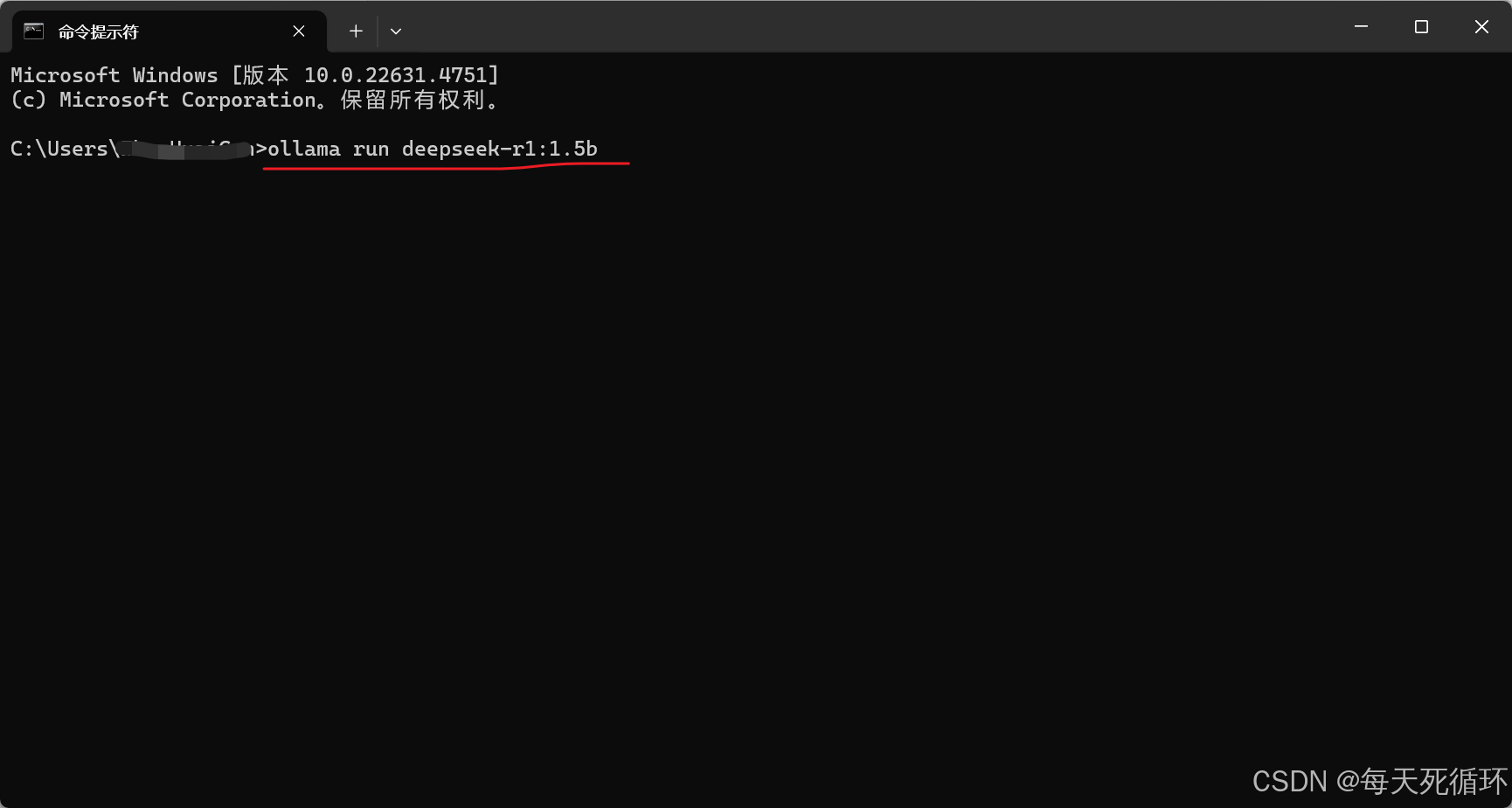
- 输入下载命令行 ==“ollama run deepseek-r1:1.5b”==输入完成之后点击回车,我这里是下载1.5b的内存1.1GB,先下内存小的,先试试看,
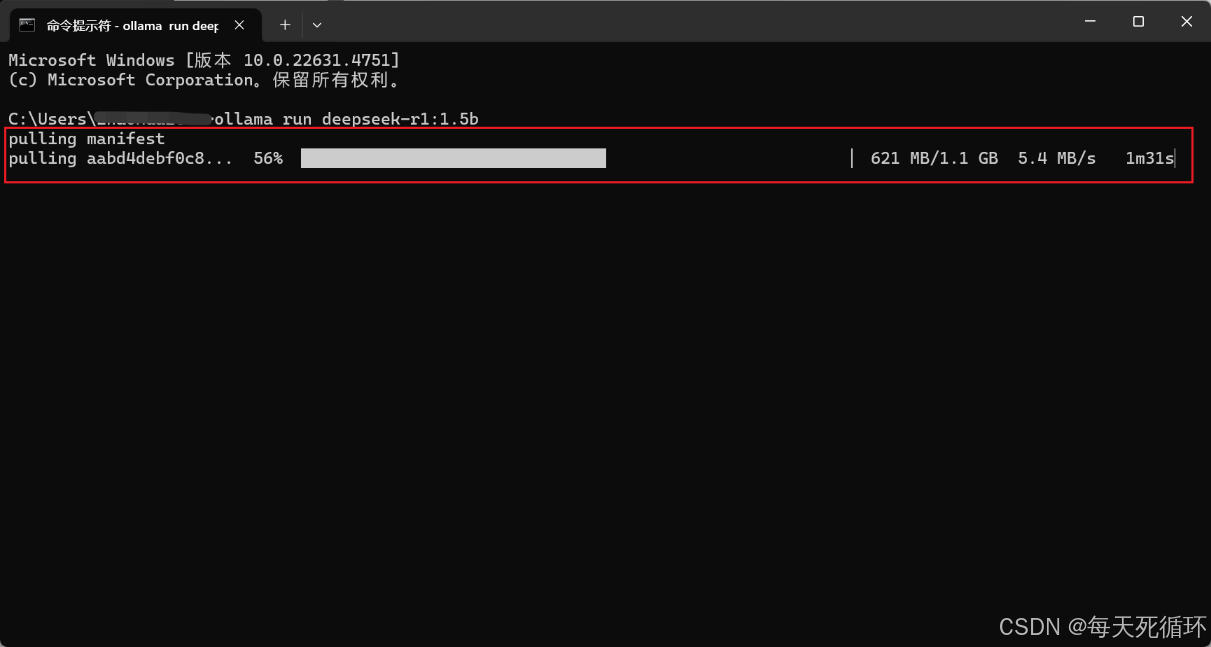
 2.下载中,出现这个进度条之后,说明正在下载,里面有个奇怪的问题,进度条看着是56%如果网有问题的话会倒退的,如果下载慢的话或者下到99%卡住了,或者其他问题,下面会单独说下 下载的问题。
2.下载中,出现这个进度条之后,说明正在下载,里面有个奇怪的问题,进度条看着是56%如果网有问题的话会倒退的,如果下载慢的话或者下到99%卡住了,或者其他问题,下面会单独说下 下载的问题。
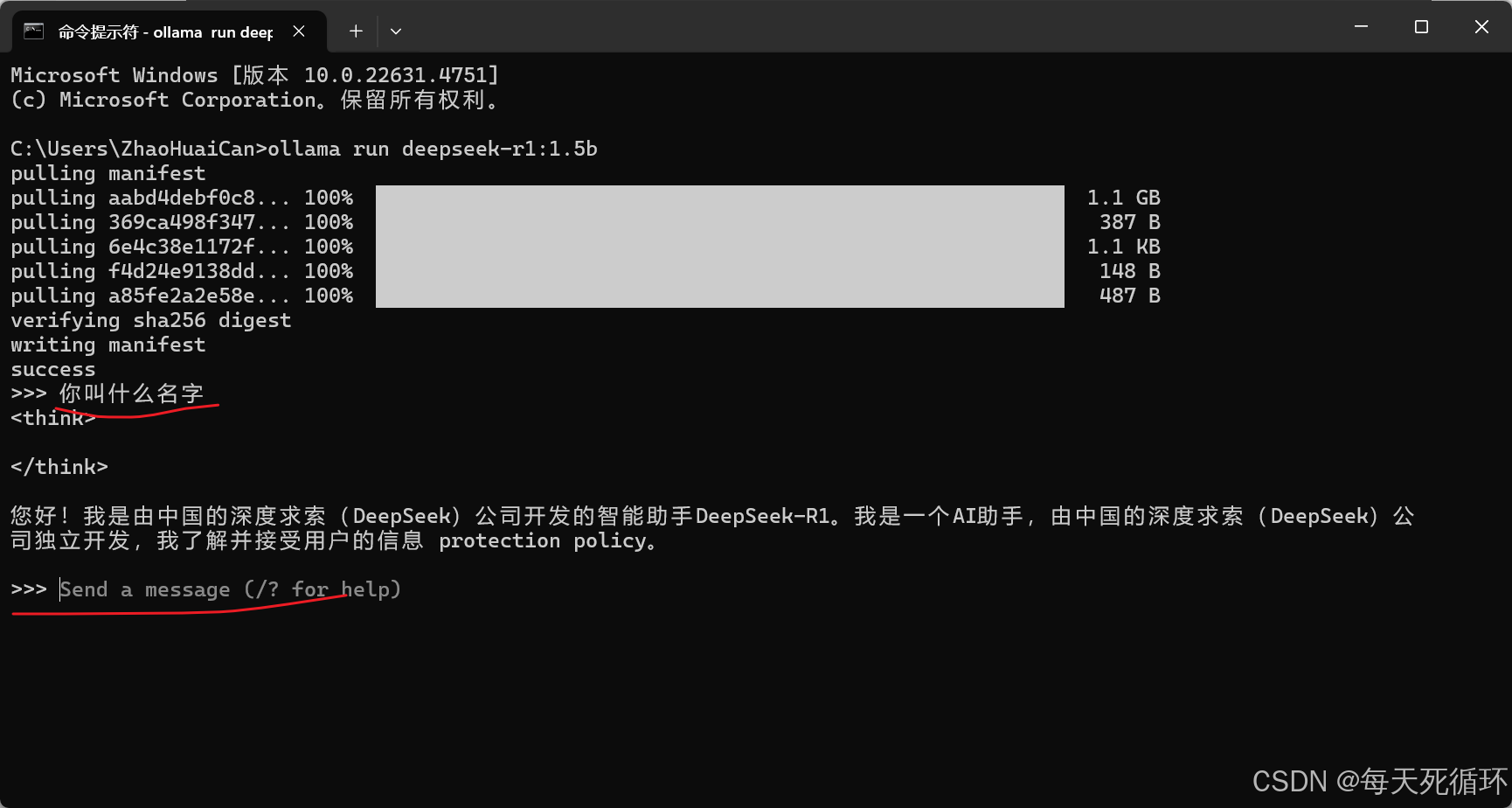
3.下载完成,直接输入询问
4.在webUI上测试是否正常,回到设置界面
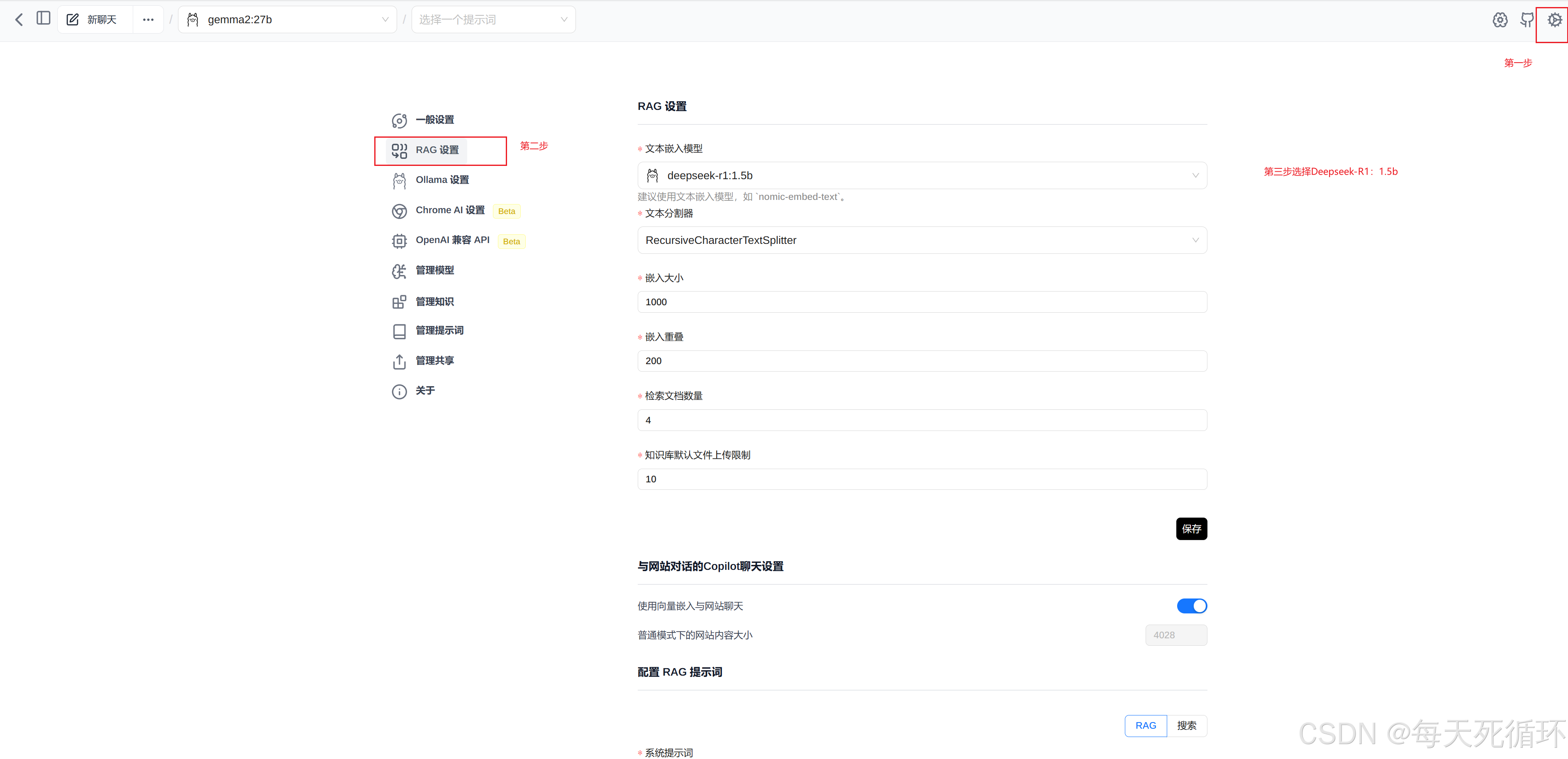
4.选择1.5b开始聊天,到此结束
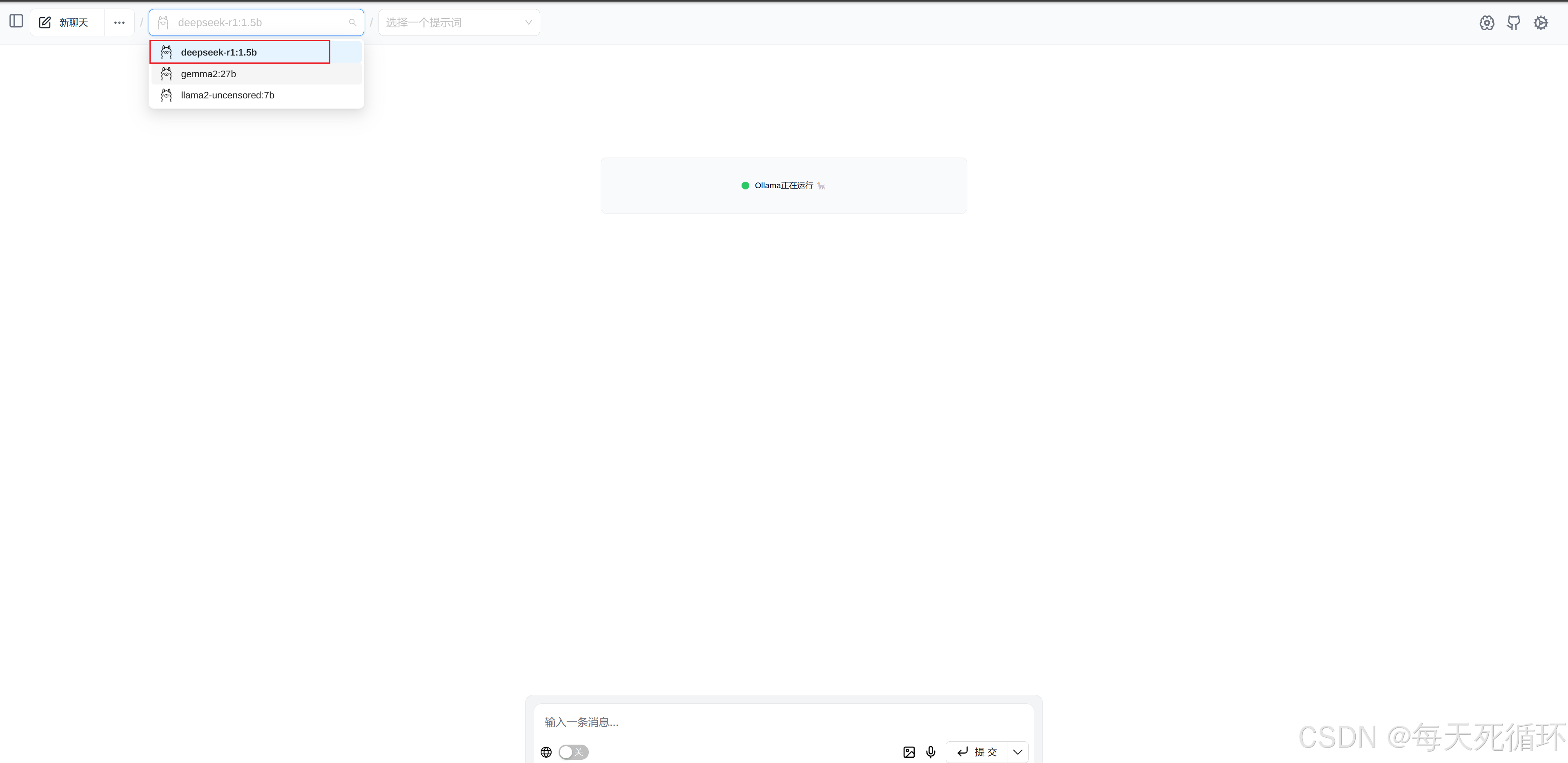
下载问题解决
- 下载慢解决方案
- 如果进度条走到90%~99%卡死不动了,那么赶紧拔一下网线,然后3秒之后插回去,或者禁用网络3秒左右在启用,很好用
- 如果进度条回退了,那么可能网络有问题,建议选择好的线路下载,一般1.5b不会出现这个情况
- 如果一直报错,有可能是ollama的问题下载的人太多了
- 如果报错路径问题,查看环境变量或者没有重启电脑,然后重复输入下载指令,重复多次还是不行就重启电脑
- 如果报错unable to allocate cuda0 buffer,是因为你显卡垃圾,重新选个小的下载
- 如果以上还是不行的话,那么从国内下载把,下面详解
在其他网站上下载
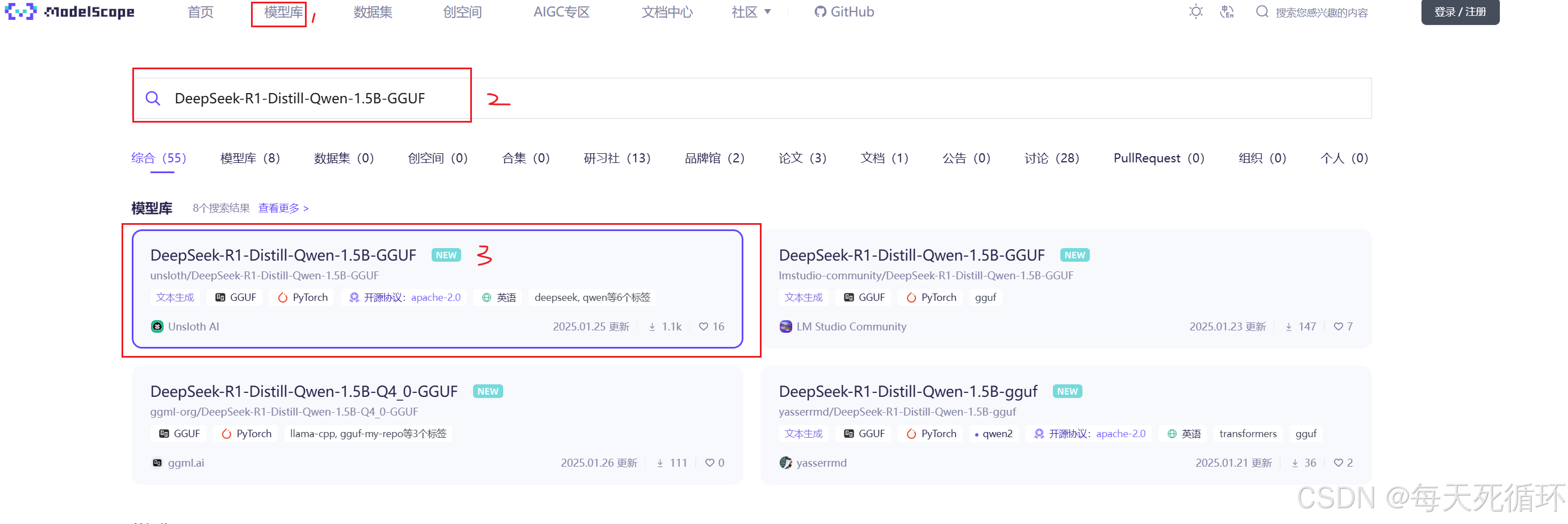
- 魔搭网-点我进入
一定要选择GGUF格式的哦
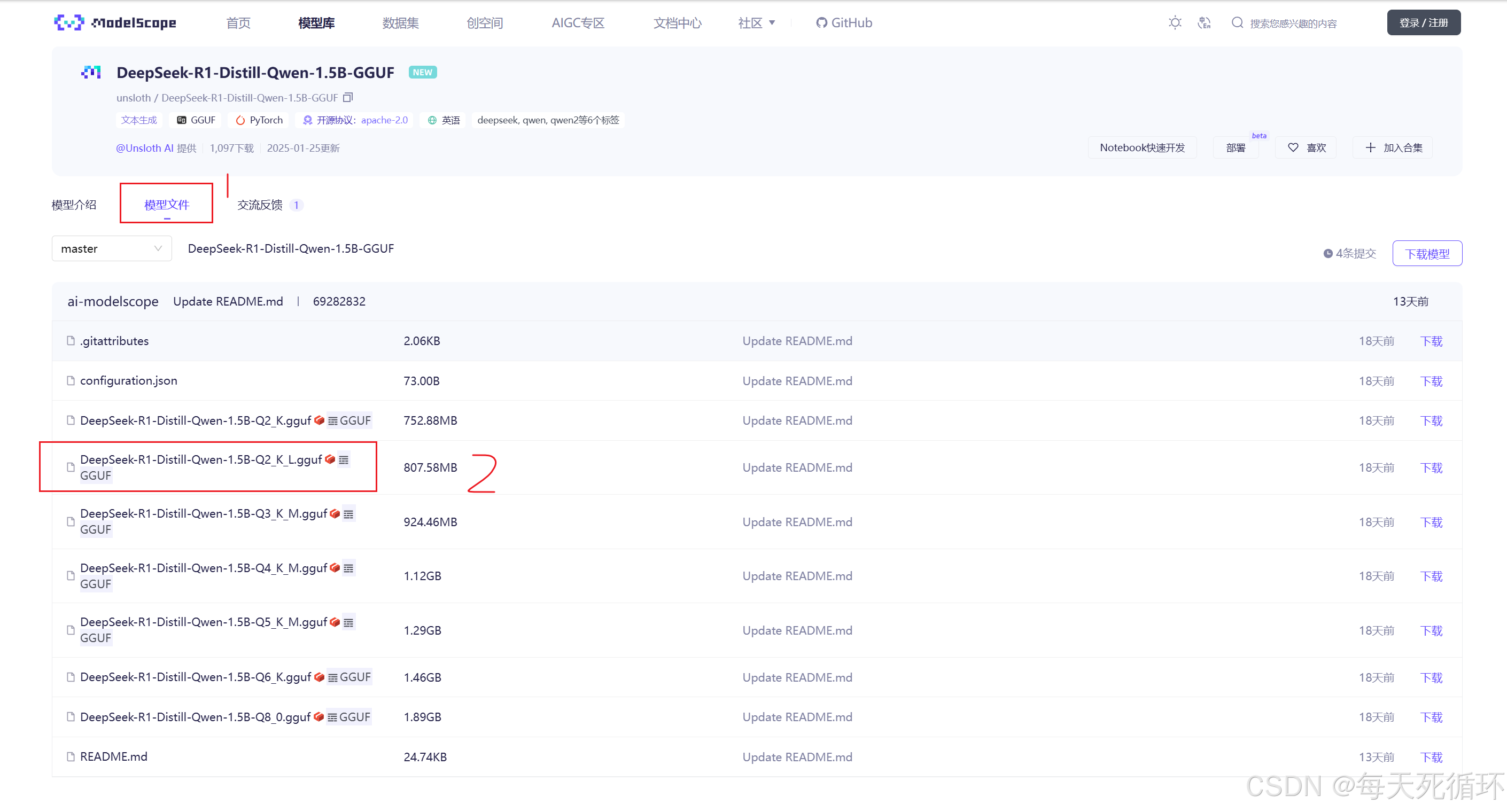
 2.点击模型,然后下载,自己量力而行,Q2到Q8都不一样数字越大,模型精度越高,电脑越吃性能,回答的越好
2.点击模型,然后下载,自己量力而行,Q2到Q8都不一样数字越大,模型精度越高,电脑越吃性能,回答的越好
3.下载完成之后,随便找个地方放,我是放到了Ollama位置,重新创建了一个文件夹叫DS
4.在创建个txt文件,我这里叫DSR1.5B我随便起的名字
6.在我们刚创建的DSR1.5B.txt文本里面写上内容,图片下面是代码直接复制改成你的下载的模型名字即可
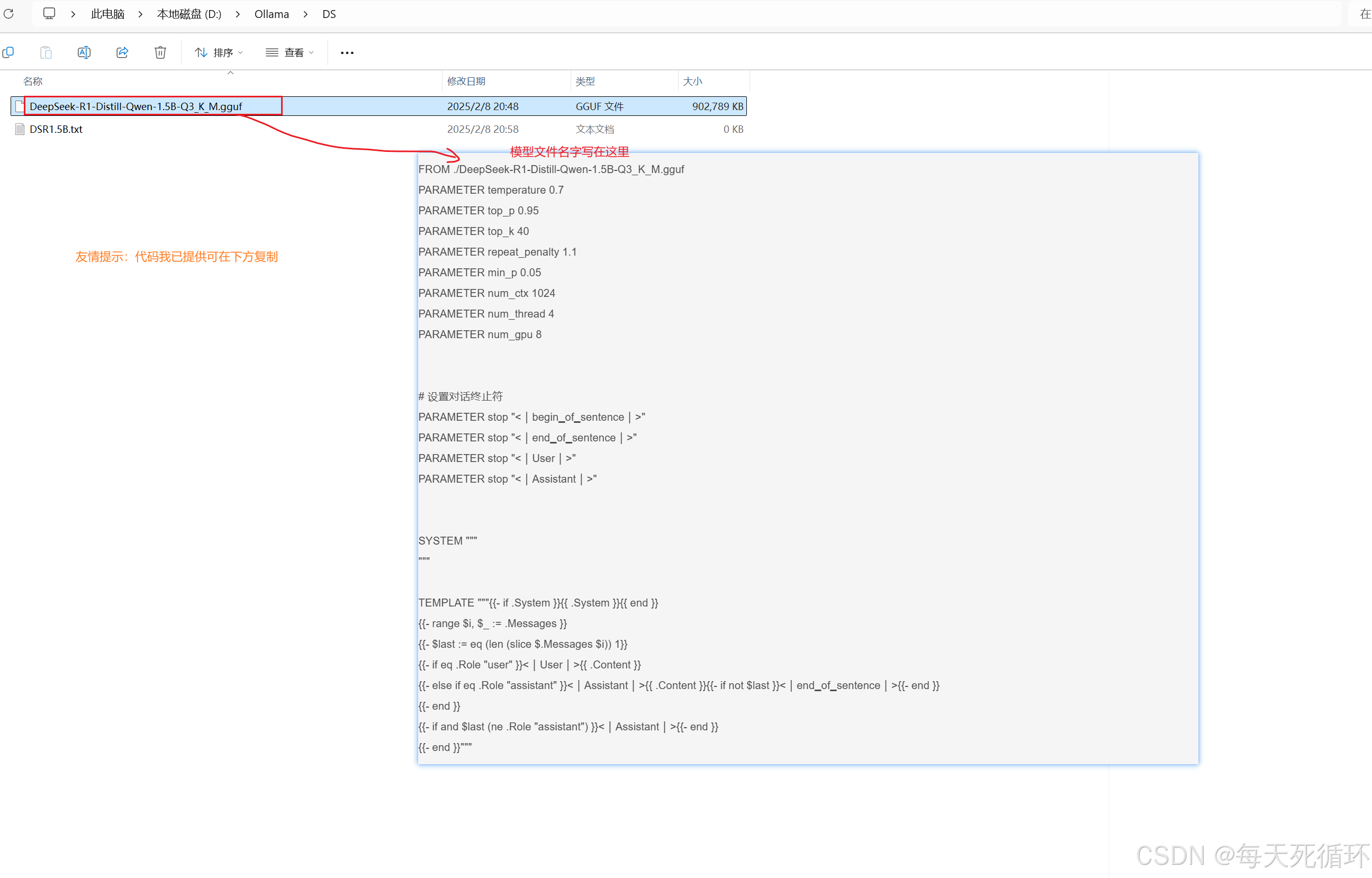
FROM ./DeepSeek-R1-Distill-Qwen-1.5B-Q3_K_M.gguf
PARAMETER temperature 0.7
PARAMETER top_p 0.95
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER min_p 0.05
PARAMETER num_ctx 1024
PARAMETER num_thread 4
PARAMETER num_gpu 8
# 设置对话终止符
PARAMETER stop "<|begin▁of▁sentence|>"
PARAMETER stop "<|end▁of▁sentence|>"
PARAMETER stop "<|User|>"
PARAMETER stop "<|Assistant|>"
SYSTEM """
"""
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
6.输入CMD打开命令提示符界面
7.打开CMD输入ollama create test-ds-r1:1.5b -f ./DSR1.5B.txt自己改一下模型名字和txt名字,然点击回车
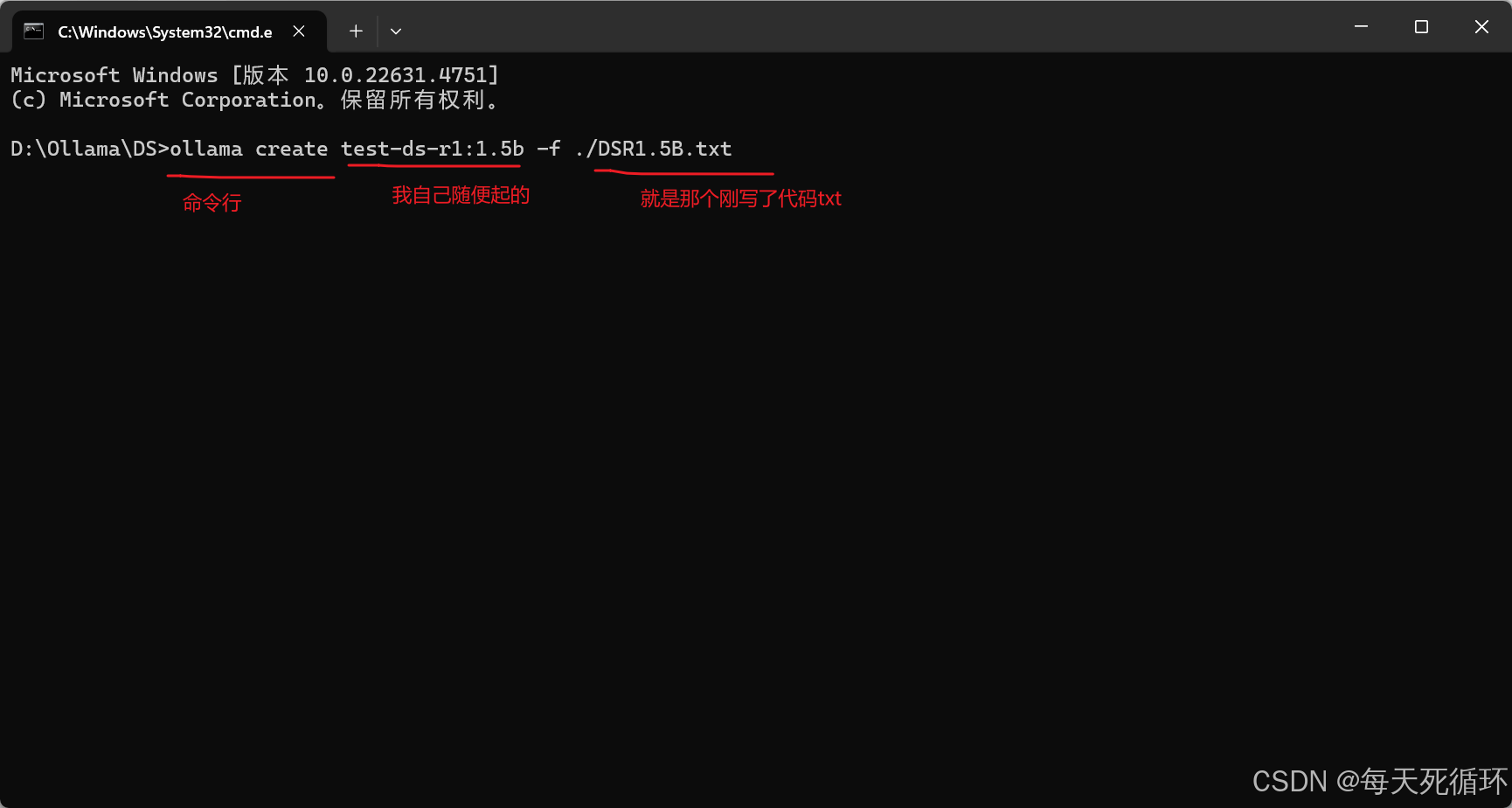
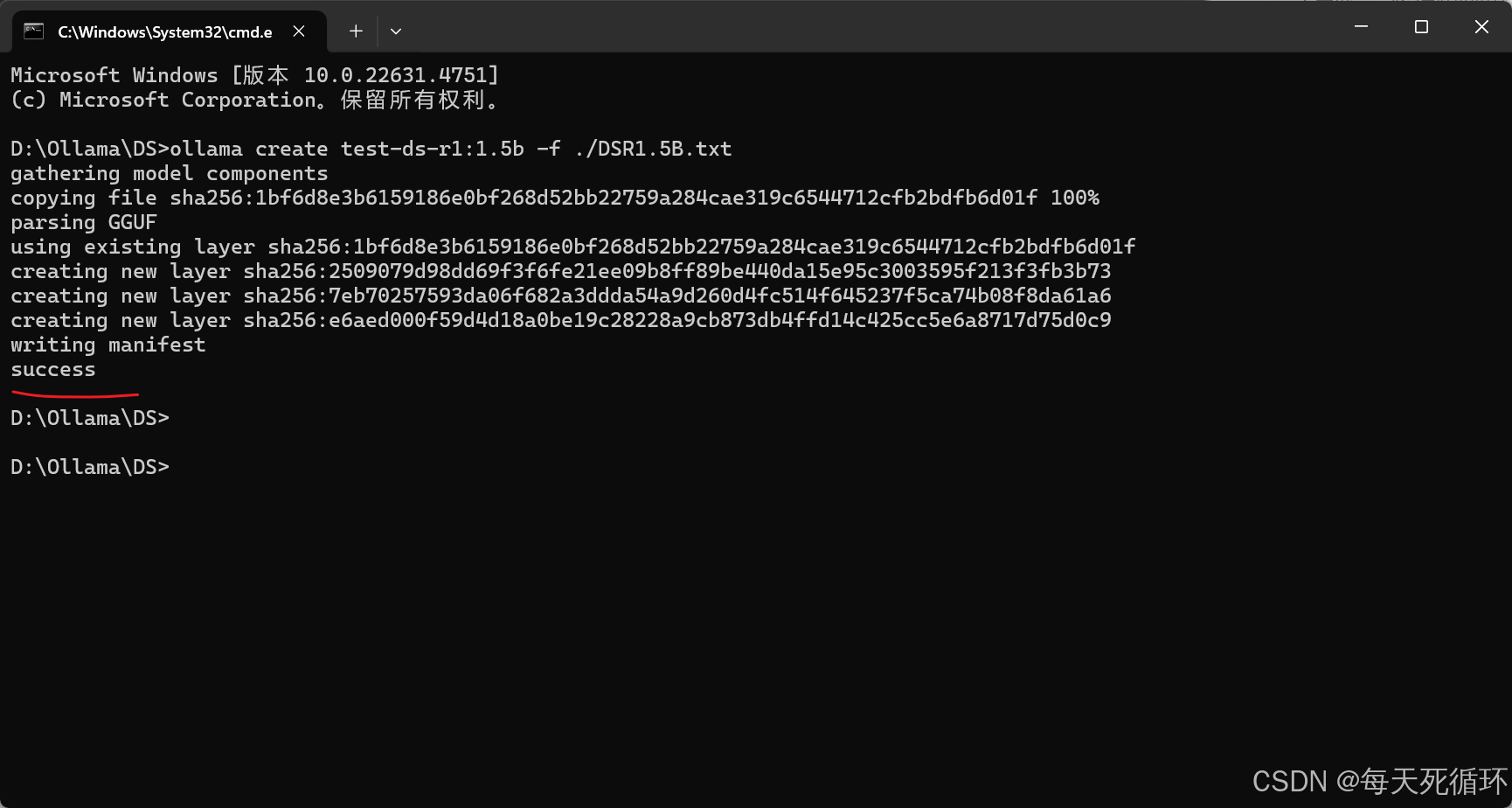
8.OK兄弟全体目光看齐,我们成功的装上,人工智障了
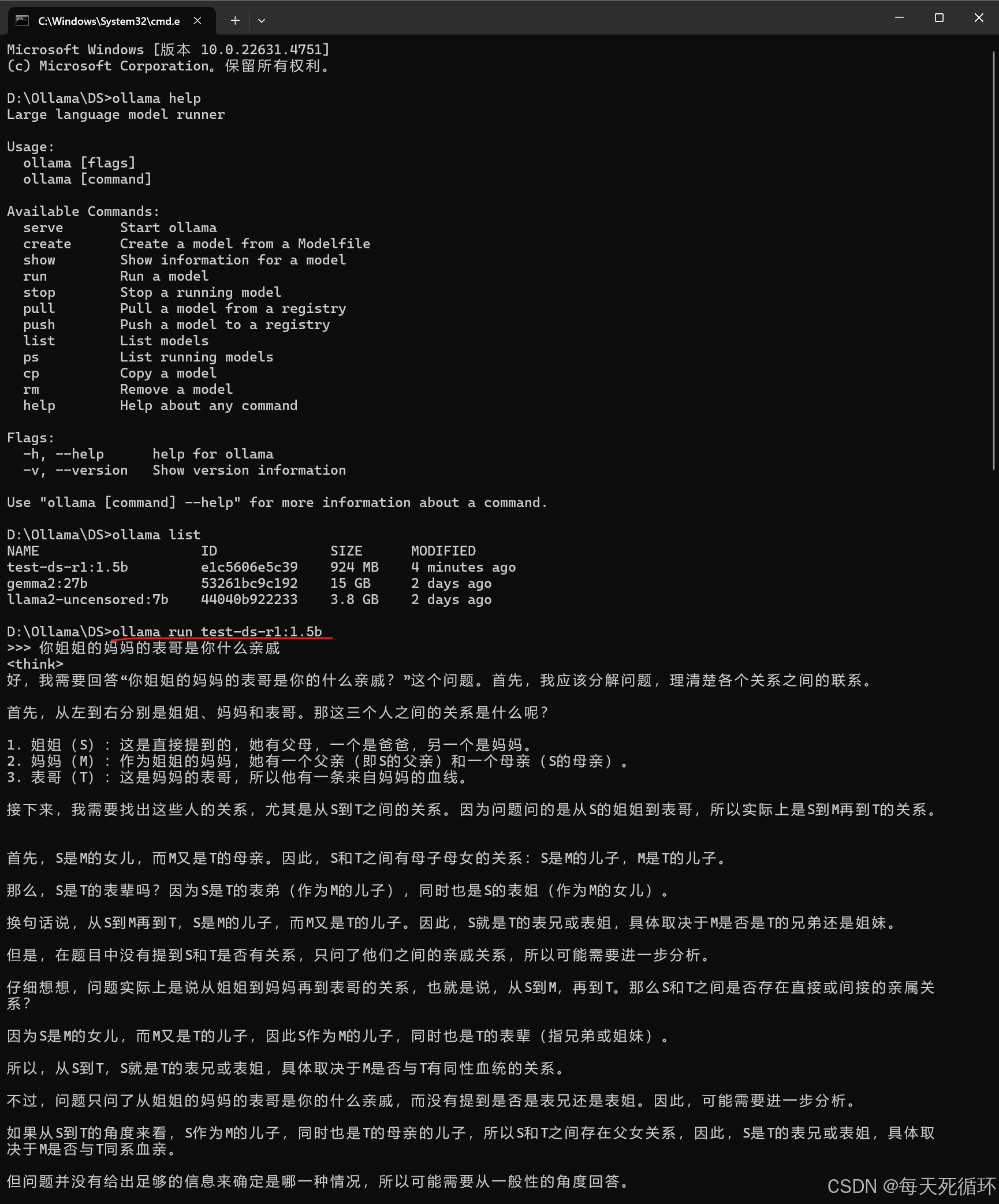
9.问人工智障个问题看看怎么样,输入ollama run 你刚才的模型名字,显然1.5B的是个智障,也可以在那个webui上选择去问,到此结束


















 3135
3135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









