







文章目录
马上要找工作了,学习了差不多两年的深度学习,但是现在我对于深度学习还是有一点迷茫,一直在调参当中渡过,即将找工作之际一点信心都没有。因此,撰写这篇文章,测试自己的知识有哪些掌握了,哪一些没有掌握。
A.词语定义
什么叫深度学习,神经网络,机器学习?
由于以前没有聚焦于这个问题,我到现在都对深度学习与神经网络的区别都不知道,现在开始重新梳理自己的知识架构。
包含关系:人工智能<<机器学习<<神经网络<<深度学习
人工智能(英语:artificial intelligence,缩写为AI)亦称智械、机器智能,指由人制造出来的机器所表现出来的智能,通常是指通过普通计算机程序来呈现人类智能的技术【1】。
机器学习是人工智能的一个分支。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。【2】
神经网络一般是人工神经网络(Artificial Neural Network,即ANN )的简称,是模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构与功能,设计的数学模型与计算模型,用于对未知函数进行估计与逼近【3】。
深度学习(英语:deep learning)是机器学习的分支,是一种以人工神经网络为架构,对资料进行表征学习的算法,由2006年Geoffrey Hinton深度信念网络率先提出“深度”一词,指代一系列训练深层神经网络的方法。有时候深度学习代表的是最少5层的多层神经网络,一般正确命名为深度神经网络。因为存在不是神经网络的深度模型,例如级联森林和多粒度扫描。。【4】
特征学习或表征学习是学习一个特征的技术的集合:将原始数据转换成为能够被机器学习来有效开发的一种形式。它避免了手动提取特征的麻烦,允许计算机学习使用特征的同时,也学习如何提取特征:学习如何学习。【5】
感知器是Frank Rosenblatt在1957年所发明的一种人工神经网络,可以被视为一种最简单形式的前馈式人工神经网络,是一种二元线性分类器。感知器是激活函数为阶跃函数的神经元,如果存在激活函数不是阶跃的,那么这个网络就不是感知器。
误差反向传播算法(Error Back Propagation Training),简称BP,发展于20世纪80年代中期,由David Runelhart、Geoffrey Hinton和Ronald W-llians、DavidParker等人分别独立发现,解决了多层神经网络隐含层连接权学习问题,并在数学上给出了完整推导。【6】
MLP= 神经网络(2层,输入,隐藏,输出,但是输入层不涉及计算),BP神经网络(实际并没有)=采用BP算法进行训练的神经网络。
神经网络类别包括【7】:
- 感知器(Perceptron§)、
- 前馈(Feed Forward (FF))、
- 径向基网络(Radial Basis Network (RBN)) 、
- 深度前馈(Deep Feed-forward (DFF)) 、
- 循环神经网络(Recurrent Neural Network (RNN))、
- 长/短期记忆(Long / Short Term Memory (LSTM))、
- 门控循环单位(Gated Recurrent Unit (GRU))、
- 自动编码器(Auto Encoder (AE))、
- 变分自动编码器(Variational Autoencoder (VAE))
- 去噪自动编码器(Denoising Autoencoder (DAE)
- 稀疏自动编码器(Sparse Autoencoder (SAE))
- 马尔可夫链(Markov Chain (MC))
- 霍菲特网络(Hopfield Network (HN))
- 波茨曼机(Boltzmann Machine (BM))
- 受限玻尔兹曼机(Restricted Boltzmann Machine (RBM))
- 深度信念网络(Deep Belief Network (DBN))
- 深度卷积网络(Deep Convolutional Network (DCN))
- 反卷积神经网络(Deconvolutional Neural Networks (DN))
- 深度卷积逆图形网络(Deep Convolutional Inverse Graphics Network (DC-IGN))
- 生成对抗网络(Generative Adversarial Network (GAN))
- 液态机(Liquid State Machine (LSM))
- 极限学习机(Extreme Learning Machine (ELM))
- 回声状态网络(Echo State Network (ESN))
- 深度残差网络(Deep Residual Network (DRN))
- Kohonen网络(Kohonen Networks (KN) )
- 支持向量机(Support Vector Machines (SVM))
- 持向量机并不是神经网络,支持向量机神经网络是支持向量机和神经网络的混合算法。对于一组新的样本,它总是试图分为两类: 是或否(1或0)。支持向量机通常用于二分类。这些通常不被认为是神经网络。
- 神经图灵机(Neural Turing Machine (NTM))
- 人工智能 - 维基百科,自由的百科全书
- 人工神经网络 - 维基百科,自由的百科全书
- 机器学习 - 维基百科,自由的百科全书
- 深度学习 - 维基百科,自由的百科全书, (4 封私信) 神经网络啥时候改名叫“深度学习”了? - 知乎
- 表征学习 - 维基百科,自由的百科全书
- BP神经网络_百度百科
- 神经网络主要类型及其应用 - 知乎
B.神经网络超参数
超参数分类【1,3】
- 学习率 η
- 正则化参数 λ【2】,在损失函数中添加参数约束,一般有L1/L2
- 神经网络的层数 L
- 每一个隐层中神经元的个数 j
- 学习的回合数Epoch
- 小批量数据 minibatch 的大小
- 输出神经元的编码方式
- 代价函数的选择
- 权重初始化的方法
- 神经元激活函数的种类
- 参加训练模型数据的规模
超参数类型多,但是不是每一类都需要通过实验查看确定大小,有些超参数是网络超参数,有些是训练超参数。
训练超参数:学习率 η,正则化参数 λ,学习的回合数Epoch,小批量数据 minibatch 的大小,代价函数的选择,参加训练模型数据的规模
网络超参数:神经网络的层数 L,每一个隐层中神经元的个数 j,神经元激活函数的种类,输出神经元的编码方式,权重初始化的方法
超参数选择的优化顺序:
1.网络超参数(网络超参数一般是通过阅读论文,参考github代码进行基础模型设计)
2.训练超参数(1.根据任务要求与时间要求选择训练数据、代价函数、Epoch;2.根据自己台式电脑显存大小选择minibatch;3.学习率η根据梯度下降法的优化器进行选择(一般选择Adam优化器(10e-4,10e-7),SGD(10e-1,10e-3),之后设置一个余弦下降法);4.正则化参数 λ有默认值为0(主要看训练结果而决定更改))
默认无需更改超参数:学习率η,正则化参数 λ,学习的回合数Epoch,小批量数据 minibatch 的大小,参加训练模型数据的规模,神经元激活函数的种类,输出神经元的编码方式,权重初始化的方法,
着重更改:神经网络的层数 L,每一个隐层中神经元的个数 j,代价函数的选择
综上:在超参数优化这一块,在得到一个可以正常工作的训练基准之后,主要调整的是网络结构参数。以上观点仅仅代表我的浅陋观点,我的主要研究方向是图像去模糊,因此可能是有错。
- 神经网络参数选择(keras,tensorflow) - 知乎
- pytorch实现L2和L1正则化regularization的方法_pan_jinquan的博客-CSDN博客
- 卷积神经网络(CNN)的参数优化方法_韵开-CSDN博客
C.过拟合原因以及解决方法
定义:训练的模型在训练数据集表现好,在测试集表现差
原因:
(1)数据有噪声,质量差;模型记住了噪音特征而忽略了真实数据的输入输出关系;
(2)数据量太小;训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
(3)训练模型过渡;权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
(4)训练集与测试集分布不一致; 训练集与测试集特征分布不一致;
(5)模型复杂度太大;数据规律简单,使用了复杂模型导致拟合过度
解决方案:
(simpler model structure、 data augmentation、 regularization、 dropout、early stopping、ensemble、重新清洗数据)
模型层面:
-
降低模型复杂度;调小模型复杂度,使其适合自己训练集的数量级(缩小宽度和减小深度)
-
正则化;参数太多,会导致我们的模型复杂度上升,容易过拟合,加入正则化引入额外惩罚项,保持模型简单,L1 使参数变得稀疏,L2使参数变得平滑
-
dropout;在训练的时候让神经元以一定的概率不工作
-
Batch Normalization:使得每一层的数据分布不变,做归一化处理
数据层面:
- 增广数据集;训练集越多,过拟合的概率越小。在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等
- 交叉验证;保证数据集分布一致性
训练层面:
- 早停;在模型对训练数据集迭代收敛之前停止迭代来防止过拟合
- 集成学习;通过平均多个模型的结果,来降低模型的方差。
过拟合(定义、出现的原因4种、解决方案7种)_NIGHT_SILENT的博客-CSDN博客
深度学习和机器学习中过拟合的判定、原因和解决方法_HUSTHY的博客-CSDN博客_深度学习过拟合的原因
D.梯度爆炸和梯度消失
定义:
反向传播过程中需要对激活函数进行求导,如果导数大于1,那么随着网络层数的增加,求出的梯度更新将以指数形式增加,这就是梯度爆炸;同样如果导数小于1,那么随着网络层数的增加,梯度更新信息将以指数形式减少,这就是梯度消失。
注意:梯度消失、爆炸,根本原因在于反向传播的链式求导法则,属于先天不足,一般随着网络层数的增加会越来越明显。
产生原因:
- 网络结构:主要是网络层数
- 激活函数的选择
- 网络权值初始化,值太大容易产生梯度爆炸,太小容易梯度消失
解决方案
- 预训练加微调;此方法来自Hinton在2006年发表的一篇论文,Hinton为了解决梯度的问题,提出采取无监督逐层训练方法
- 梯度剪切,正则化;主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,正则化是通过对网络权重做正则限制过拟合,同时限制了w的大小
- relu、leakrelu、elu等激活函数;
- batch normalization;通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性;同时消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
- 残差结构;残差的捷径(shortcut)部分使得梯度能够一直传递
- LSTM;内部复杂的门可以记住前几次训练的残留记忆,同时多条路径梯度的叠加防止梯度消失
详解机器学习中的梯度消失、爆炸原因及其解决方法_Double_V的博客-CSDN博客_梯度消失
网络权重初始化方法总结(上):梯度消失、梯度爆炸与不良的初始化 - shine-lee - 博客园
(4 封私信) LSTM如何来避免梯度弥散和梯度爆炸? - 知乎
深度学习—梯度消失和爆炸、权重初始化 - 深度机器学习 - 博客园
常用激活函数
定义:激活函数(Activation Function)是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
作用:增加模型非线性表示能力
为什么使用激活函数:
- 神经网络的万能近似定理:神经网络只要具有至少一个非线性隐藏层,那么只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数。
- 如果不使用非线性激活函数,那么每一层输出都是上层输入的线性组合;此时无论网络有多少层,其整体也将是线性的,这会导致失去万能近似的性质
- 但仅部分层是纯线性是可以接受的,这有助于减少网络中的参数。
性质:
- 非线性,线性激活层对于深层神经网络没有作用,因为其作用以后仍然是输入的各种线性变换
- 连续可微:梯度下降的要求
- 范围最好不饱和,也就是梯度一直大于0,如果梯度等于0的话,那么就会是的训练停止
- 单调性:单层神经网络的误差函数是凸的,好优化
- 在原点处近似线性,这样当权值初始化为接近0的随机值时,网络可以学习的较快,不用调节网络的输出值
- 计算简单:激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
- 输出值的范围有限: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的 Learning Rate。
- 参数少: 大部分激活函数都是没有参数的。
- 归一化: 主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。
饱和分类:
硬饱和,软饱和,左饱和和右饱和
- 右饱和:当x趋向于正无穷时,函数的导数趋近于0
- 左饱和:当x趋向于负无穷时,函数的导数趋近于0
- 右硬饱和:对于任意的x。若存在常数c,当x>c时,恒有导数等于0成立
- 左硬饱和:对于任意的x。若存在常数c,当x<c时,恒有导数等于0成立
- 饱和函数:当一个函数既满足右饱和,又满足左饱和,例如(Sigmoid,Tanh),否则称为非饱和函数。
- 硬饱和:若既满足左硬饱和,又满足右硬饱和,否则称为软饱和函数。
类别与功能:
常用:sigmoid;tanh;ReLU;LReLU, PReLU, RReLU;ELU(Exponential Linear Units);softplus;softsign,softmax等
sigmoid函数
f ( x ) = 1 1 + e − x = σ ( x ) f(x)= \frac{1}{1+e^{−x}}=\sigma(x) f(x)=1+e−x1=σ(x)
sigmoid函数又称 Logistic函数,用于隐层神经元输出,取值范围为(0,1),可以用来做二分类。
它的导数为:
f
′
(
x
)
=
e
−
x
(
1
+
e
−
x
)
2
=
σ
(
x
)
(
1
−
σ
(
x
)
)
f^{'}(x)=\frac{e^{-x}}{\left(1+e^{-x}\right)^{2}}=\sigma(x)(1-\sigma(x))
f′(x)=(1+e−x)2e−x=σ(x)(1−σ(x))
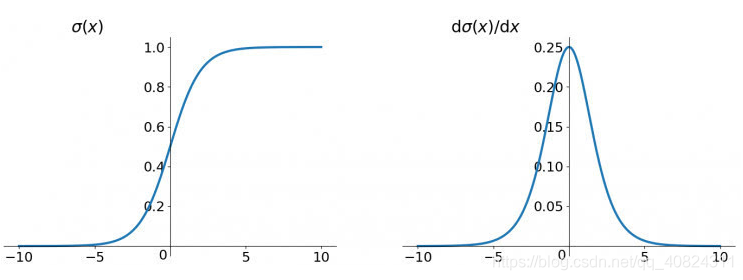
图像如下:
 ]
]
可以看出sigmoid的导数最大值为0.25,在进行反向传播时,各层的梯度(均小于0.25)相乘很容易造成梯度为0,也就是“梯度消失”。
优点:
- Sigmoid函数的输出在(0,1)之间,输出范围有限,优化稳定,可以用作输出层。
- 连续函数,便于求导。
缺点:
- sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和现象,意味着函数会变得很平,并且对输入的微小改变会变得不敏感。在反向传播时,当梯度接近于0,权重基本不会更新,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
- sigmoid函数的输出不是0为中心,会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响。
- 计算复杂度高,因为sigmoid函数是指数形式。
tanh函数
f ( x ) = tanh ( x ) = e x − e − x e x + e − x = 2 σ ( 2 x ) − 1 f(x)=\tanh (x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}=2\sigma(2x)-1 f(x)=tanh(x)=ex+e−xex−e−x=2σ(2x)−1
导数
f
′
(
x
)
=
4
e
2
x
(
e
2
x
+
1
)
2
=
1
−
[
t
a
n
h
(
x
)
]
2
f^{'}(x)=\frac{4 e^{2 x}}{\left(e^{2 x}+1\right)^{2}}=1-[tanh (x)]^2
f′(x)=(e2x+1)24e2x=1−[tanh(x)]2
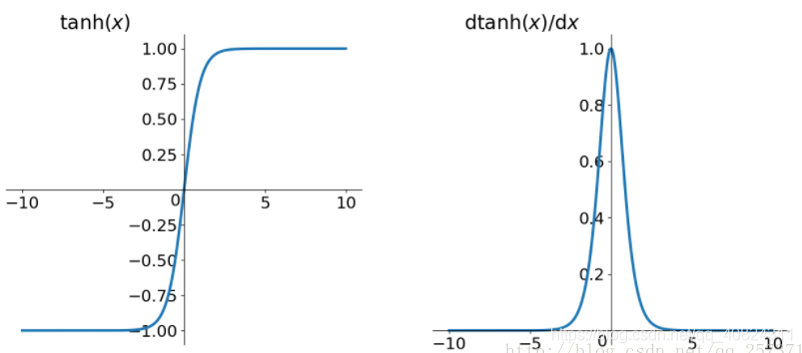 ]
]
Tanh函数是 sigmoid 的变形,本质上是 sigmoid 向下平移和伸缩后的结果,是 0 均值的,因此实际应用中 Tanh 会比 sigmoid 更好。但是仍然存在梯度饱和、梯度消失与指数计算的问题。
ReLU函数:
线性整流函数(Rectified Linear Unit, ReLU)
f
(
x
)
=
relu
(
x
)
=
max
(
0
,
x
)
f(x)=\operatorname{relu}(x)=\max (0, x)
f(x)=relu(x)=max(0,x)
导数
f
′
(
x
)
=
{
1
,
i
f
x
>
0
0
,
i
f
x
<
0
f^{'}(x)= \begin{cases} 1, &if\ x>0\\ 0, &if\ x<0 \end{cases}
f′(x)={1,0,if x>0if x<0
| 激活函数图 | 导数图 |
|---|---|
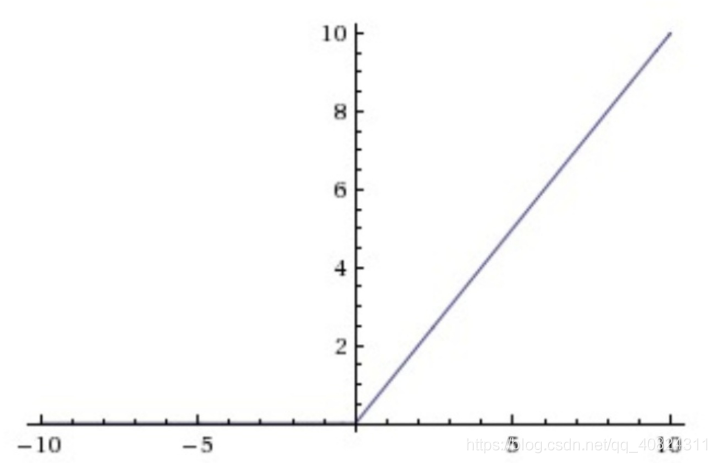 ]] ]] | 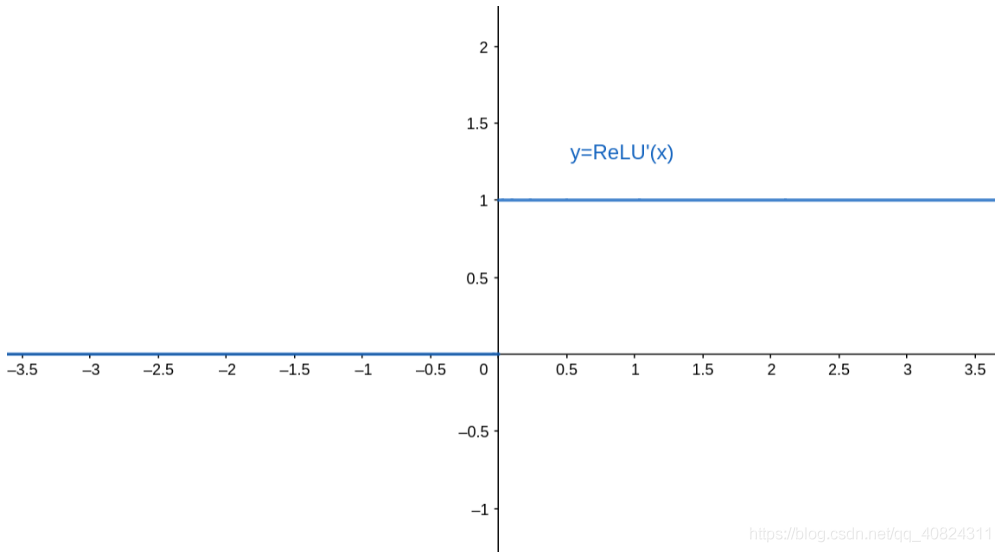 |
优点:
- 解决了梯度消失问题
- 减缓过拟合;当x < 0,增大了网络的稀疏性,训练完成之后为0的神经元越多,稀疏性越大,提取出来的特征就越具有代表性,泛化能力越强,真正起作用的神经元越少,网络的泛化能力就越好
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度快于sigmoid和tanh,因为这两个梯度最大为0.25,而relu为1
缺点:
- 输出不是0为中心
- 输入值小于0,输出值就会是0;一阶导也是0.这样导致训练开始时一些神经元就是死的。输入值小于0,输出值就会是0;一阶导也是0.这样导致训练开始时一些神经元就是死的。
- 原点不可导
选择:
- 深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度;
- 如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout;
- 最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
常见激活函数,及其优缺点 - 面试篇_GreatXiang888的博客-CSDN博客_常见激活函数优缺点
激活函数中的硬饱和,软饱和,左饱和和右饱和。_donkey_1993的博客-CSDN博客_软饱和
E其他
神经网络BP反向传播算法原理和详细推导流程_Z_y_forever的博客-CSDN博客_bp反向传播















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









