







联邦学习之逻辑回归
1,横向逻辑回归(HomoLR)
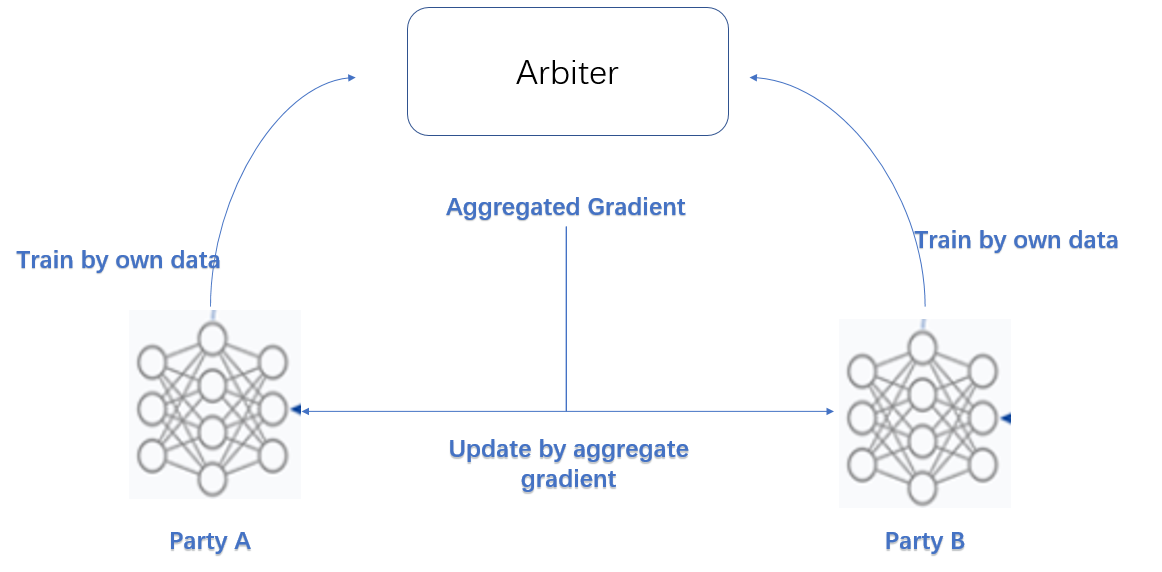
横向联邦中模型的一般训练过程:
- 1,第三方分发公私钥:参与方持有PK,第三方持有SK
- 2,参与方本地训练模型,加密上传到第三方
- 3,第三方解密,聚合模型,做加权平均
- 4,发送给各参与方,参与方本地更新模型直到收敛。
其中,模型聚合使用了安全聚合算法:SecureAggregation。大概思路是:各参与方通过加入随机数,汇总后的随机数能够抵消,使得第三方只能得到总模型,无法得知某个参与方的具体模型。
算法 paper:Practical Secure Aggregation for Privacy-Preserving Machine Learning
2,纵向逻辑回归(HeteroLR)
纵向联邦中模型的一般训练过程:
- 1,加密样本对齐
- 2,参考横向联邦的一般过程
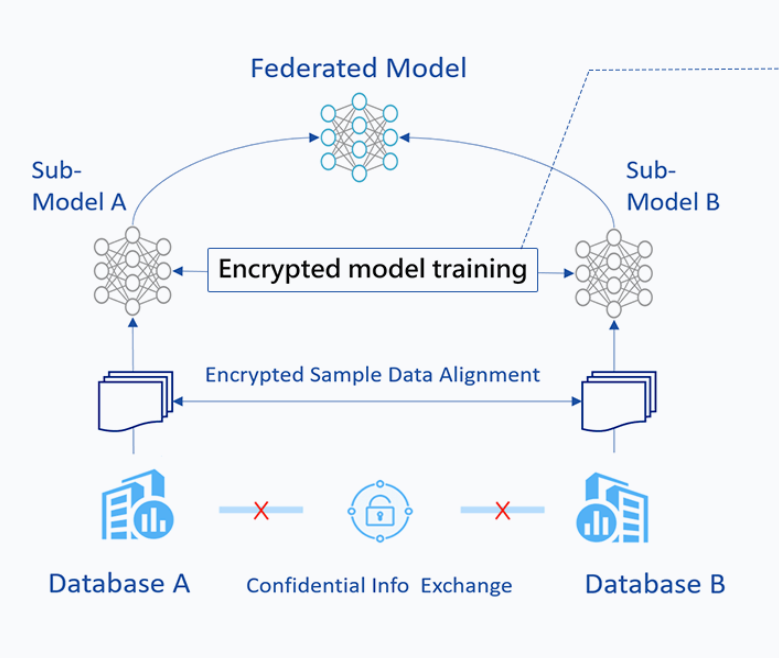
纵向联邦场景中需要进行一步隐私集合求交操作(PSI),FATE 中基本操作是使用RSA+Hash 的方案。此处暂不做介绍。
另外,纵向联邦中我们通常会使用加法同态(Paillier)对梯度进行加密,但是加密只支持同态加和标量乘。因此,我们需要对一般的逻辑回归公式进行处理。这里的处理方法是使用泰勒公式对式子在零点处展开。
符号说明:
| 符号 | 含义 |
|---|---|
| 【【*】】 | 同态加密 |
| u i A u_i^A uiA | w A x A w_Ax_A wAxA |
| u i B u_i^B uiB | w B x B w_Bx_B wBxB |
| loss | l o g ( 1 + e x p ( − y w T x ) ) ≈ l o g 2 − 1 2 y w T x + 1 8 ( w T x ) 2 log(1+exp(-yw^Tx))\approx log2-\frac{1}{2}yw^Tx+\frac{1}{8}(w^Tx)^2 log(1+exp(−ywTx))≈log2−21ywTx+81(wTx)2 |
| 梯度g | ( 1 1 + e x p ( − y w T x ) − 1 ) y x ≈ ( 1 2 y w T x − 1 ) 1 2 y x (\frac{1}{1+exp(-yw^Tx)}-1)yx \approx(\frac{1}{2}yw^Tx-1)\frac{1}{2}yx (1+exp(−ywTx)1−1)yx≈(21ywTx−1)21yx |
| 残差d | ( 1 1 + e x p ( − y w T x ) − 1 ) y ≈ ( 1 2 y w T x − 1 ) 1 2 y (\frac{1}{1+exp(-yw^Tx)}-1)y \approx(\frac{1}{2}yw^Tx-1)\frac{1}{2}y (1+exp(−ywTx)1−1)y≈(21ywTx−1)21y;即 g=dx |
根据逻辑回归背景知识,
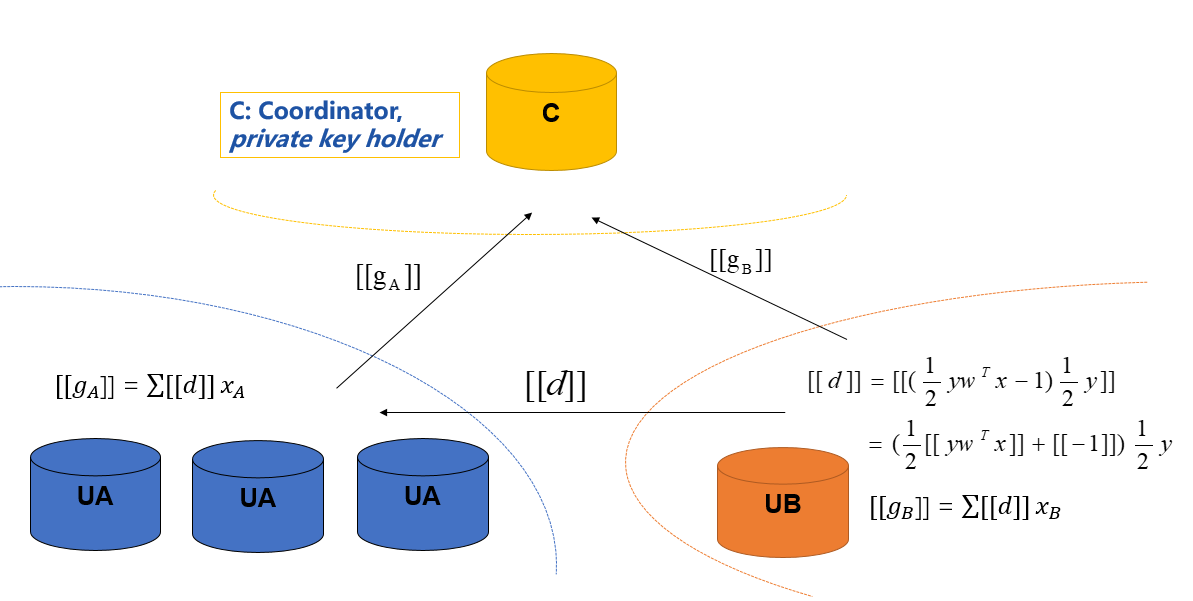
具体过程说明:
UB 表示 guest,UA 表示 host,C 表示 abitier。
- guest 计算本地残差并发给 host,然后向中心发送梯度gb;
- host 利用残差计算本地梯度ga并发送到中心;
- abitier 持有私钥解密更新全局梯度g,再返回给参与方。
3,总结
横向联邦中:最终训练的模型是共享的;
纵向联邦中:模型分布在各参与方,模型的使用需要参与方共同参与。















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









