






CVPR-2021-TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
论文地址:https://arxiv.org/pdf/2102.04306.pdf
代码地址:https://github.com/Beckschen/TransUNet
摘要
一方面,在医学图像分割领域,UNet已经取得了很优秀的效果,但传统CNN结构感受野有限,不擅长建立远程信息连接,导致最终效果受限。
另一方面,Transformer这种全局自注意力机制可以有效地获取全局信息,但其对于低层次细节信息获取不充分,导致其定位能力方面受到限制。
所以这篇文章提出了TransUNet,将Transformer和U-Net结合了起来,它同时具有Transformers和U-Net的优点,是医学图像分割的强大替代方案。
Transformer将来自卷积神经网络(CNN)特征图的标记化图像块编码为提取全局上下文的输入序列。
解码器对编码的特征进行上采样,然后将其与高分辨率的CNN特征图组合以实现精确的定位。
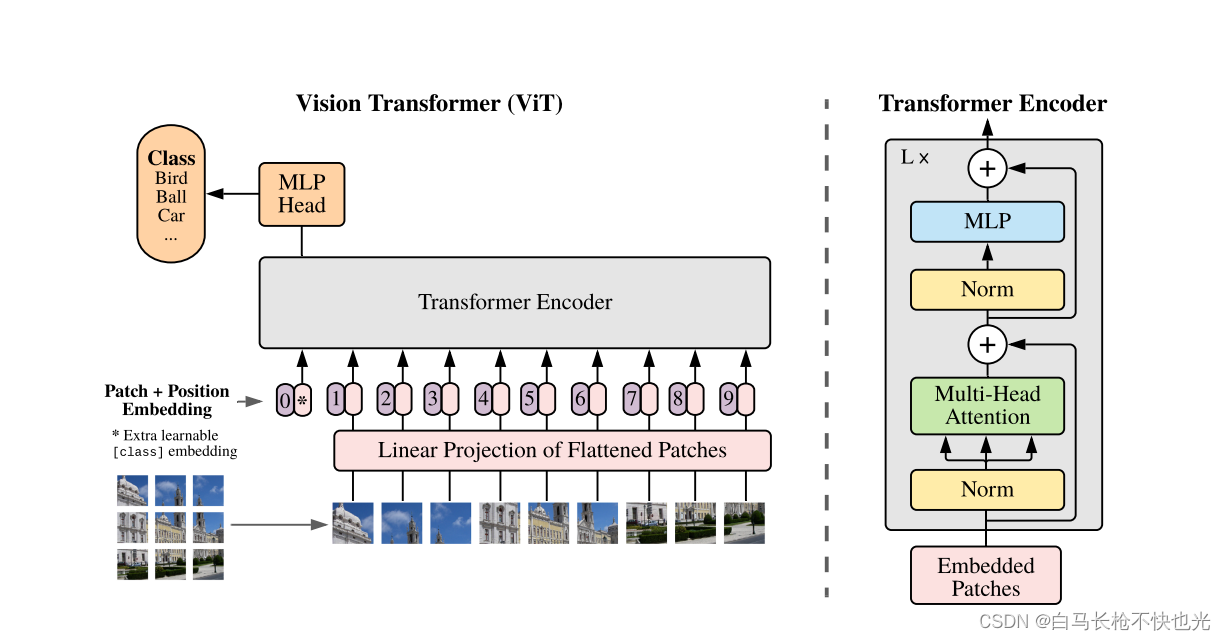
一、TransUNet总体架构
TransUNet总体上还是一个U型的Encoder-Decoder结构。
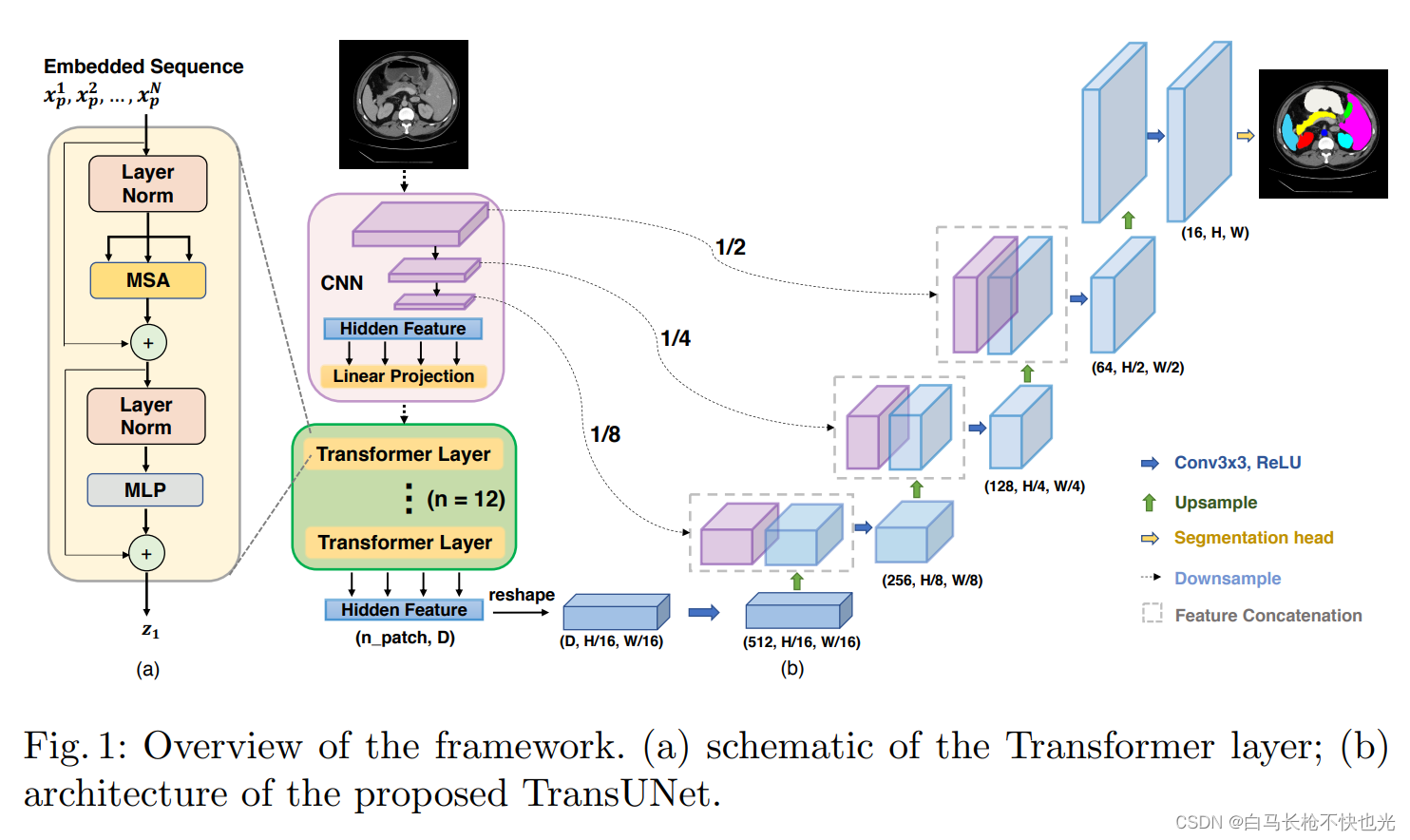
在编码器部分,为了能将高分辨率的特征图通过跳级连接与上采样后的特征图联合以获得充分的信息,作者没有像ViT那样将原图直接打成patch块输入到Transformer模块中,而是将原图输入CNN进行特征提取,线性投影之后进行Patch Embedding将特征图序列化并加上位置编码,输入transformer编码器。
在解码器部分,将编码器输出的序列进行reshape然后通过1x1卷积变换通道数之后进行级联上采样,中途通过编码器CNN的各级分辨率特征图进行跳级连接,最后得到分割结果,这部分与U-Net解码器类似。
作者选用CNN-Transformer这一混合结构设计的原因有两点:1)为了将中间高分辨率的CNN特征图加入到解码器路径中以获得更多的信息以及更精确的位置。2)作者发现使用CNN-Transformer编码器要比纯的Transformer编码器效果要好。
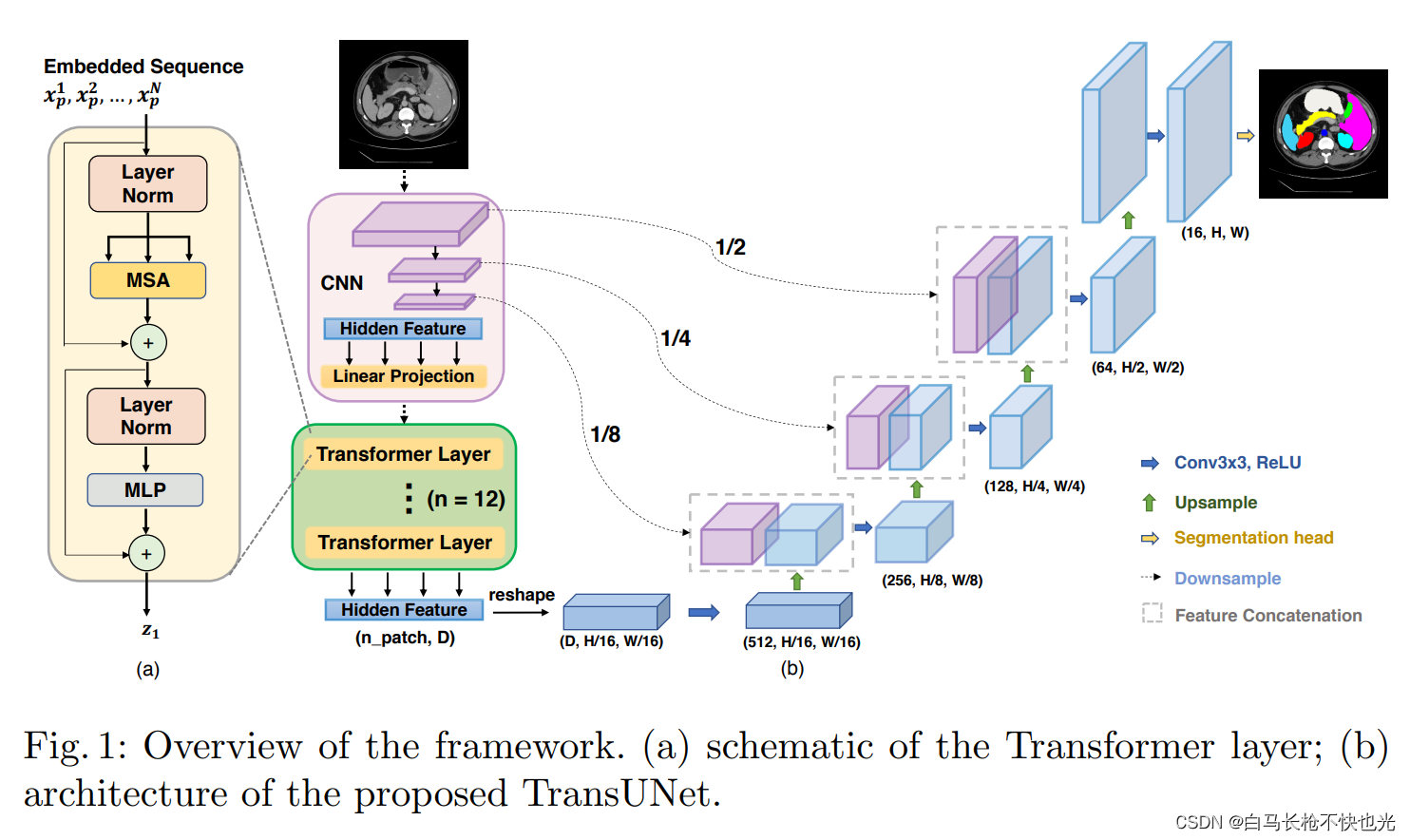
二、TransUNet结构解析
1.Encoder
Encoder部分和CNN-base的UNet不同,这里前三层是CNN-based,选用ResNet50的前三层。最后一层是Transformer-based,选用Vit结构,即12层Transformer Layer。所以Encoder又叫R50-ViT。
注意:为什么只有一层Transformer-based层?
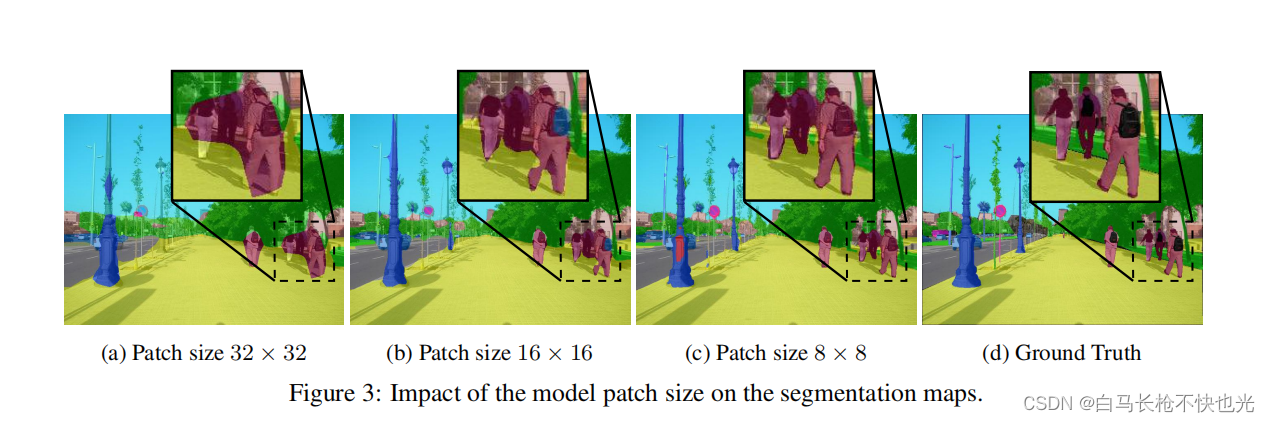
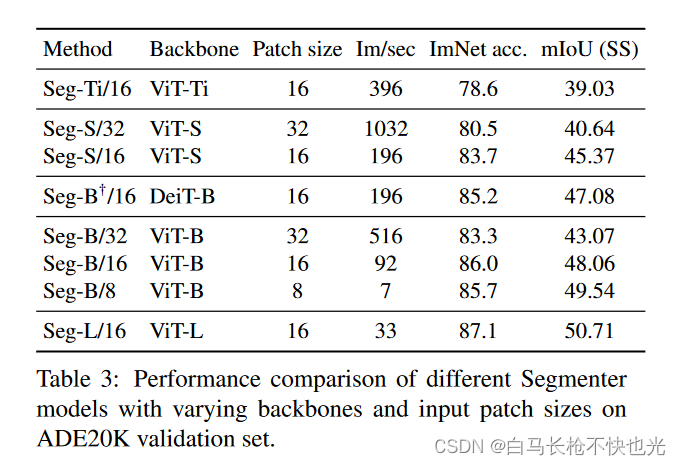
SegFormer:《Segmenter: Transformer for Semantic Segmentation》论文中讨论了patch size大小对于模型预测结果的影响,发现大patch size虽然计算速度更快,但是边缘的分割效果明显很差,而小patch size边缘相对更为精确一些。
得出结论,虽然Transformer能够获得到全局的感受野,但是在细节特征的处理上存在缺陷。而CNN反而是得益于其局部的感受野,能够较为精确恢复细节特征。因此TransUnet模型只替换了最后一层,而这一层则更多关注全局信息,这是Transformer擅长的,至于浅层的细节识别任务则由CNN来完成。
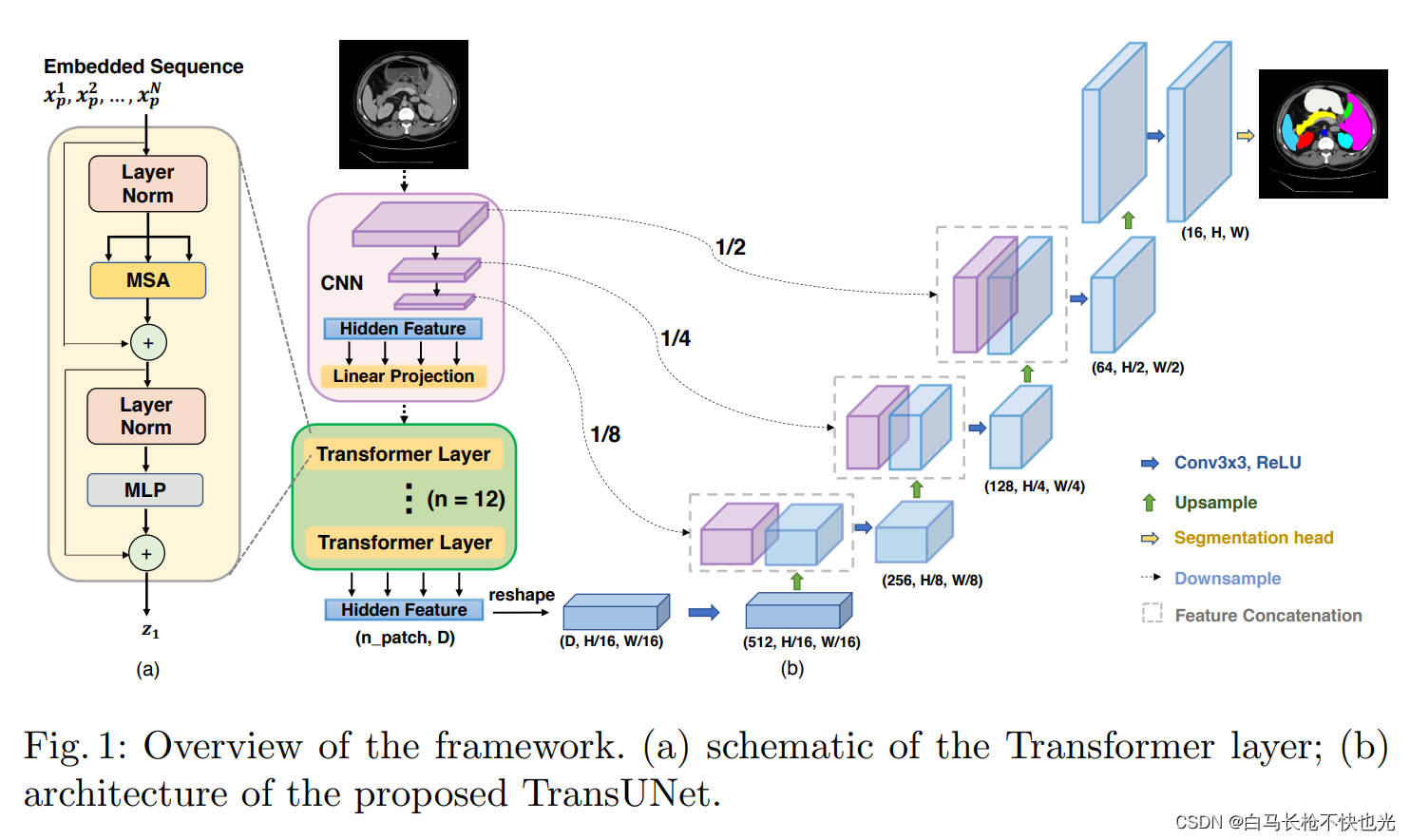
encoder的过程是首先将输入图片经过ResNet50进行特征提取,其中的三个stage的输出将保留,用于之后的skip-connection。接着对于ResNet50输出的特征图,将其进行序列化,送入transformer中进行序列预测,输出一个序列。然后将这个序列合并、reshape成一个新的特征图。
一个直观的序列化操作就是,对于一个H∗W∗C的图片,将每个像素作为一个vector,那么就会得到长度为一个H∗W的sequence,但是这样的话,长度就有点大了。因此,一个新的做法就是,对于一个H∗W∗C的图片,选取N个patch或者说是N个小图,得到长度为N的sequence。假设patch的长度是p,那么N = H ∗ W /(p ∗ p),每个vector中的个数就是p ∗ p ∗ C。
2.Decoder
decoder结构很简单,还是典型的skip-connection和upsample结合。在对transformer encoder部分的输出做处理之后,将其不断上采样的过程中,并不是常规的上采样步骤而是级联的上采样,每个上采样块是常规的上采样、3x3卷积还有relu。
三、实验
提示:我用的是与现在工作相关的TBI的一个公开分割数据集(Seg-CQ500),并非原论中的实验。
1.TBI
颅内出血(ICH - Intracranial hemorrhage):
1. 脑室内出血:Intraventricular Hemorrhage (IVH)
2. 实质内出血:Intraparenchymal Hemorrhage (IPH)
3. 蛛网膜下腔出血:Subarachnoid Hemorrhage (SAH)
4. 硬膜外出血:Epidural Hemorrhage (EDH)
5. 硬膜下出血:Subdural Hemorrhage (SDH)
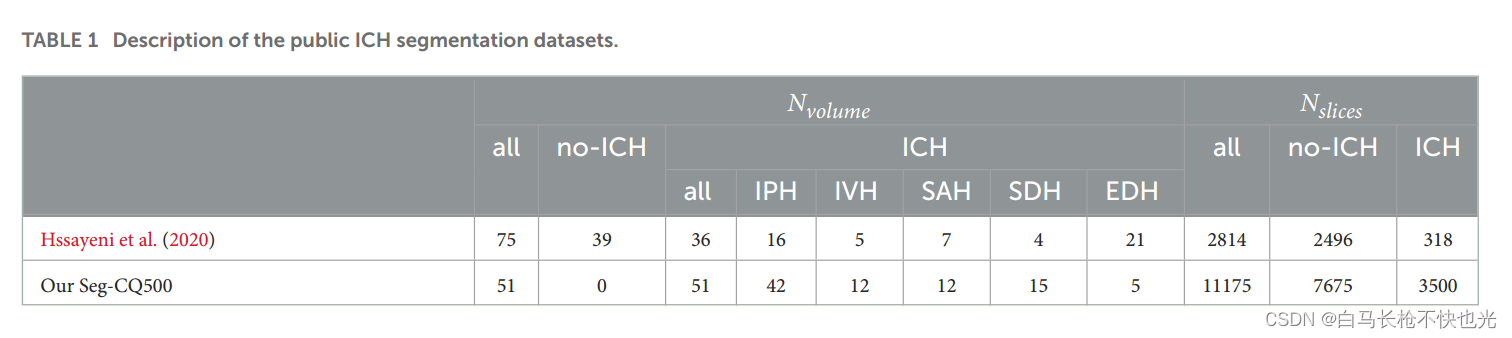
2.Seg-CQ500
目前TBI的公开分割数据集就两个,分别如下图所示。
来自于《Label-efficient deep semantic segmentation of intracranial hemorrhages in CT-scans》
3.实验细节
1.数据集划分:共51位病人,训练集41位病人,共2987张切片;训练集10位病人,共513张切片。
2.实验参数:官方代码给定参数。
3.实验教程:http://t.csdnimg.cn/meyaM、http://t.csdnimg.cn/cpcuJ
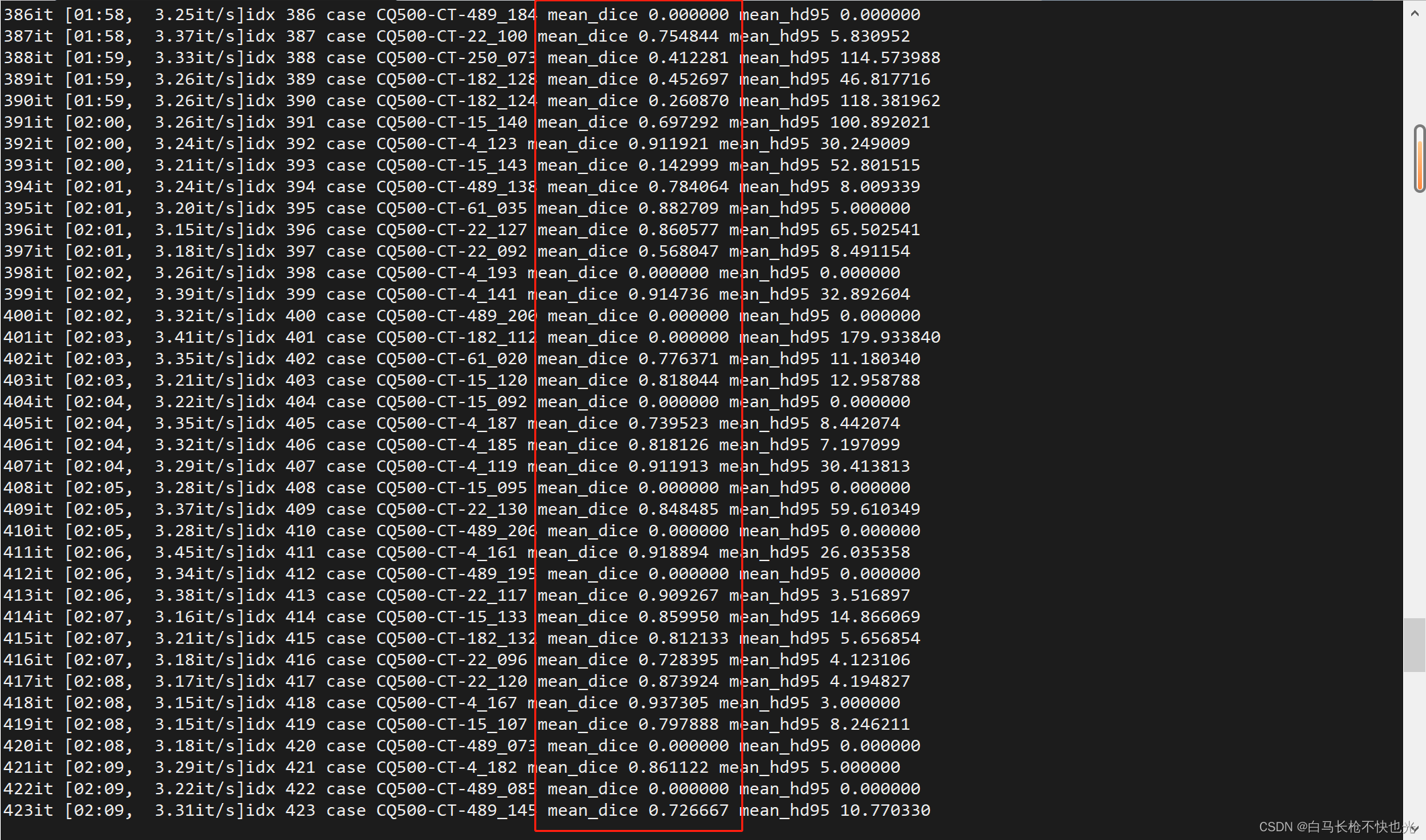
4.实验结果
测试数据的dice如图所示。
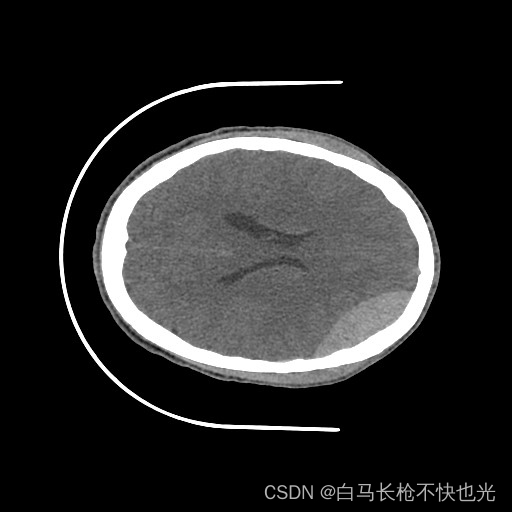
以CQ500-CT-4_167为例,CT切片图、mask、pred分别如下:


四、总结
选择使用TransUNet作为Seg-CQ500数据集的分割模型,主要是在调研过程中,发现TransUNet比SwinUNet更适合于医疗图像的分割。
https://cloud.tencent.com/developer/article/2322917















 2338
2338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









