









论文论文阅读 - A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformers_努力学习中....的博客-CSDN博客社交机器人论文阅读 - A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformershttps://blog.csdn.net/qq_40671063/article/details/126114489A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformers论文阅读 - A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformers_努力学习中....的博客-CSDN博客社交机器人论文阅读 - A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformers
https://blog.csdn.net/qq_40671063/article/details/126114489
介绍的数据集
在过去的几年里,通过社交媒体平台(如 Twitter、 Facebook 或 Instagram)传播错误信息的指数增长促进了应用研究,以便发现并防止这类内容在这些网络中的入侵。因此,很明显,人工智能(AI)在这个话题中扮演着至关重要的角色,以支持这些平台,根据一组特定的描述符或特征,从而自动通知或限制对那些看起来可疑的账户的访问。
举个例子,2019年,推特不得不删除了超过2.6万个账户,因为他们被怀疑传播虚假信息和/或不适当的内容。那么,问题是,人工智能如何支持终端用户检测可疑账户?
该数据集由超过30K行组成,对应于来自Twitter的不同用户帐户。每行包含两列:Tweet ID和指示其类别(bot或human)的标签。
以前的调查和数据集都来自这个机器人仓库(Bot Repository),它专注于这个主题。
该数据集由 37438 行组成,对应于 Twitter 中的不同用户帐户。每行包含帐户的 Twitter ID 和目标变量。
目标变量被表示为account_type,并且具有惟一的值(bot或human)。更具体地说,25013个用户帐户被注释为人类帐户,而其余12425个是机器人帐户。
数据集可以从Twitter Bots Accounts | Kaggle 网站下载,是更新后的账户(删除已经失效了的账户): 。
该数据集是由一组小型数据集组成的,这些数据集来自此前对Twitter可疑账户的调查。更具体地说,这些数据集有Twitter用户账户的标识符列表,以及一个标签,表示该账户是机器人还是人类。为了生成这个数据集,使用标识符在整个Twitter API中搜索和检索用户帐户的数据。因此,提出的数据集是一个更紧凑和更完整的版本,以提高分析。此外,那些不再属于Twitter的帐户将从数据集中删除,其余用户的数据将根据检索时的数据进行更新(13-07-2020)。
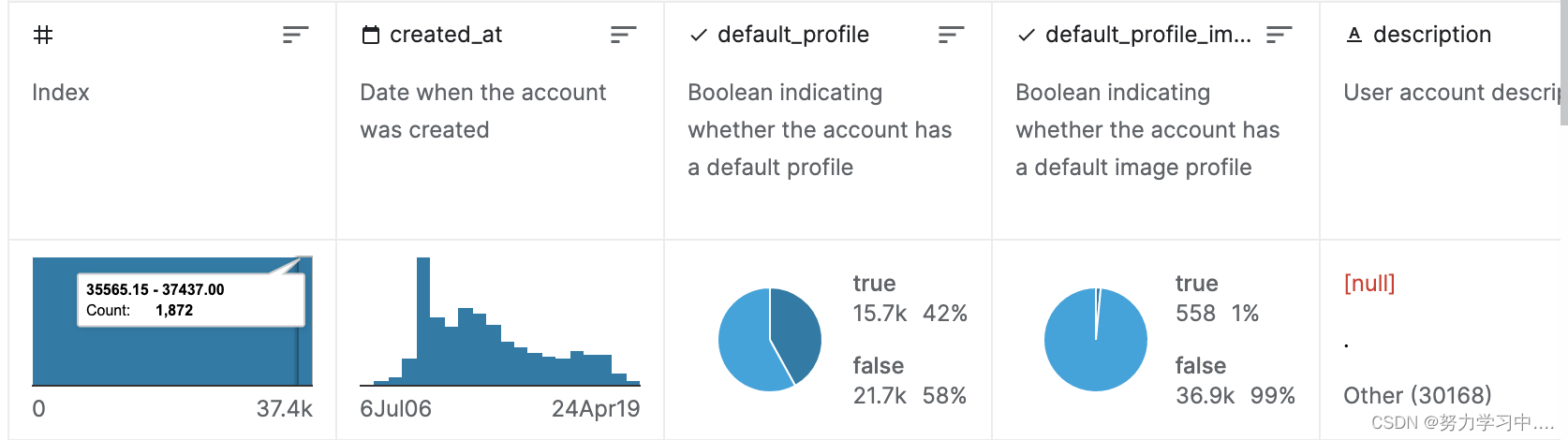
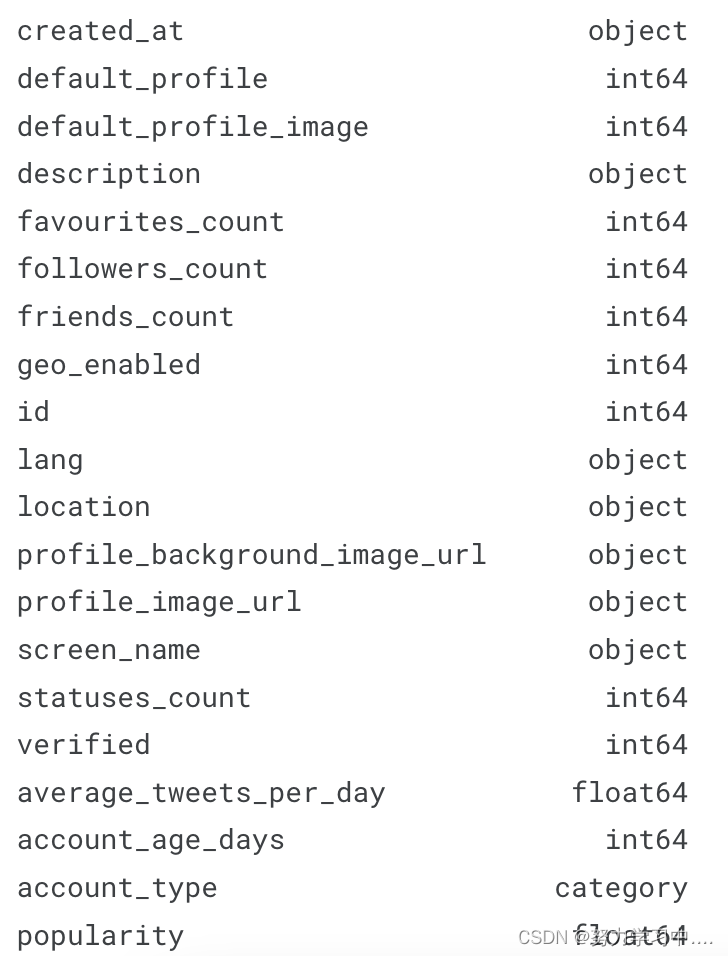
还可以下载经过Twitter API收集后的账户,下载链接为:bots_accounts_eda | Kaggle, 此数据集由37438行组成,这些行对应于 Twitter 中的不同用户帐户。每行包含20列,这些列是通过 Twitter API 收集的特性。
目标变量被表示为account_type,并且具有惟一的值(bot或human)。更具体地说,25013个用户帐户被注释为人类帐户,而其余12425个是机器人帐户。















 4822
4822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









