







 本文提出了一种名为OS-GNN的新方法,用于缓解图神经网络在机器人检测任务中的类不平衡问题。通过在特征空间中为少数类生成节点,OS-GNN避免了传统过采样方法中边生成引入的噪声,提高了少数类的分类性能。实验结果显示,OS-GNN在多个真实世界的机器人检测数据集上表现出色,特别是在提高真阳性率和少数类准确率方面。
本文提出了一种名为OS-GNN的新方法,用于缓解图神经网络在机器人检测任务中的类不平衡问题。通过在特征空间中为少数类生成节点,OS-GNN避免了传统过采样方法中边生成引入的噪声,提高了少数类的分类性能。实验结果显示,OS-GNN在多个真实世界的机器人检测数据集上表现出色,特别是在提高真阳性率和少数类准确率方面。
论文链接:https://arxiv.org/pdf/2302.06900.pdf
目录
摘要
背景:在线社交网络 (OSN) 中大量机器人的存在会导致不良的社会影响。图神经网络 (GNN) 在机器人检测方面取得了最先进的性能,因为它们可以有效地利用用户交互。在大多数情况下,机器人和人类的分布是不平衡的,导致少数类样本代表性不足和次优性能。
gap: 然而,以前基于 GNN 的机器人检测方法很少考虑类不平衡问题的影响。
方法:在本文中,我们提出了一种 GNN (OS-GNN) 的过采样策略,可以减轻机器人检测中类不平衡的影响。与以前的 GNN 过采样方法相比,OS-GNN 不需要边缘合成,消除了在边缘构建过程中不可避免地引入的噪声。
具体来说,首先通过邻域聚合将节点特征映射到特征空间,然后为特征空间中的少数类生成样本。最后,将增强的特征输入 GNN 以训练分类器。
性能:这个框架是通用的,可以很容易地扩展到不同的 GNN 架构中。所提出的框架使用三个真实世界的机器人检测基准数据集进行评估,并且始终表现出优于基线的优势。
1 简介
背景:在线社交网络 (OSN) 为个人提供了一种交流方式,但它已被机器人程序和恶意帐户所侵扰。社交媒体平台上的大量机器人导致了不良的社会影响[Cresci et al., 2017;费拉拉等人,2014]。
前人工作回顾: 在过去的几年中,已经提出了许多机器人检测方法。基于图形的机器人检测方法 [Al-hosseini 等人,2019 年;冯等,2021d; Feng et al., 2021a] 目前是最有效的,因为他们使用图神经网络 (GNN) 有效地利用用户之间的关系 [Feng et al., 2022]。Feng等 [Feng等,2021b] 以特征工程的方式,基于Twitter用户的社交图构建了SATAR。Alhosseini等 [Alhosseini et al., 2019] 首先将图卷积神经网络 (GCN) [Kipf and Welling, 2016] 应用于垃圾邮件机器人检测。此外,一些研究 [Feng et al., 2021d; Feng 等人,2021a] 使用异构 GNN 通过利用多个用户关系进行机器人检测。
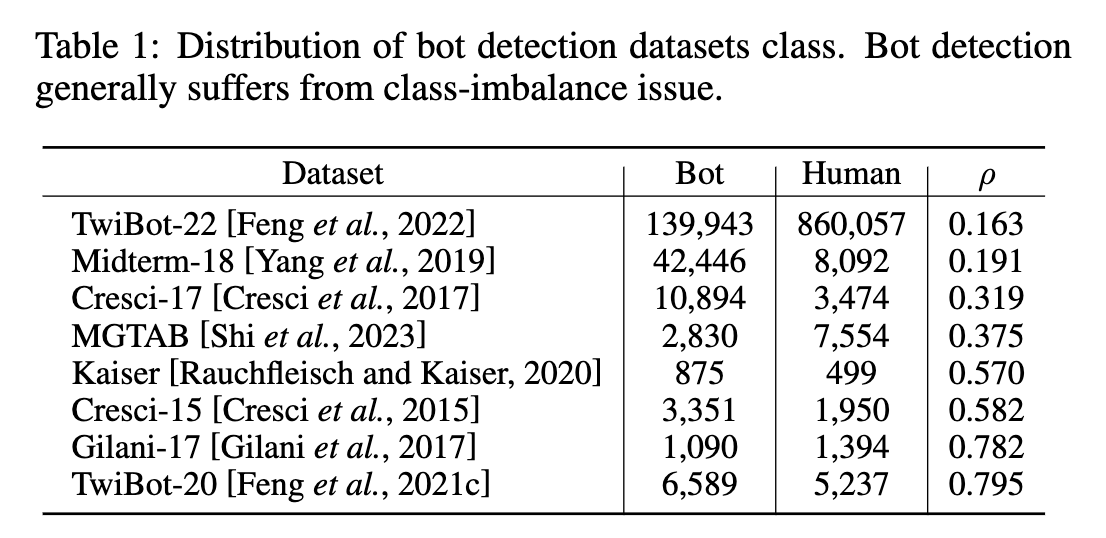
问题分析:在机器人检测中,用户可以分为两类:机器人和人类。用 N 和 M 分别代表多数类和少数类样本数。不平衡率 ρ = M /N 用于衡量类别不平衡。 ρ 取值从 0 到 1,较大的类不平衡度对应较小的 ρ。我们总结了现有的 Twitter 机器人检测数据集,如表 1 所示,在大多数情况下,机器人和人类用户的分布是不平衡的。
尽管类不平衡在机器人检测中很普遍,但以前基于图的检测方法很少考虑它。当模型在不平衡数据上训练时,由于少数类的样本规模不足,很难学习到足够的特征,导致模型倾向于将样本分类到多数类。图 1 显示了 GNN 在 MGTAB [Shi et al., 2023] 和 Twibot-20 [Feng et al., 2021c] 数据集上的机器人检测结果。

(MGTAB 和 Twibot-20 数据集的估计精度。少数类表现不佳并没有反映在整体表现上。)
gap: 考虑到多数类和少数类的准确率,我们观察到一个显着的预测偏差现象:少数类的分类准确率远低于多数类[Hu et al., 2022]。尽管模型的整体准确率很高,但少数类样本分类不佳,尤其是在不平衡程度较大的情况下。
为了减轻类不平衡对机器人检测任务中 GNN 模型的影响,我们引入了一种新方法来为少数类生成节点。我们的方法通过聚合邻域节点来获得包含邻域信息的节点特征。然后,通过特征空间中的过采样生成少数类的合成节点特征。最终,重新平衡后的特征矩阵用于分类。与之前的 GNN 过采样方法(例如 GraphSMOTE [Zhao et al., 2021] 和 SORAG [Duan et al., 2022])相比,省略了节点边的合成。
我们在各种机器人检测基准数据集上验证了我们的方法,包括 Cresci-15 [Cresci et al., 2015]、Twibot-20 [Feng et al., 2021c] 和具有不同 GNN 架构的 MGTAB [Shi et al., 2023] .
实验证实,我们的方法在各种设置上始终优于基线方法。总之,我们的贡献是三方面的:
我们确认以前的 GNN 过采样方法在为合成节点生成边时会引入噪声,从而影响节点分类的性能。此外,我们证明了在少数类的特征空间中进行过采样的可行性;
我们提出了一个新颖的通用框架,它在具有邻域信息的特征空间中生成节点。与以前的过采样方法相比,我们的方法不再需要生成合成少数节点的边。
对真实世界机器人检测数据集的广泛实验证明了我们方法的高效性。与之前的模型相比,我们的方法在少数类的准确性方面有显着提高;
本文的其余部分安排如下。在第 2 节中,我们介绍了必要的定义和 GNN。在第 3 节中,我们介绍了 OS-GNN 并详细展示了该框架的设计方式。我们在第 4 节中提供了 OS-GNN 的理论分析。在第 5 节和第 6 节中,我们展示了我们的实验结果并证明了我们模型的优越性。我们在第 7 节中总结了相关工作,和我们的结论。
2 初步
2.1 符号和问题定义
在这项工作中,我们专注于使用 GNN 进行机器人检测。在大多数情况下,机器人和人类的类规模分布是不平衡的,如表 1 所示。这个问题导致 GNN 分类器偏向于多数类,而低估了少数实例。
令 G = (V, E, H) 表示用户社交图,其中 V = {v1, v2, . . . , vN } 是一组节点。 E ⊆ V × V 是一组边,表示用户之间的关系。 E 包含各种类型的边缘,例如用户之间的朋友和追随者关系。
表示特征矩阵,其中 d 是节点属性的维数。
是 G 中节点的标签。我们将标记节点集表示为
,将合成节点集表示为
。
在机器人检测中,标签通常是通过手动注释获得的。
由于注释成本高,通常我们有 || << |V|。给定类不平衡图 G,我们的目标是为少数类生成节点,减少类不平衡的不利影响,提高少数类的准确性和模型的整体准确性。
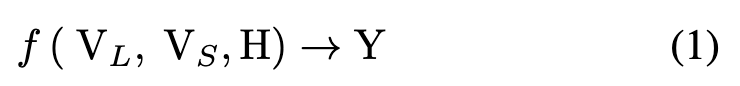
2.2 图神经网络
GNNs 根据图结构学习节点表示,过程可以表述为:
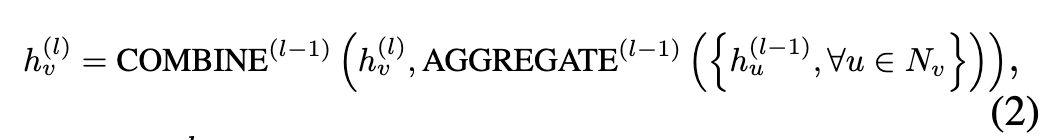
其中 表示节点 v 在第 l 个 GNN 层的特征,
表示节点 v 的邻居集;
使用节点属性
初始化。 AGGREGATE(·) 和 COMBINE(·) 是邻居聚合和组合函数。
聚合函数通常需要是可微的和置换不变的。
3 拟议方法
3.1 动机
现有的 GNN 过采样方法 [Zhao et al., 2021; Duan et al., 2022] 在原始特征空间或嵌入空间上合成节点。由于新生成的节点缺乏连接关系(边),生成节点之间的边也需要在过采样后构建。
实际上,边表示显式关系,例如,用户社交图中的边表示用户之间在关注、评论等方面的关系;
通过边生成器构建边缘只会近似边缘的真实分布,并进一步增加合成数据中的噪声,影响 GNN 的性能。详细证明在第 4 节中。
OS-GNN 的主要思想是在特征空间中为少数类节点生成嵌入,以重新平衡不同类的分布。
图 2 显示了所提出框架的图示。OS-GNN 包括三个步骤:(1) 通过邻域聚合获得节点的嵌入; (2) 通过插值法为少数节点合成embeddings,形成均衡分布; (3) 使用增广图训练 GNN 分类器;
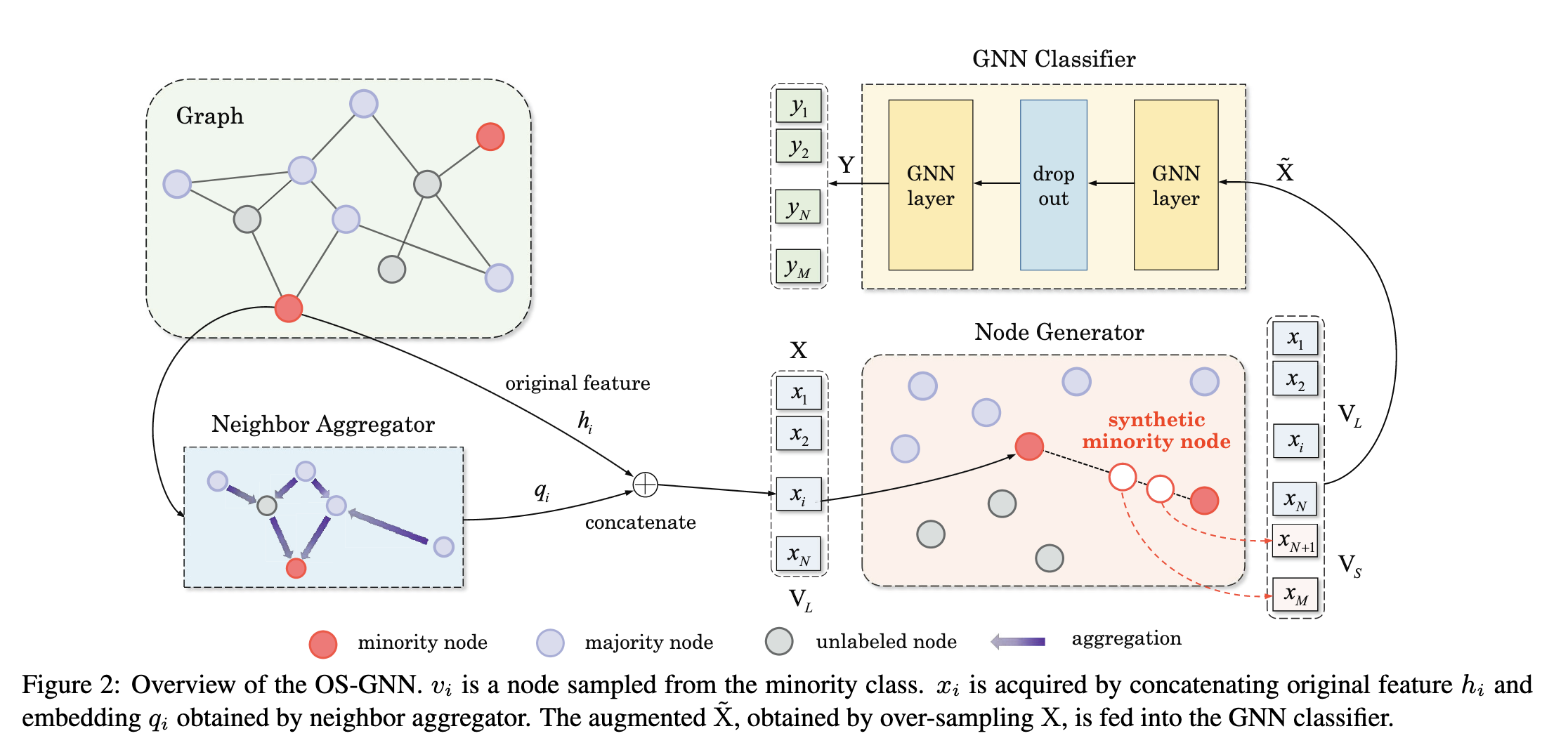
3.2 邻居聚合器
邻域聚合旨在获得具有邻域信息的节点的嵌入。
具体来说,节点 vi 的原始属性是 。具有邻域信息 qi 的表示是通过邻域聚合器获得的。根据研究 [Li et al., 2018],深度 GNN 结构会导致过度平滑和过度拟合。因此,在邻居聚合器中,我们使用 2 跳邻居聚合,即,
,邻居聚合的公式如等式 (2).将
与
拼接得到
,即节点
在特征空间中的表示。
3.3 合成节点生成器
在获得 后,我们应用 SMOTE [Chawla et al., 2002] 生成合成少数节点。通过这种方式,我们可以使不同类的分布更加均衡,使训练好的分类器在最初代表性不足的少数类样本上表现更好.
对于少数类节点 vi,令 Γ(·) 表示特征空间中由欧几里德距离测量的 k 个最近邻的集合。从 中选择一个与 vi 具有相同标签的随机节点
。在
和
之间的直线上随机选择一个点作为
:
![]()
其中 是虚拟节点
在特征空间中的嵌入。 δ 是随机变量,服从均匀分布,取值范围为 0 到 1。
与 vi 和 vu 具有相同的标签。因此,我们获得了标记的合成少数类样本,这些样本均衡了样本分布。
3.4 GNN分类器
设 为特征空间中的增强节点表示,将 X 与合成节点的嵌入连接起来。由于嵌入已经包含邻域信息,因此不需要为合成节点生成边。对于 GCN 分类器,公式如 Eq. (4):
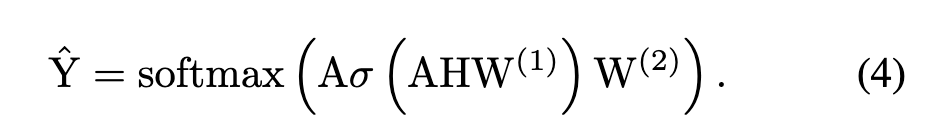
使用单位矩阵E作为GNN分类器f(·)的输入邻接矩阵A。标签和嵌入矩阵 X 被输入到 f(.) 中进行训练。我们的 OS-GCN 的公式,使用 GCN 作为主干,如等式 (5) 所示。
![]()
GNN 分类器的最终目标函数可以写为:
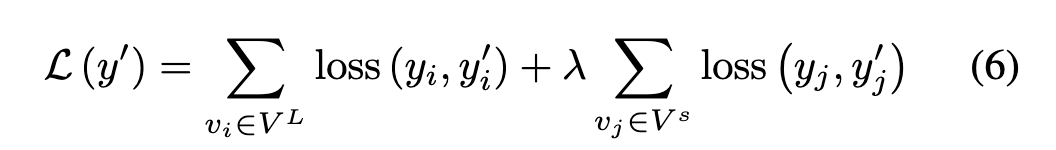
其中 表示节点 vi 的预测标签,λ 是范围从 0 到 1 的参数。损失函数衡量真实标签和预测标签之间的监督损失。分类器可以采用不同的 GNN 模型,整个框架高效且易于实现。算法 1 中提供了 OS-GNN 的完整算法。

OS-GNN 可以扩展到异构 GNN,有效地利用不同的用户关系。具体来说,将不同的关系分别输入到邻居聚合器中,得到,1≤i≤S,S表示使用的关系数。将通过对
过采样获得的
输入到异构 GNN 的第 i 个通道。最后将所有通道的输出相加得到最终的输出。
4 理论基础
4.1 在特征空间中生成节点
首先,我们提供了关于为什么可以在 GNN 的特征空间中生成节点的理论分析。根据 SGC [Wu et al., 2019],GCN 层之间的非线性并不重要,而是图上的邻居聚合。对于两层 GCN 分类器,如方程式(4)所示 去除各层之间的非线性转移函数,得到简化图卷积网络(SGC)分类器:
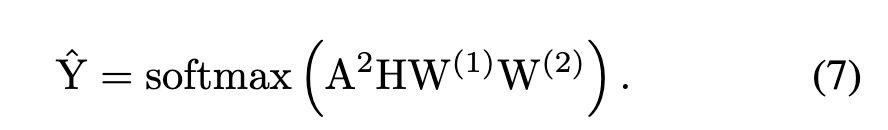
SGC 可与 GCN 的性能相媲美,并且训练时间大大减少 [Wu et al., 2019]。根据等式(7),该模型可以分为两个步骤:邻域聚合和多类逻辑回归。为GCN邻域聚合得到的Q。基于等式 (7)为了保留原始节点信息,我们将Q与原始特征矩阵H拼接得到X。将 Q 替换为X在方程式 (7) 中:
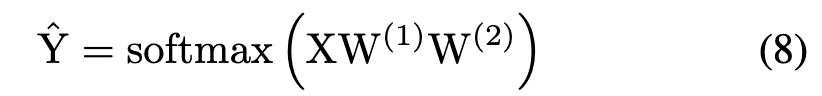
此外,为了增加模型的非线性,我们在参数矩阵 和
之间添加非线性转换函数以获得 OS-GNN(使用 GCN 作为主干),如等式 (5).所示。
4.2 减少边生成的噪声
接下来,我们分析了为什么 OS-GNN 优于之前的 GNN 过采样方法。以前的方法[Zhao et al., 2021; Duan et al., 2022] 使用加权内部产生式来实现边生成器:
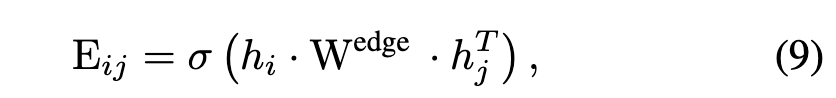
其中 hi 和 hj 分别是 vi 和 vj 的特征向量,Eij 表示它们之间的边。 Wedge ∈ Rd×d 是要学习的权重参数矩阵。
我们设计了一个实验来验证边生成器合成边缘的过程会引入噪声。具体来说,我们使用图中每10%的节点分别作为训练集和测试集。我们使用原始边和预测边测试了边预测的准确性和节点分类的准确性。
我们发现生成边和真实边的分布之间存在差距,如表 2 所示。与原始边相比,使用生成的边进行节点分类的性能有所下降,这证实了边生成过程引入了噪声。 OS-GNN 不需要为生成的节点合成边,降低了噪声,从而提高了性能。
5 实验
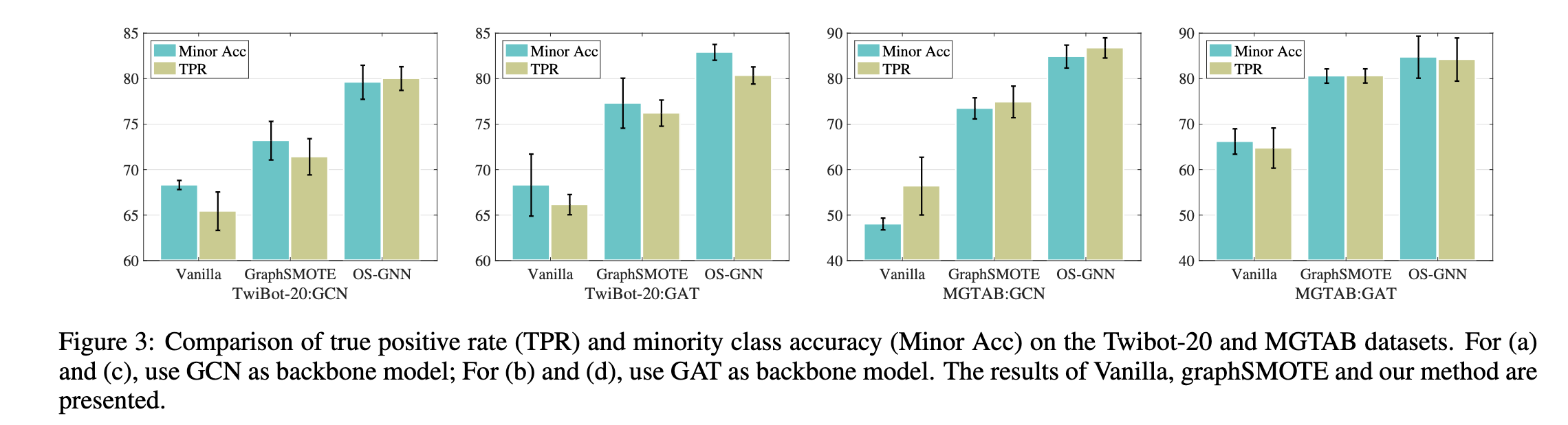
在本节中,我们进行了广泛的实验,以验证所提出的模型对同构 GNN 和异构 GNN 模型的有效性。我们还比较了不同方法的真阳性率(TPR)和少数类准确率(Minor Acc),以更好地理解所提出模型的有效性
5.1 实验设置
数据集 我们在三个具有图结构的 Twitter 机器人检测数据集上评估模型:Cresci-15 [Cresci et al., 2015]、TwiBot-20 [Feng et al., 2021c]、MGTAB [Shi et al., 2023] .我们对所有数据集进行 1:1:8 随机划分作为训练、验证和测试集,并在评估过程中使用最常用的关注者和好友关系。
评估指标 为了评估模型在少数类上的整体性能和性能,我们采用三个标准:精度(Acc)、F1-macro 分数(F1)以及类不平衡节点的平衡精度(bAcc)分类。为了进一步评估少数类数据的性能,我们采用两个标准:真阳性率(TPR)和少数类准确率(Minor Acc)。
Configurations 所有的实验都在一台有 9 个 Nvidia GPU(RTX TITAN,24 GB 内存)的服务器上进行,并使用 Adam 优化算法来训练所有模型。对于所有方法,学习率初始化为 1e-3,权重衰减为 5e-4。此外,训练所有模型直到收敛,最大训练周期为500。对于过采样方法,生成少数类样本,使得数量与多数类相同。 dropout rate 的范围为 0.3 到 0.5,λ 的超参数设置为 0.8。
5.2 基线方法
为了验证我们的方法,我们将我们的模型与使用不同再平衡方法的各种基线方法进行比较。我们考虑了七种基线方法,包括普通方法(交叉熵)、焦点损失 [Lin 等人,2017 年]、类平衡 (CB) 损失 [Cui 等人,2019 年]、DR-GCN [Shi 等人,2020 年] 、RA-GCN [Ghorbani 等人,2021 年]、GraphSMOTE [Zhao 等人,2021 年] 和 GraphENS [Park 等人,2022 年]。
5.3 主要结果
机器人检测性能 我们采用三种广泛使用的同构 GNN 作为主干:GCN [Kipf and Welling, 2016]、SAGE [Hamilton et al., 2017] 和 GAT [Velickovic et al., 2017]。此外,我们选择了两个经典的异构 GNN 作为主干:RGCN [Kipf and Welling, 2016] 和 RGAT [Kipf and Welling, 2016]。在表 3 中,我们报告了基线和我们的标准偏差的平均结果。从表中,我们有以下观察结果:
与没有采用特殊算法的“vanilla”设置相比,所有具有不同主干的 OS-GNN 都显示出显着的改进。在大多数情况下,OS-GNN 在所有数据集中都优于所有基线,证明了我们方法的有效性。
异质 GNN 比同质 GNN 表现更好,因为它们可以利用图中的不同关系。当应用于异构 GNN 时,OS-GNN 在大多数情况下也表现出出色的不平衡处理性能。
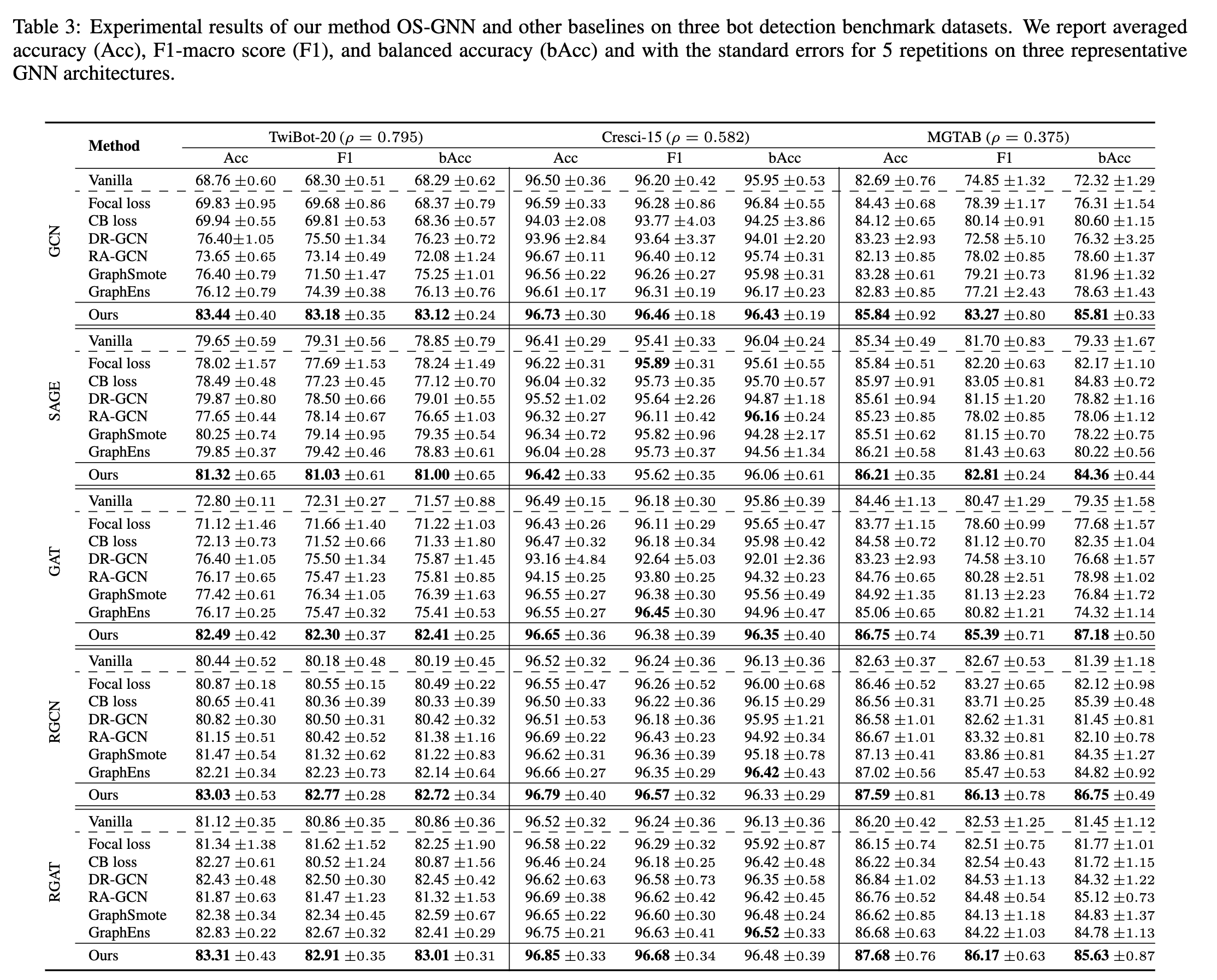
在所有数据集中,OS-GNN 在 Cresci-15 数据集上取得了较小的提升。这是由于 Cresci-15 中的边对于节点分类不重要,反映在异构 GNN 中仅略优于同质 GNN;
提高真阳性率 在图 1 中,我们观察到少数类的分类非常低,因为模型的分类边界“侵占”了少数类的区域。从表 3 可以看出,OS-GNN 与基线模型相比,bAcc 有了显着提升。为了验证 OS-GNN 通过减轻误报问题来提高 GNN 的性能,我们计算了模型的 TPR 和 Minor Acc。如图 3 所示,OS-GNN 在不依赖 GNN 架构的情况下稳步增加 TPR 和 Minor Acc。
6 讨论
6.1 不平衡率的影响
为了评估我们提出的方法的稳健性,我们分析了 OS-GNN 在不同不平衡率方面的性能。对于所有数据集,训练集、验证集和测试集的比例与5.3节一致。我们通过子图采样将不平衡率设为{0.05,0.1,0.2},结果如表4所示。
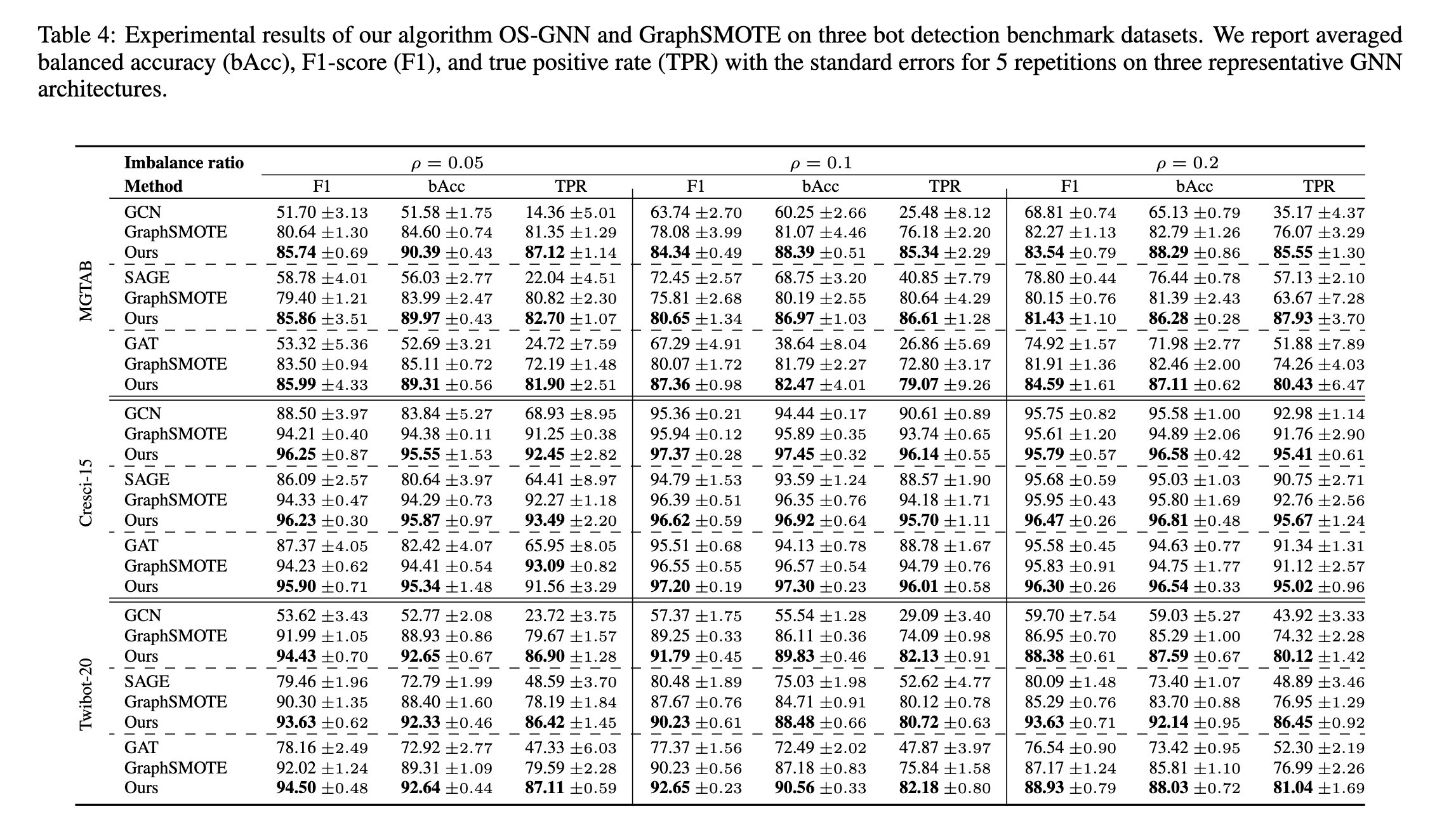
少数类实例的分类结果受到类不平衡问题的严重影响。我们观察到当不平衡程度增加(ρ 减少)时性能下降,尤其是 TPR。所提出的 OS-GNN 使用不同的 GNN 结构可以很好地泛化到不同的不平衡率。它在所有设置上都优于基线,这显示了 OS-GNN 在各种场景下的有效性。
6.2 参数敏感性分析
我们评估了 OS-GNN 在方程式 (6) λ 的不同设置下的性能。.具体来说,我们将 λ 从 0.1 更改为 1.0,每个实验进行五次,平均结果如图 4 所示。
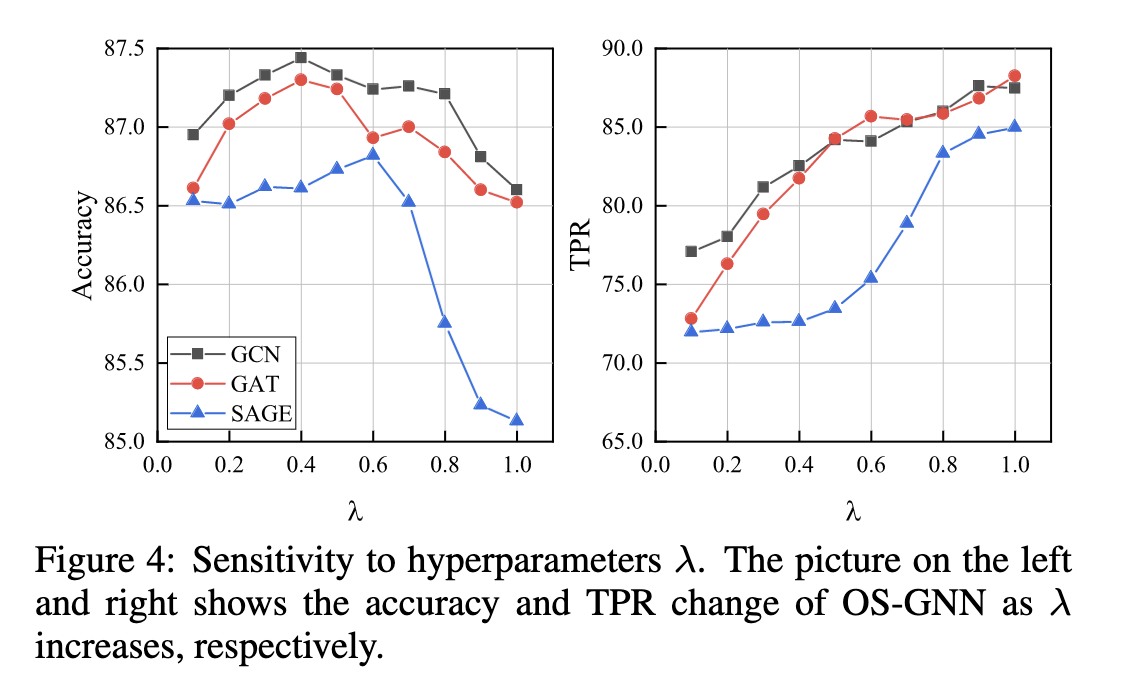
显然,我们的方法对 λ 的设置很敏感。随着 λ 的增加,精度先增加然后下降。 λ控制损失函数中合成的少数类样本的权重。随着λ的增加,模型更加关注合成少数样本,从而使TPR不断提高。但是,过多的λ使得模型过多地集中在合成样本上,降低了大多数类样本的性能,从而影响了整体的分类精度。
6.3 方法的局限性
尽管 OS-GNN 已被证明在多种情况下比其他竞争性不平衡处理方法取得了显着更好的性能,但我们也注意到了一些局限性。首先,OS-GNN 使用 SMOTE 生成少数类样本。在过采样过程中,不考虑多数类样本的分布。此外,当图中的边不是必需的时,OS-GNN 比以前的过采样方法改进得更少。因为,在这种情况下,边之间的信息较少,从而没有充分体现消除边构造的优势。
7 相关工作
7.1 Twitter 机器人检测
机器人检测方法可以大致分为基于特征和基于图形。基于特征的方法 [Cresci 等人,2017 年;费拉拉等人,2014 年;戴维斯等人,2016 年; Cresci et al., 2015] 提取用户身份特征来训练分类器,例如关注者和朋友的数量、推文数量、帐户创建日期等。然而,冯等人 [Feng et al., 2022] 表明利用用户身份特征来检测机器人可能不准确,因为它们没有考虑用户之间的关系。为了解决上述问题,基于图的机器人检测方法[Alhosseini et al., 2019;已经提出使用 GNN 来有效地利用用户之间的交互。
类不平衡问题在许多现实世界问题中普遍存在,机器人检测任务也存在。以前基于 GNN 的机器人检测方法 [Alhosseini 等人,2019 年;冯等,2021d; Feng et al., 2021a]的设计基于类分布大致均衡的假设,没有考虑类不平衡的负面影响。严重不平衡的数据自然会在分类器中产生“标签偏差”,其中决策边界可能会被多数类彻底改变 [Yang 和 Xu,2020]
7.2 图的不平衡处理
解决图数据中类不平衡问题的现有方法可以分为两类:重新加权和重新采样。
重新加权是解决类别不平衡问题的一种简单但有效的解决方案,它根据训练阶段的标签大小调整样本的权重[Cui et al., 2019;林等人,2017]。
一些研究将重新加权方法应用于图形场景。
RA-GCN [Ghorbani et al., 2021] 提出以对抗训练的方式自动学习对不同类别的训练样本进行加权。
Boosting-GNN [Shi et al., 2021] 通过利用提升和重新加权处理节点分类任务的类不平衡问题。
Renode [Chen et al., 2021] 根据节点与类边界的相对位置重新加权节点的影响。
Song等人 [gyun Song等人,2022] 根据与连接性模式的偏离程度设计损失函数,以合理地调整边缘节点。
再抽样方法通过抽样策略来重新平衡不同类别的分布,以增加少数类别的数据。
在重采样方法中,SMOTE [Chawla et al., 2002] 是一种广泛使用的方法,通过混合最近的少数类数据来合成少数类数据。
最近,一些工作在类不平衡节点分类中使用了重采样方法。 DR-GCN [Shi et al., 2020] 生成虚拟少数类节点并强制它们与源节点的邻居相似;
菲奥雷等人 [Zhao et al., 2021] 提出了 GraphSMOTE,它为少数类节点合成新样本,然后使用边生成器生成节点之间的链接;
基于 GraphSMOTE,SORAG [Duan et al., 2022] 通过条件 GAN [Mirza 和 Osindero, 2014] 生成标记和未标记节点,并将过采样方法进一步扩展到多标记图。
GraphENS [Park et al., 2022] 通过邻居采样将次要节点与其他类节点混合,生成不同的次要节点。
不同于以往的过采样方法[Zhao et al., 2021; Duan et al., 2022] 首先生成节点然后构造它们的边,我们的过采样策略可以消除边的构造,从而避免在边的生成中引入噪声并减少计算量。
8 结论
在本文中,为了解决机器人检测中的不平衡挑战,我们提出了一种高效且有效的方法 OS-GNN,它在特征空间中为少数类生成嵌入。与现有的图过采样算法相比,OS-GNN 通过消除边构造来降低噪声并提高效率。我们进行了广泛的比较研究,以评估在多个机器人检测基准数据集上提出的框架。实验结果证明了 OS-GNN 在处理不平衡数据方面的有效性。















 1588
1588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









