







论文链接: https://arxiv.org/pdf/2303.03697

目录
摘要
预训练语言模型的最新进展为大规模生成类人文本提供了方便的方法。尽管这些生成能力在突破性应用方面具有巨大潜力,但它也可能成为对手生成错误信息的工具。特别是,像推特这样的社交媒体平台非常容易受到人工智能产生的错误信息的影响。
论文主要研究问题:
一个潜在的威胁场景是当对手劫持了一个可信的用户帐户,并在公司内部使用自然语言生成器来生成错误信息。这种威胁需要在给定用户的推特时间轴上对人工智能生成的推文进行自动检测器。然而,推文本身就很短,因此,目前最先进的基于预训练语言模型的检测器很难准确地检测到人工智能在给定的推特时间轴上从什么时候开始生成推文。
论文的主要工作:
作者提出了一种使用风格测量信号来帮助检测人工智能生成的推文的新算法。
在两个相关的任务中提出了相应的模型来量化人类和人工智能推文的风格变化:任务1 -区分人类和人工智能生成的推文,
任务2 -检测人工智能是否以及何时在给定的推特时间线中开始生成推文。
广泛的实验表明,文体特征是有效的,以增加最先进的人工智能生成的文本检测器
1 Introduction
背景:
随着NLG的发展,出现了一个研究问题:人工智能生成的文本能否被自动检测。这主要是因为NLG模型可以在预训练语言的支持下生成语法准确的大量文本。从而为潜在的社会和伦理问题让路。攻击者可以将这些模型与恶意意图结合起来,并产生可能导致伤害和混淆的文本。点击诱饵标题、深度推文和人工智能生成的假新闻等例子显示了潜在的威胁。
Twitter等社交网络是对手在公司内部(如人工智能文本生成器)大规模生成错误信息的理想场所。例如,对手可以在社交媒体上部署机器人,配备文本生成器来传播人工智能生成的错误信息,甚至发起大规模的误传活动。
新威胁场景:
在本文中,作者考虑了如图1所示的新威胁场景,描绘了可信用户帐户的Twitter时间轴,以及作者如何从人类(可信用户)转变为AI (NLG)。

(图1:一个假设的例子,一个可信的新闻推特账户被劫持并产生错误信息)
一个真实的Twitter账户被恶意用户入侵,然后植入人工智能文本生成器来生成错误信息。这些类型的恶意人对人工智能的作者变更的严重性是双重的:1)可信的账户拥有大量的追随者,因此错误信息的传播率很高;2)引人注目的类人人工智能推文以前所未有的速度生成。因此,为了识别这种威胁,至关重要的是要有一个自动机制来检测Twitter上人工智能生成的推文。此外,检测人类到人工智能的作者变化发生的点对于数字取证和未来的威胁缓解至关重要。
文献中有许多方法可以自动检测人工智能生成的文本,其中最成功的方法是使用plm[5,29]。然而,结合最先进的(SOTA)基于plm的分类器来检测Twitter时间轴中人类与人工智能作者的变化尤其具有挑战性,原因有两个:
1)输入文本的语义信息较少。Tweets本身长度较短,当输入文本长度较小时,语义信息量不足时,PLMs的分类准确率会下降。
2)生成监督学习的训练数据。基于plm的分类器需要充分的微调以适应手头的任务。这个问题中的训练数据将由Twitter时间轴组成,每个时间轴包含一系列人类和人工智能生成的推文。生成这种人工智能生成的Twitter时间轴是一项消耗资源的任务。为了解决这些挑战,作者提出了一个简单而有效的架构,使用风格特征作为辅助信号来检测Twitter时间线中的人工智能推文。
作者的方法:
作者分析了不同类别的文体特征,并设计了一套全面的实验讨论文体学如何在不同的配置中增强人工智能生成的文本检测性能,例如,人工智能生成器的大小、tweet主题等。此外,作者提出了一个简单的基于风格特征的变化点检测架构,以检测是否以及何时在用户的时间轴上发生了人类到人工智能的作者变化。
这种方法由很少的可学习参数组成,即使只有很少的训练时间轴样本也能很好地工作。综上所述,作者研究了以下两个研究问题:
RQ1:当从时间轴检测人工智能生成的推文时,文体特征是否可以提高SOTA文本检测器的性能?
RQ2:在训练数据有限的情况下,风格特征是否能够很好地检测到用户的Twitter时间轴上是否发生了从人到人工智能的作者变化?
实验:
在两个数据集上评估风格体系结构:一个是内部数据集,用于模拟用户Twitter时间轴中人类到人工智能作者的变化,另一个是公开可用的数据集TweepFake。
在这两个数据集上的结果表明:1)当Twitter时间轴长度较小时,文体特征显著改善了现有基于plm的人工智能生成的文本分类器;
2)文体信号有助于检测Twitter时间轴中何时发生作者变更,主要是在训练数据有限的情况下。
2 Related Work
推特上的机器人检测。Twitter上有大量关于机器人检测方法的工作。大多数bot检测方法使用用户账户特征(如关注者数量、点赞、转发等)或时间特征(如活动)[4,6,15,22]。与标准的机器人检测方法不同,作者的目标是纯粹使用Tweet序列的原始文本,并识别语言模型是否生成序列中的文本。因此,不会将方法与机器人检测基线进行比较,而是专注于人工智能生成的文本检测工作。
人工智能生成文本检测。对生成文本检测的初步研究结合了词袋和tf-idf编码等技术,然后是逻辑回归、随机森林和SVC等标准分类器[10]。近年来[29]显示了暴露偏差对大型语言模型生成的文本检测的影响。因此,随后的工作使用预训练的语言模型架构(BERT、RoBERTa、GPT-2等)作为检测器,并在检测许多人工智能生成的文本方面显示了最先进的结果[8,19,21,24]。 同样,经过微调的基于roberta的检测器在检测人工智能生成的推文方面也显示出显著的性能[5]。最近在生成文本检测方面的一些工作进一步尝试用新的学习范式(如基于能量的模型(EBM)[1])和额外的信息(如事实结构和拓扑[16,30])来扩展基于plm的检测器。在最近的一项工作中,作者采用了文本增强技术来提高Twitter中人工智能生成文本的检测性能[26]。
人工智能生成文本检测的文体学。Schuster等人[19]表明,在试图区分人工智能生成的真实新闻和人工智能生成的假新闻时,文体学的用途有限。相比之下,本文中的目标是使用文体学来区分人类编写的文本和人工智能生成的文本。这是第一个结合几何测量来区分人工智能生成的文本和人类书写的文本的工作。然而,文体学是一种成熟的工具,用于许多领域的作者归属和验证,包括Twitter[2]。或者检测文档中的风格变化,利用不同的风格线索来识别给定文本的作者身份,并在多作者文档中找到作者的变化[9,28]。
此工作与这些不同之处在于,虽然它们在多作者文档中检测人类作者的变化,但在给定的Twitter时间轴内测量人类到人工智能作者的变化。然而,潜在的假设是相似的。PAN[28]是一系列关于数字文本取证和测量的科学事件和共享任务。在过去的几年里,PAN研究了文体学的多种应用,以检测多作者文档中的风格变化。几个显著的例子是基于bert的模型[11],以及包含风格特征的集成方法[25]。
3 Preliminaries
为了解决研究中的研究问题制定了以下两个任务:1)Human vs. AI Tweet检测和2)Human- To -AI Author Change检测和定位。将这些任务正式定义如下:
1)人工与人工智能的推文检测。在这个任务中,要检测一个tweet序列是由语言模型生成的还是由人类作者编写的。形式上,输入是Tweet序列![]() =
=![]() 由特定用户u的时间轴按时间顺序排列的N条tweet组成。给定这个输入,学习一个检测器函数fθ,这样
由特定用户u的时间轴按时间顺序排列的N条tweet组成。给定这个输入,学习一个检测器函数fθ,这样![]() 其中1表示每条tweet在
其中1表示每条tweet在![]() 是AI生成的。0表示每条推文都是人写的。注意,对于N = 1,这个任务只是Tweet分类。
是AI生成的。0表示每条推文都是人写的。注意,对于N = 1,这个任务只是Tweet分类。
2)人到AI作者变更检测与定位。在这个任务中,假设输入是一个混合的Tweet序列,即一些Tweet是人工智能生成的,而另一些是人工编写的,并且假设序列中只有一个点发生了作者从人类到人工智能(即基于plm的文本生成器)的变化,想要定位发生这种变化的位置/ Tweet。形式上,与前面的任务类似,输入是来自用户u的时间轴的按时间顺序排列的N条推文集合:![]() ,给定这个时间轴作为输入,学习一个函数gθ
,给定这个时间轴作为输入,学习一个函数gθ![]() ,其中j∈[1,N]是作者发生变化的有序集合中Tweet的索引。
,其中j∈[1,N]是作者发生变化的有序集合中Tweet的索引。
4 Methodology
4.1文体特征
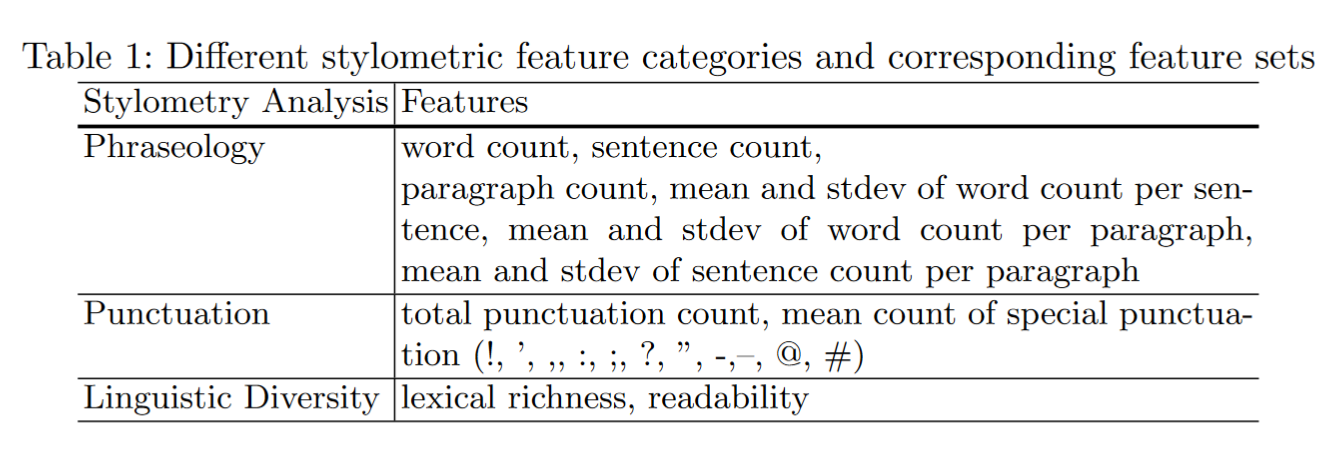
文体特征旨在从给定的文本中指出不同的文体信号。遵循先前的文体学工作,以检测文学文本的写作风格变化.在这个分析中,使用了三类特征:
1)措辞学——这些特征量化了作者在创作一段文本(例如,平均单词,发送)时如何组织单词和短语,句子数等),
2)标点符号-量化作者如何使用不同标点符号的特征(例如,平均独特标点计数)
3)语言多样性-量化作者在写作中如何使用不同词汇的特征(例如,丰富性和可读性得分)。
表1总结了在三种风格特征类别下使用的完整特性集。
短语和标点符号特征集的计算直观。然而,作者也考虑了语言多样性的两个复杂特征:词汇丰富性和可读性。
通过计算移动平均类型-标记比率(MTTR)度量来衡量给定文本的丰富度[3]。
MTTR在固定大小的移动窗口(单词序列)中包含唯一单词的平均频率来测量词汇多样性。
对于可读性,使用完善的Flesch Reading Ease指标[14],该指标为给定文本输入的可读性分配了0-100之间的分数。
4.2 在人工与人工智能撰写的推文检测中使用文体学
遵循与当前文献类似的设置,其中人工智能生成的文本检测通常被处理为标记为0和1(“人类编写”和“人工智能生成”)的二元分类任务[12]。作者将速率风格特征作为辅助信号来增强当前的SOTA检测器。如图2a所示,提出的融合网络将PLM的语义嵌入能力与风格特征相结合。
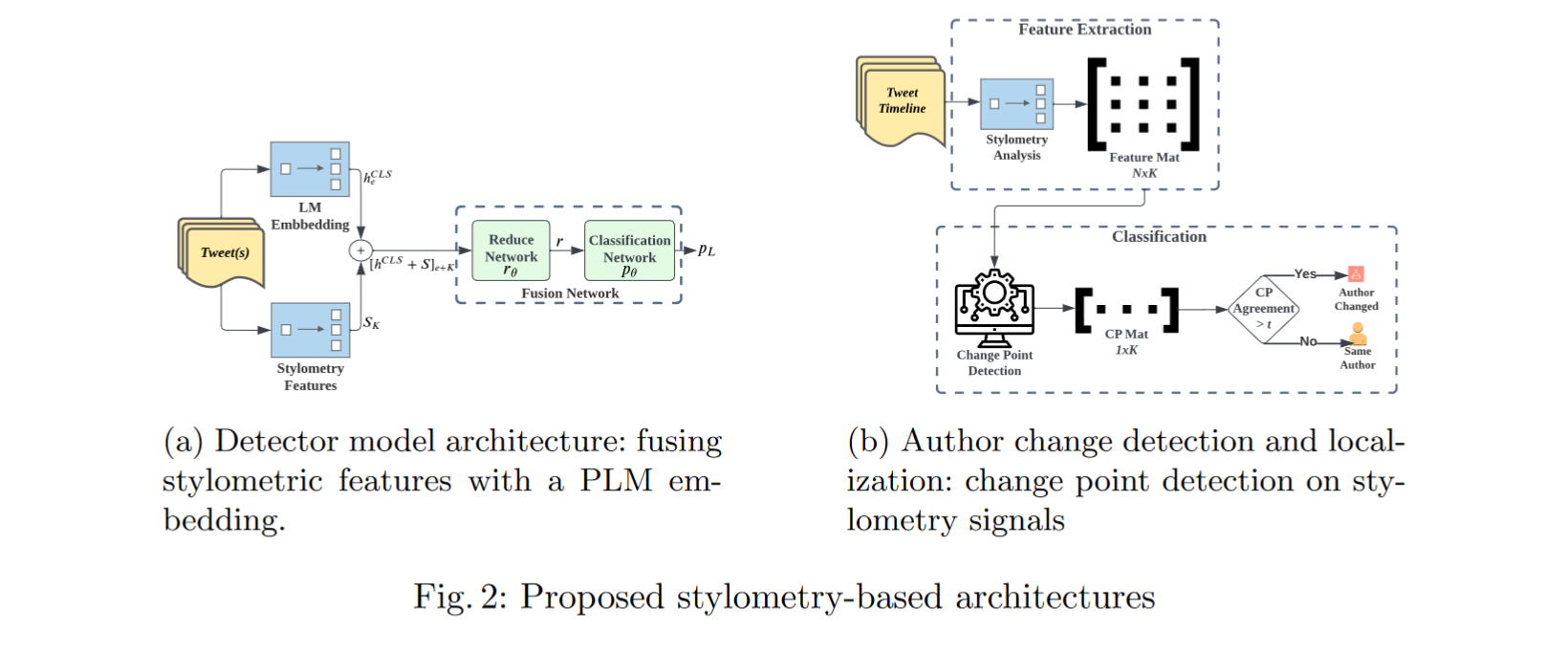
对于每一组输入Tweets,计算规范化的风格特征并提取基于plm的文本嵌入。用来表示风格特征K是特征的个数。用h表示,提取对应于CLS token的向量
()作为文本表示(e是嵌入大小). 在连接两个向量
之后,通过reduce网络传递它们。Reduce网络由i个全连接层组成,学习
函数.最后,将表示向量r传递给分类网络(j个全连接层的组合,后面是一个softmax层),以产生最终的分类概率
![]() . 这里L是分类任务的标签。通过交叉熵损失训练完整的融合网络。
. 这里L是分类任务的标签。通过交叉熵损失训练完整的融合网络。
4.3在人机作者转换中运用文体学检测与定位
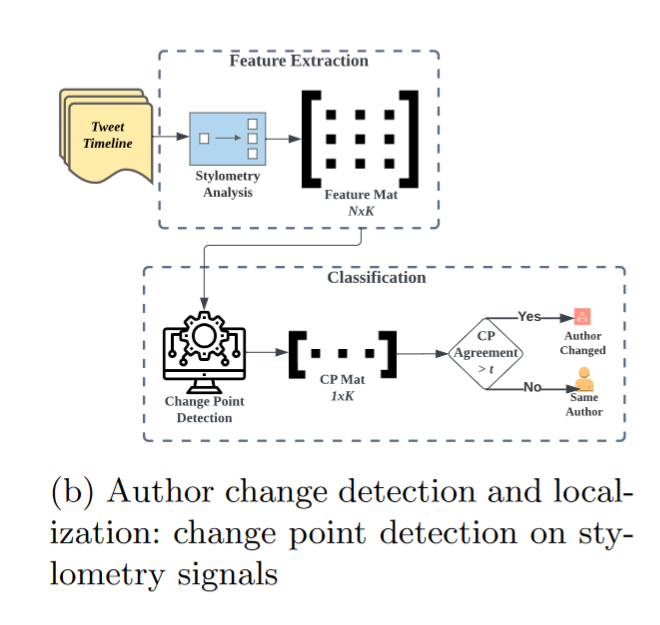
对于人类到人工智能的作者变化检测和定位任务,假设当作者在Twitter时间轴上从人类变为人工智能时,文本的风格很可能会发生重大变化,这应该会在文体学信号中留下分割。因此,建议在文体特征中加入变化点检测来检测作者是否发生了变化。首先,简要地描述了变更点检测的任务:
变更点检测。在时间序列分析中,变化点被定义为时间序列中发生突变或统计变异的时间点。这种突然的变化可能表明系统中的状态转变。各种汇总统计用于确定时间序列中是否存在潜在的变化点,例如平均值、标准差或局部趋势斜率的变化[27]。在这项工作中,使用了Pruned Exact线性时间(PELT)算法用于检测数据中的变化点。
文体学信号的变化点。如图2b所示,首先提取Twitter时间轴的文体矩阵。这里,一个时间轴由N条推文组成,使用的风格特征的数量是K。这种计算得到N个长度K的风格时间序列。对于这K个时间序列中的每一个,运行PELT分析,以确定是否存在任何变化点. 最后,如果K个文体特征中有γ %同意存在一个变化点,那么就说在给定的时间轴内存在作者的变化。百分比值γ是一个超参数,称之为变化点一致阈值。将定位点定义为在上述γ %的文体特征中最一致的变化点指数。如果特征之间不一致,则从文体特征识别的定位点中随机选择一个定位点。为简单起见,将在接下来的部分中称这个整体方法为“风格变化点协议(StyloCPA)”
5 Experiments
在这两个任务下进行了全面的实验,以探索所提出模型的有效性.
5.1 Datasets
内部数据集:研究设计要求构建人类和人工智能撰写的推文的序列或“时间表”。为此,需要一组人工撰写的推文和一组人工智能生成的推文。
对于人类撰写的推文,作者使用了两个公开的特定主题数据集(抗疫苗和气候变化)。还使用Twitter API收集了有关Covid-19的推文。请注意,虽然这个收集过程可能会潜在地将一些人工智能生成的推文引入到人类推文收集中,但这些推文足够重要,以至于扭曲如此大数据集的结果。
使用huggingface实现gpt2、gpt2-medium、gpt2-large和EleutherAI-gpt-neo-1.3B[7]来生成推文。使用收集的人工撰写的推文对这些plm进行了微调,以便生成的推文与人工撰写的样本中的推文的风格和主题相匹配。在微调过程中,保留了一个单独的验证集来测量困惑度,并执行早期停止以确保模型的生成质量。
作为次要措施,还对生成的推文进行了抽查,以观察生成的推文是否质量良好. 为了构建人类创作的时间线,查询了人类tweets的集合,查找单个用户创作的N条tweets. 这一组N条推文随后被定义为人工撰写的时间线。类似地,为了建立一个人工智能生成的时间线,从给定的NLG的推文中抽取N条。在分析中,改变了时间线长度(N∈{1,5,10,20}),以了解其对性能的影响。
使用上面概述的过程,对于每个N,构建M个时间线,其中M = 5000/N。虽然时间线的数量随N的变化而变化,但语义信息的量在不同N的情况下保持不变。对于变化点检测和定位分析,需要“混合”时间线,即看到人类到ai作者变化的tweet序列。
为了构建每个混合时间线,如上所述,对N-l个人工创作的推文(关于同一主题)进行采样,并将l个人工智能生成的推文(在同一主题上进行微调)连接起来。对于本文报道的定位结果,固定N = 25,变化l∈[1,N−1].重复这个过程,得到了250条不同的时间线。将按照以下方式协助再现数据集:1)发布用于提取tweet内容的所有tweet-id(或tweet-id的来源),并且
2)概述如何生成人工智能生成的推文的步骤.
TweepFake:作为一个比较点,还将方法应用于公共TweepFake数据集[5],该数据集是为人类与人工智能撰写的推文检测而设计的。有关此数据集及其构造的更多信息,请参见[5]。请注意,对该数据集的分析与N = 1的内部数据集相当。
5.2 Experimental Settings
由于已知微调的RoBERTa模型在生成文本检测方面表现良好[5,24],选择使用RoBERTa作为在人工与人工智能撰写的推文检测任务中的风格融合架构的语言模型。在提取融合模型的嵌入之前,RoBERTa对训练数据集进行了微调。根据一个早期停止标准来决定训练周期的数量,其中验证损失是在5%的保留集上计算的。
在推理期间,对于TweepFake和内部数据集(N = 1),模型的输入是一条单独的tweet。但是,对于时间轴长度N > 1的情况,使用换行分隔符附加时间轴中的所有tweet,以创建单个输入文本.
对于人类到AI作者的变更检测和定位任务,使用了方法学部分中描述的StyloCPA模型。为了选择一致阈值γ,在γ值范围内进行网格搜索,发现γ = 0.15导致最佳的整体定位精度.

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









