






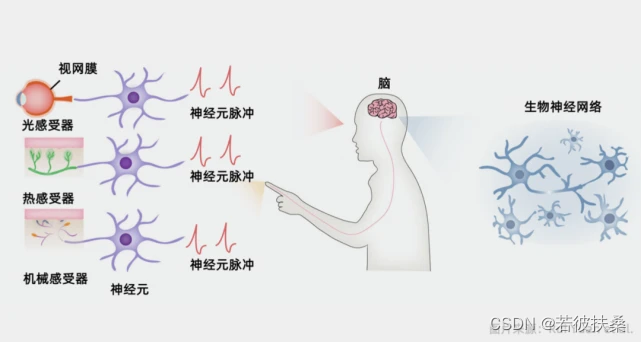
大脑以神经脉冲作为基本信息形式进行工作。视网膜将光刺激转化为神经脉冲,我们就有了视觉。当挥发的分子转化为神经脉冲,我们就闻到了气味。当神经末梢将触觉压力转化为脉冲时,我们就有了触觉。脉冲神经网络采用脉冲神经元作为基本单元,具有一定的仿生性。脉冲神经网络的输入为神经脉冲,但是实际输入的信息通常为图片、语音等形式,因此在信息输入前需要进行脉冲编码。
人脑具有最顶尖的脉冲编码技术,可以利用小容量、低功耗神经系统,编码出各种各样的感觉、记忆、想象等功能。然而,目前,人脑具体的神经编码机制尚不明确,研究人员根据一些典型的神经活动编码方法,设计出了三种基本编码方式,即
速率编码:信息通过神经元发放脉冲的频率来编码。更高的频率通常表示更强的激活。
延迟编码:信息通过脉冲的时间间隔来编码。不同的时间间隔可以表示不同的信息。
德尔塔调制:事件驱动型,根据时间信号前后差值来触发脉冲。
 本文采用snntorch库作为工具,演示了灰度图、时序信号等常见信息的编码方法,并提供了相关的代码。主要内容和代码均参考snntorch官方文档
本文采用snntorch库作为工具,演示了灰度图、时序信号等常见信息的编码方法,并提供了相关的代码。主要内容和代码均参考snntorch官方文档
1. 速率编码
速率编码即根据信息强度值更改神经元释放脉冲的频率。
1.1 图片编码(以Mnist数据集为例)
以mnist图片为例,脉冲神经网络是对脉冲信号流进行处理的,是时序的,因此对mnist这种静态图片进行编码时,需要加入时间轴。一般的做法是将图片复制多份,然后叠加为视频流,再进行归一化,每个像素点的值作为概率,采用伯努利分布来触发脉冲。以下演示了snntorch库加载mnist数据集、构建子数据集、速率编码的流程。
(1)加载mnist数据集
import snntorch as snn
import torch
from torchvision import datasets, transforms
from snntorch import utils
from torch.utils.data import DataLoader
dtype = torch.float
# 加载mnist数据集
data_path='data/mnist'# 数据存放位置
# 数据格式为28*28,归一化到(0,1)
transform = transforms.Compose([
transforms.Resize((28,28)),
transforms.Grayscale(),
transforms.ToTensor(),
transforms.Normalize((0,), (1,))])
# 初次运行则下载mnist数据集
mnist_train = datasets.MNIST(data_path, train=True, download=True, transform=transform)
# 取60000/10 = 6000个样本作为训练集
subset = 10
mnist_train = utils.data_subset(mnist_train, subset)
print(f"The size of mnist_train is {len(mnist_train)}")
# 上面创建的 Dataset 对象会将数据加载到内存中,而 DataLoader 会将数据分批加载到内存中。PyTorch 中的数据加载器是将数据传入网络的便捷接口。它们会返回一个迭代器,分成大小为 batch_size 的小批量。
batch_size=128
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
# Training Parameters
num_classes = 10 # MNIST has 10 output classes
(2)mnist速率编码
snntorch直接提供了脉冲编码的函数库spikegen,可以直接调用spikegen.rate进行速率编码,
num_steps表示每个样本的脉冲数据的时间步数,这里设置为100。batch_size是每个 minibatch 的样本数量。
from snntorch import spikegen
# 设置重复次数为100,即脉冲流的长度为100
num_steps = 100
# Iterate through minibatches
data = iter(train_loader)
data_it, targets_it = next(data)
# Spiking Data
# 输入数据的结构为 [num_steps x batch_size x input dimensions] :
spike_data = spikegen.rate(data_it, num_steps=num_steps)
print(spike_data.size())(3)打印图片
import matplotlib.pyplot as plt
import snntorch.spikeplot as splt
# 随机选择显示1个图片编码
spike_data_sample = spike_data[:, 0, 0]
fig, ax = plt.subplots()
splt.animator(spike_data_sample, fig, ax)
plt.show()

(4)打印神经元编码
plt.figure(facecolor="w")
plt.subplot(1,1,1)
plt.imshow(spike_data_sample.mean(axis=0).reshape((28,-1)).cpu(), cmap='binary')
plt.axis('off')
(5)观察单个神经元编码
idx = 210 # index into 210th neuron
fig = plt.figure(facecolor="w", figsize=(8, 1))
ax = fig.add_subplot(111)
splt.raster(spike_data_sample.reshape(num_steps, -1)[:, idx].unsqueeze(1), ax, s=100, c="black", marker="|")
plt.title("Input Neuron")
plt.xlabel("Time step")
plt.yticks([])
plt.show()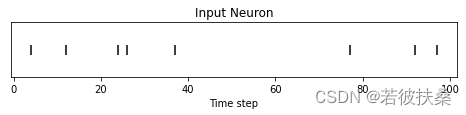
1.2 时序信号编码 (以正弦波为例)
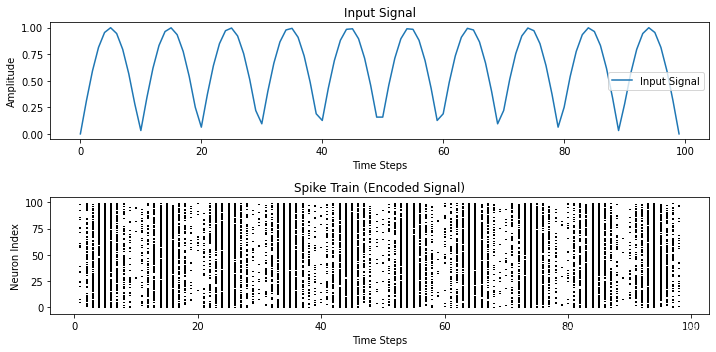
对时序信号的编码亦是如此,这里以一个正弦信号为例:在速率编码中,信号的值即为神经元产生脉冲的概率值,神经元根据伯努利分布,发出脉冲。在正弦信号最大值附近时,所有神经元都发出脉冲,因此是一条直线,在靠近0或负值时,神经元不产生脉冲。
import torch
import snntorch.spikegen as spikegen
import matplotlib.pyplot as plt
# 定义时序信号
time_steps = 100
input_signal = torch.sin(torch.linspace(0, 10 * 3.1416, time_steps))
input_signal = torch.abs(input_signal)
# 编码时序信号
spike_train = spikegen.rate(input_signal, num_steps=time_steps, gain=1)
print(spike_train)
# 绘制时序信号和脉冲编码结果
plt.figure(figsize=(10, 5))
# 绘制时序信号
plt.subplot(2, 1, 1)
plt.plot(input_signal.numpy(), label='Input Signal')
plt.title('Input Signal')
plt.xlabel('Time Steps')
plt.ylabel('Amplitude')
plt.legend()
# 绘制脉冲编码结果
plt.subplot(2, 1, 2)
plt.eventplot([torch.nonzero(spike_train[i]).numpy()[:, 0] for i in range(time_steps)], colors='black', linewidths=2)
plt.title('Spike Train (Encoded Signal)')
plt.xlabel('Time Steps')
plt.ylabel('Neuron Index')
plt.tight_layout()
plt.show()
输出结果:
2. 延迟编码
速率编码的观点实际上颇具争议。尽管我们相当确信速率编码发生在我们的感官外围,但我们并不相信大脑皮层会将信息全面编码为脉冲速率。其中几个令人信服的原因包括:
- 能耗:速率编码完成任何任务都需要多个脉冲,而每个脉冲都会消耗能量。事实上,速率编码最多只能解释 15% 神经元的活动,它不可能是大脑内唯一的机制,因为大脑资源有限,而且效率很高。
- 反应响应时间:我们知道,人类的反应时间大约为 250 毫秒。如果人脑中神经元的平均发射率约为 10 赫兹,那么我们在反应时间内只能处理约 2 个尖峰。
那么,如果速率编码在能效或延迟方面不是最佳的,我们为什么还要使用它们呢?速率编码的鲁棒性更强,可以一定程度上抵抗噪声,便于对传感器信号编码,即使有些脉冲被噪声影响无法产生也没关系,因为还会有更多的脉冲出现。
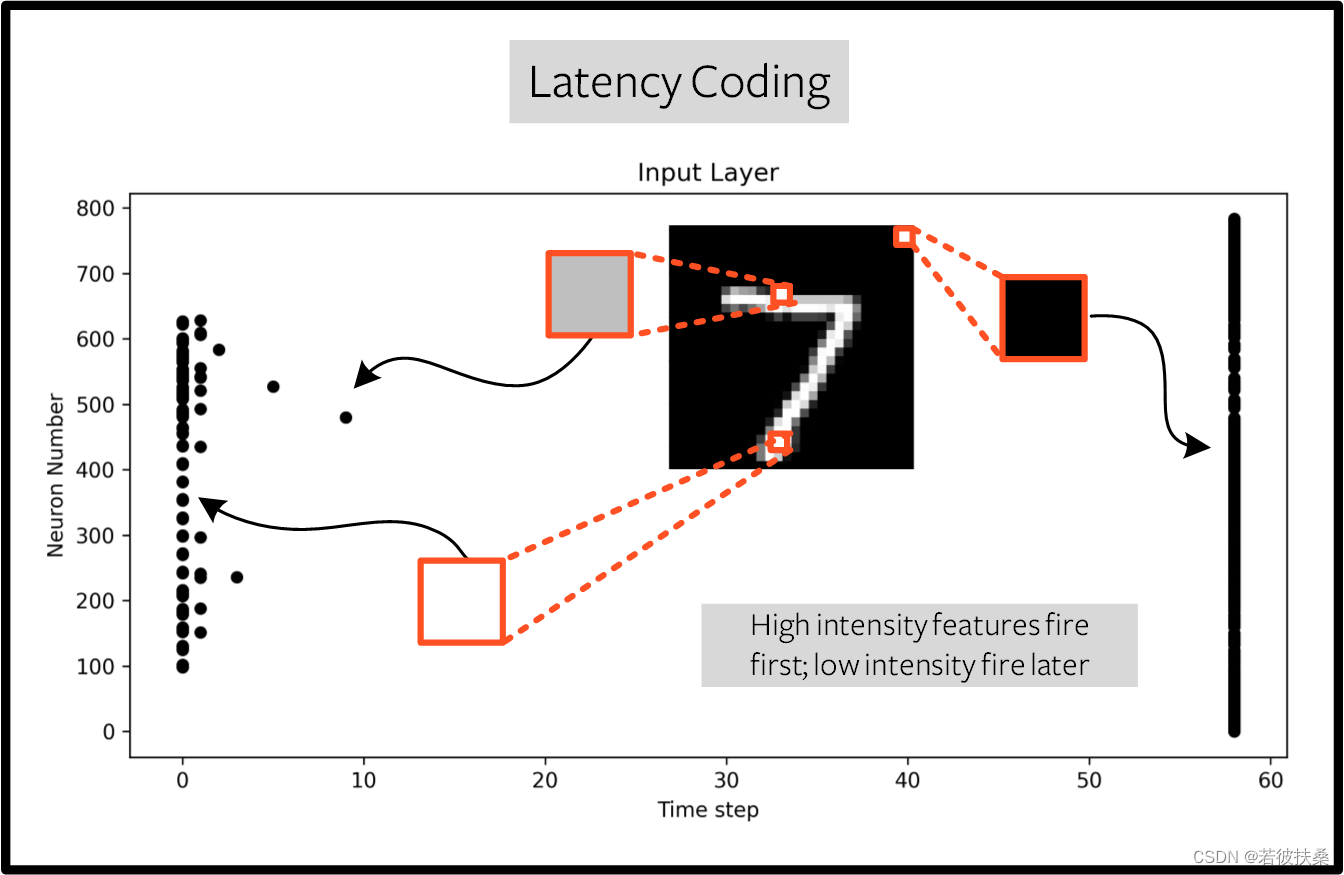
延迟编码通过控制脉冲产生的时间来进行编码。一般幅值越大的信号点,产生的脉冲越靠前。延迟编码依赖于神经元精确发射脉冲时间承载的信息,与依赖发射频率的速率编码相比,单个脉冲的意义要大得多。虽然这样更容易受到噪声的影响,但也能将运行功耗降低几个数量级。与速率编码相比,延迟编码的一大优势在于稀疏性。如果神经元被限制在感兴趣的时间过程中最多发射一次,那么这将促进低功耗运行。
延迟编码的物理意义:
延迟编码可以认为是一个带电容的电阻电路,电容的大小C和输入电流大小决定了电容器何时被击穿。
2.1 图片编码
在snntorch库中采用spikegen.latency函数进行延迟编码。
import snntorch as snn
import torch
from snntorch import spikegen, utils
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# Training Parameters
batch_size=128
data_path='data/mnist'
num_classes = 10 # MNIST has 10 output classes
num_steps = 100
# Torch Variables
dtype = torch.float
# Define a transform
transform = transforms.Compose([
transforms.Resize((28,28)),
transforms.Grayscale(),
transforms.ToTensor(),
transforms.Normalize((0,), (1,))])
subset = 10
mnist_train = datasets.MNIST(data_path, train=True, download=True, transform=transform)
mnist_train = utils.data_subset(mnist_train, subset)
print(f"The size of mnist_train is {len(mnist_train)}")
# 上面创建的 Dataset 对象会将数据加载到内存中,而 DataLoader 会将数据分批加载到内存中。PyTorch 中的数据加载器是将数据传入网络的便捷接口。它们会返回一个迭代器,分成大小为 batch_size 的小批量。
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
# Iterate through minibatches
data = iter(train_loader)
data_it, targets_it = next(data)
# Spiking Data
# 输入数据的结构为 [num_steps x batch_size x input dimensions] :
spike_data = spikegen.latency(data_it, num_steps=num_steps, tau=10, threshold=0.01, linear=True)
print(spike_data.size())
import matplotlib.pyplot as plt
import snntorch.spikeplot as splt
fig = plt.figure(facecolor="w", figsize=(10, 5))
ax = fig.add_subplot(111)
splt.raster(spike_data[:, 0].view(num_steps, -1), ax, s=25, c="black")
plt.title("Input Layer")
plt.xlabel("Time step")
plt.ylabel("Neuron Number")
plt.show()
大部分尖峰发生在最后一个时间步,此时输入特征低于阈值。从某种意义上说,MNIST 样本的深色背景并不包含有用的信息。
2.2 时序信号编码
import torch
import snntorch.spikegen as spikegen
import matplotlib.pyplot as plt
import snntorch.spikeplot as splt
# 定义时序信号
time_steps = 100
input_signal = torch.sin(torch.linspace(0, 10 * 3.1416, time_steps))
input_signal = torch.abs(input_signal)
# 编码时序信号
spike_data = spikegen.latency(input_signal, num_steps=time_steps, tau=5, threshold=0.01, linear=True)
print(spike_data)
# 绘制时序信号和脉冲编码结果
plt.figure(figsize=(10, 5))
# 绘制时序信号
plt.subplot(1, 1, 1)
plt.plot(input_signal.numpy(), label='Input Signal')
plt.title('Input Signal')
plt.xlabel('Time Steps')
plt.ylabel('Amplitude')
plt.legend()
# 绘制脉冲信号
fig = plt.figure(facecolor="w", figsize=(10, 5))
ax = fig.add_subplot(111)
splt.raster(spike_data[:, :].view(time_steps, -1), ax, s=25, c="black")
plt.title("Input Layer")
plt.xlabel("Time step")
plt.ylabel("Neuron Number")
plt.show()


3. 德尔塔调制
德尔塔调制基于事件驱动的脉冲编码方法。,使用snntorch.delta 函数进行编码。它获取所有时间步长前后特征之间的差值,如果差值为正且大于阈值,则认为包含一个事件,就会产生一个脉冲:
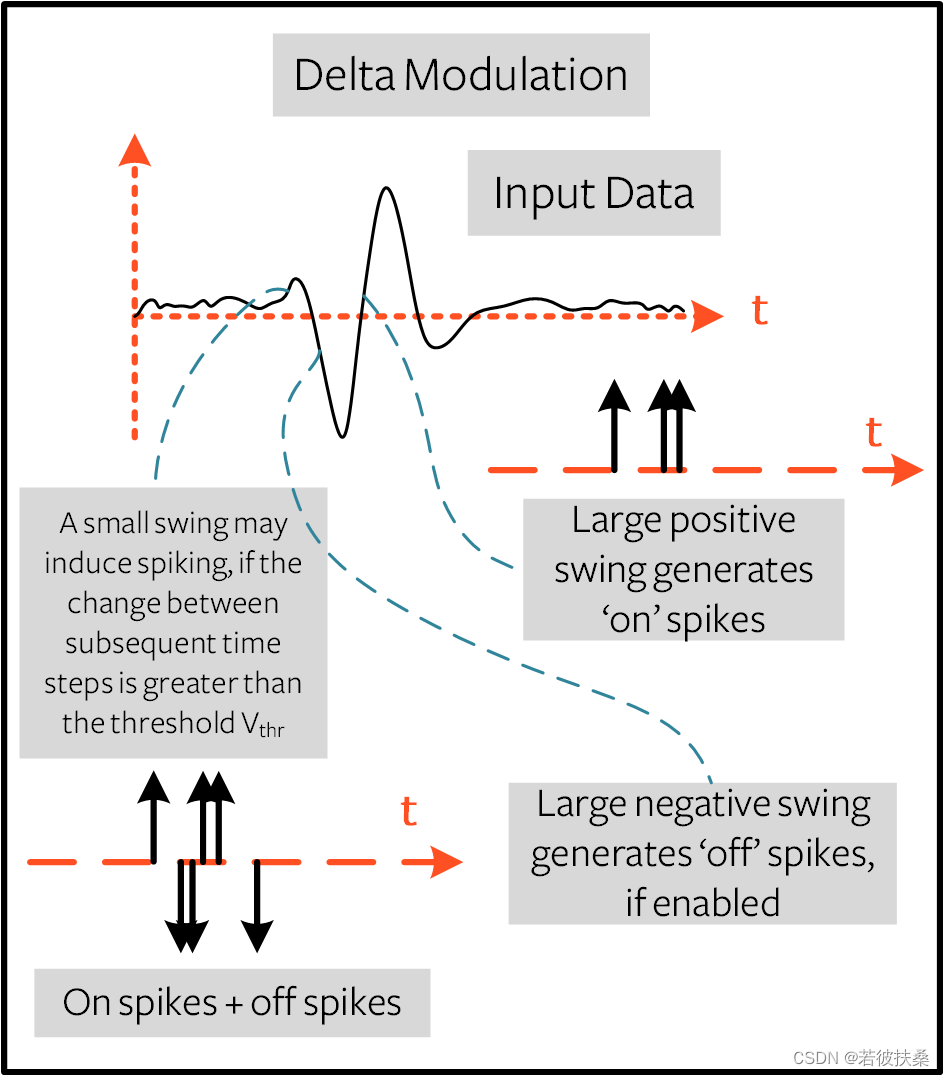
3.1 图片编码
德尔塔调制主要用于检测幅度变化,在图像中可以起到一定程度上的边缘提取工作。
3.2 时序信号编码
import torch
import snntorch.spikegen as spikegen
import matplotlib.pyplot as plt
import snntorch.spikeplot as splt
# 定义时序信号
time_steps = 100
input_signal = torch.sin(torch.linspace(0, 10 * 3.1416, time_steps))
input_signal = torch.abs(input_signal)
# 编码时序信号
spike_data = spikegen.delta(input_signal, threshold=0.3, off_spike=True)
# 绘制时序信号
fig = plt.figure(facecolor="w", figsize=(8, 1))
ax = fig.add_subplot(111)
splt.raster(spike_data, ax, c="black")
plt.title("Input Neuron")
plt.xlabel("Time step")
plt.yticks([])
plt.xlim(0, len(input_signal))
plt.show()
















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









