







基础作业:
复现课程知识库助手搭建过程 (截图)
进阶作业:
选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址)
基础作业
1.环境配置
(1)由于开发机之前已经配置过conda环境和模型了,直接复制过来即可。
(2)LangChain 相关环境配置,建议使用清华源,会快很多(pip最后添加 -i https://pypi.tuna.tsinghua.edu.cn/simple)

(3)下载sentence transformer

(4)下载NLTK资源
2.知识库搭建
3.InternLM 接入 LangChain
源代码中的路径有点问题,替换成自己的
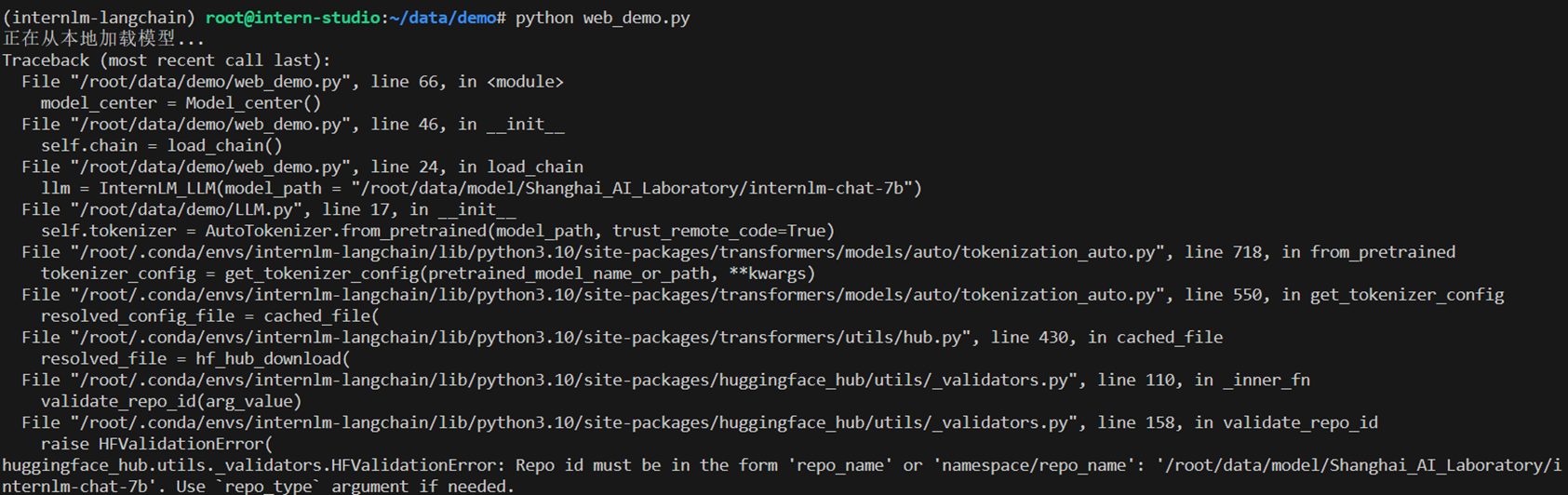
修改路径后,成功执行:

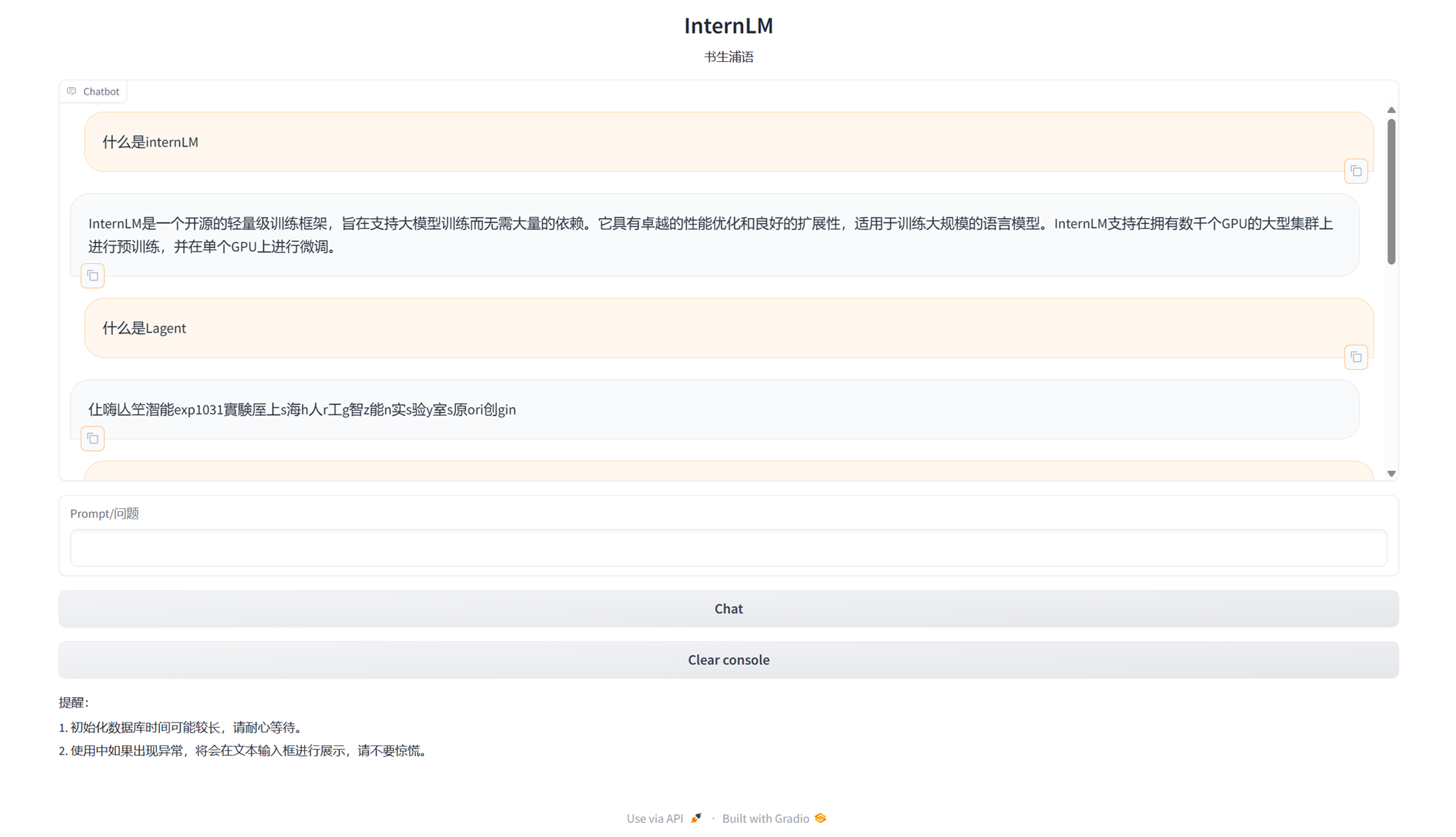
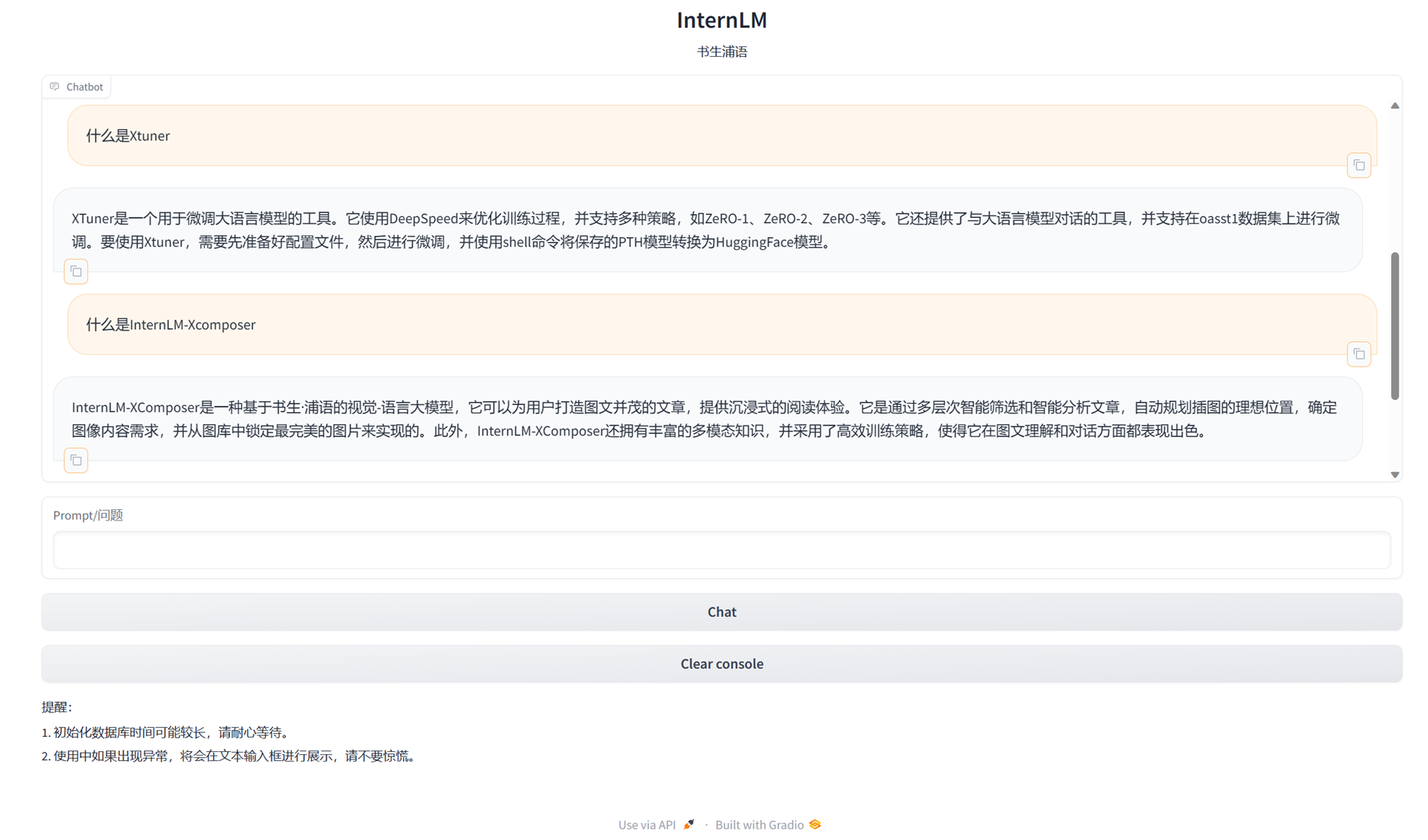
随便问了几个相关问题,大部分没啥问题,都可以从构建的数据库中检索出答案,但不太完善,其中有一些回答会出现乱码。
进阶作业
1.垂直领域
我选择的是垂直领域是新能源汽车领域,收集了其中数十篇行业研究报告。

2.构建个人数据库
(1)由于源码中不支持使用pdf文件构建数据库,因此需要做一些修改,添加对pdf文件的支持。
首先安装相关的库
然后对源码进行一些修改
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".pdf"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
elif file_type == 'pdf':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
# tar_dir = [
# "/root/data/InternLM",
# "/root/data/InternLM-XComposer",
# "/root/data/lagent",
# "/root/data/lmdeploy",
# "/root/data/opencompass",
# "/root/data/xtuner"
# ]
tar_dir = ["/root/data/AutoCar"]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma_autocar'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()最后执行,成功构建个人向量数据库

3.InternLM 接入 LangChain
(1)有无RAG,对比问答
测试代码:
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma_autocar'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
from LLM import InternLM_LLM
llm = InternLM_LLM(model_path = '/root/model/Shanghai_AI_Laboratory/internlm-chat-7b')
# llm.predict("你是谁")
from langchain.prompts import PromptTemplate
# 我们所构造的 Prompt 模板
template = """使用以下上下文来回答用户的问题。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
有用的回答:"""
# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
# 检索问答链回答效果
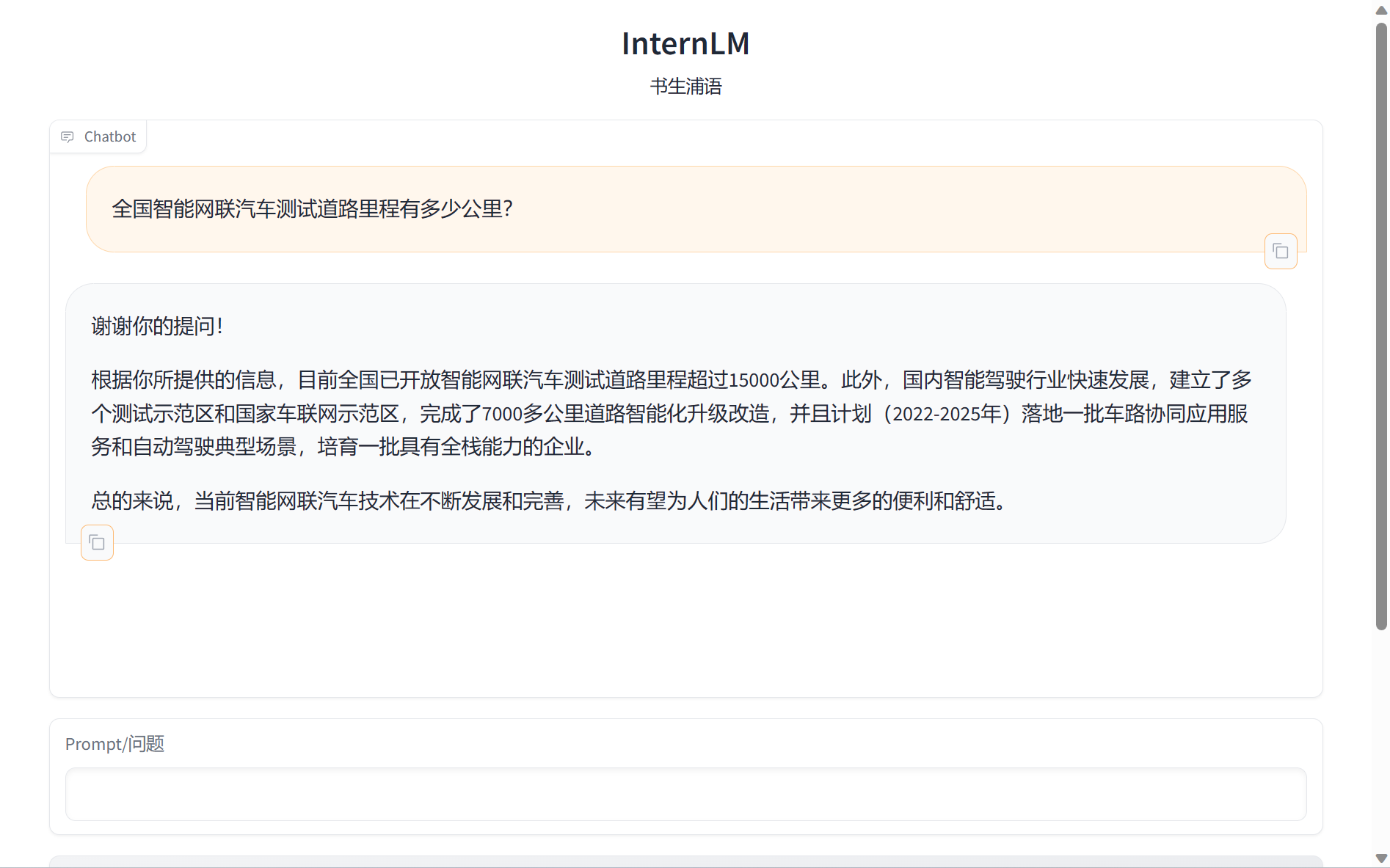
question = "全国智能网联汽车测试道路里程有多少公里?"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])
# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)测试结果:

原文:

从结果可以看出能成功从个人构建的数据库中检索出上下文,然后进行回答。
(2)web_demo.py测试
(3)部署测试
来不及弄了....















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









