







1.效果视频:(主脚本有1175行代码,所有脚本加起来代码有1400行左右)LSTM+transform交通流量预测加PyQt5界面可视化(另外四种LSTM/GRU/CNN-LSTM/CNN-GRU作为对比))_哔哩哔哩_bilibili
一共五个模型:1.LSTM+transform;2.LSTM,3.GRU;4.CNN-LSTM;5CNN-GRU
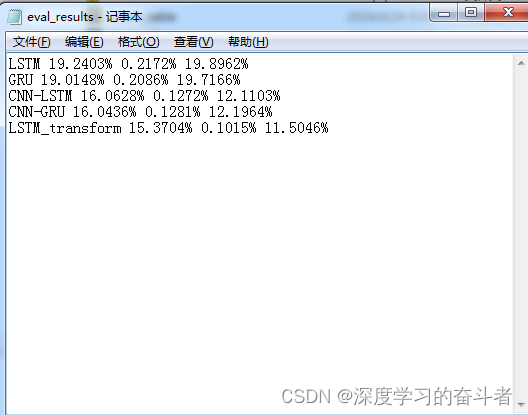
测试集指标对比(MAE/MSE/MAPE)
LSTM 19.2403% 0.2172% 19.8962%
GRU 19.0148% 0.2086% 19.7166%
CNN-LSTM 16.0628% 0.1272% 12.1103%
CNN-GRU 16.0436% 0.1281% 12.1964%
LSTM_transform 15.3704% 0.1015% 11.5046%
数据集的介绍可以关注:创新模型LSTM+Transformer交通流量预测(Python代码,GRU/LSTM/CNN_LSTM作为对比模型,多特征输入,单标签输出,可以替换为其它时序数据集)-CSDN博客
文件夹介绍
1.datasets文件夹(存放原始数据,被代码调用。user_info是后台保存用户名和密码的文件,用户在注册界面注册的信息会自动被保存在user_info文件。)

2.images文件夹(自动保存下来每个模型训练损失曲线,训练集真实值与预测值对比曲线,测试集真实值与预测值对比曲线,第一张图是界面背景图,可以随意更换)
3. result文件夹(自动保存下来每个模型100次迭代结束时,测试集的真实值和预测值)
4.creat_table.py文件(代码中使用了pymysql库来连接到MySQL数据库,创建游标对象用于执行SQL语句。然后执行创建表的SQL语句,并提交事务以确保表的创建操作被保存。最后,关闭了游标和数据库连接,以释放资源并结束与数据库的连接。)
import pymysql
# 连接数据库
cnx = pymysql.connect(user='root', password='694296', host='localhost', database='yang')
# 创建游标对象
cursor = cnx.cursor()
# 定义创建表的SQL语句
create_table_query = '''
CREATE TABLE data_table (
id INT AUTO_INCREMENT PRIMARY KEY,
date_d varchar(128),
one varchar(64) not null,
two varchar(64) not null,
three varchar(64) not null,
four varchar(64) not null,
wu varchar(64) not null,
liu varchar(64) not null,
qi varchar(64) not null,
ba varchar(64) not null,
jiu varchar(64) not null,
shi varchar(64) not null,
shiyi varchar(64) not null,
shier varchar(64) not null,
shisan varchar(64) not null,
shisi varchar(64) not null,
shiwu varchar(64) not null
)
'''
# 执行SQL语句
cursor.execute(create_table_query)
# 提交事务
cnx.commit()
# 关闭游标和数据库连接
cursor.close()
cnx.close()
5.csv_to_db.py文件(代码连接到MySQL数据库,并使用pymysql库执行插入操作。在执行插入操作之前,代码定义了一个SQL插入语句,其中包含了与"data_table"表中列对应的字段。然后使用executemany()方法批量执行SQL语句,将CSV文件中的数据插入到数据库中)
import csv
import pymysql
file_path = 'datasets/data15.csv'
all_data = []
with open(file_path, mode='r', encoding='utf-8') as file:
csv_reader = csv.reader(file)
# 跳过标题头部(如果CSV有标题行)
next(csv_reader)
# 逐行读取csv文件
for row in csv_reader:
print(row) # row是一个列表,包含了当前行的所有字段
all_data.append(row)
import pymysql
# 数据库连接信息
connect_info = {
'host': 'localhost',
'user': 'root',
'password': '694296',
'db': 'yang',
'charset': 'utf8mb4'
}
# 连接到数据库
connection = pymysql.connect(**connect_info)
try:
with connection.cursor() as cursor:
# 编写 SQL 插入语句,字段数量要与列表中子列表的长度匹配
sql = "INSERT INTO `data_table` (`date_d`, `one`, `two`, `three`, `four`, `wu`, `liu`, `qi`, `ba`, `jiu`, `shi`, `shiyi`, `shier`, `shisan`, `shisi`, `shiwu`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
# 批量执行 SQL 语句
cursor.executemany(sql, all_data)
# 提交事务
connection.commit()
except pymysql.MySQLError as e:
print(f"Error: {e}")
finally:
connection.close()
6.eval_results文本(存放的是每种模型测试集的指标值,被主脚本调用,展示在界面)
7.pyqt_demo.py是主脚本(里面存放五种模型,并界面各种可视化)
8.version.py是查看你本地的库版本,方便核对库版本
import numpy as np
import matplotlib
import pandas as pd
import sklearn
import keras
from pandas import DataFrame
print("NumPy version:", np.__version__)
print("Matplotlib version:", matplotlib.__version__)
print("Pandas version:", pd.__version__)
print("Ssklearn version:", sklearn.__version__)
print("Keras version:", keras.__version__)9.关于特征与标签选择(在交通流量预测方面主要有以下三种方式,本文是第二种)
9.1.第一种方式如下图所示(有另一篇会呈现这种数据集输入)
![]()
每一行前14列(黄色部分) 作为特征输入,每一行的第15列值作为标签(蓝色部分)
这种方法非常不建议,因为,虽然拟合效果好,但是用同一时刻发生采集的数据作为特征和标签,没有实用性。
9.2.第二种方式如下图所示

前6行的15列数据(黄色部分)作为特征输入,第7行的第十五列数据(蓝色部分)为标签。
根据已获取的历史数据预测下一个时间点或者未来多个时间点 更符合实际。所以类似这种的特征输入,可以直接替换数据集。
10.效果图
登录界面
注册界面

登录以后的界面

训练模型界面
 对比效果展示
对比效果展示
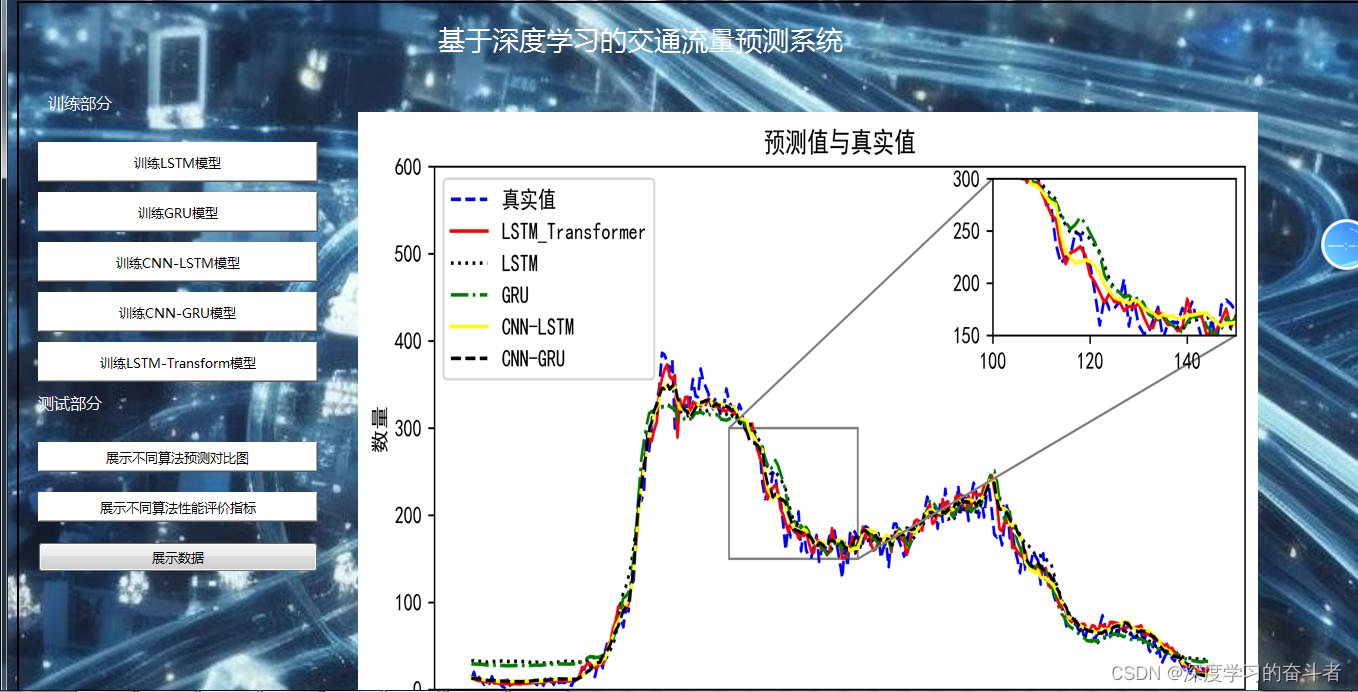
指标对比

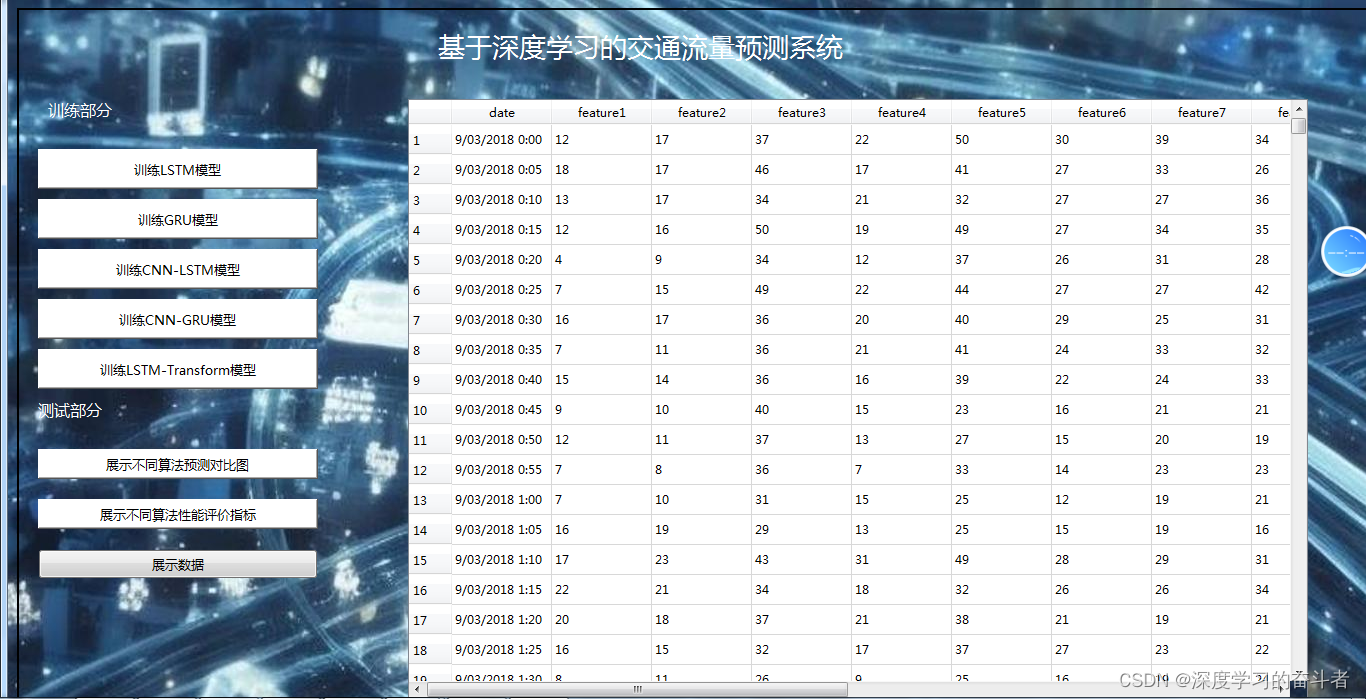
原始数据展示
对数据集和代码压缩包感兴趣,可以关注最后一行
import sys
import numpy as np
from PIL import Image
from PyQt5.QtCore import Qt
from PyQt5.QtGui import QPainter,QPen,QImage,QPixmap,QFont,QPalette,QBrush
from PyQt5.QtWidgets import QWidget,QLabel,QPushButton,QLineEdit,QApplication,QMessageBox,QTableWidget,QTableWidgetItem
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from math import sqrt
from keras.layers import *
from keras.models import *
from sklearn import preprocessing
from pandas import DataFrame
from pylab import mpl
#压缩包:https://mbd.pub/o/bread/mbd-ZpWUk5dw















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











