







基于大量数据进行预训练以构建基础模型(FMs)的能力,已在众多领域取得了显著成功,包括自然语言处理、计算机视觉,以及最近在单细胞基因组学领域——以GeneFormer、scGPT和scFoundation为代表。然而,随着单细胞基础模型开始在越来越大的数据集上进行训练,严重的隐私和伦理问题也随之而来。此外,与文本数据不同,单细胞数据是无序的,并且具有独特的表格结构,而大多数现有的单细胞基础模型都忽略了这一点。
Tabula是一种利用联邦学习(FL)和表格建模设计的、保护隐私且感知表格结构的基础模型。Tabula结合了基础模型和联邦学习的优势,能够在多个客户端之间进行协作模型训练,同时不损害数据隐私。与早期将单细胞数据视为自然语言(将细胞看作由基因定义的 “单词” )的单细胞基础模型不同,Tabula引入了一种新的预训练策略,明确地对单细胞数据的表格结构进行建模。大量实验结果表明,Tabula在各种下游任务(包括细胞类型注释、基因插补、基因扰动、多批次整合和多组学整合)中优于最先进的方法(仅需一半的预训练数据),并能保护数据隐私。此外,Tabula能够准确揭示多种生物系统中的成对甚至组合调控逻辑,包括造血、胰腺内胚层发育、神经发生和心脏发生。
来自:Toward a privacy-preserving predictive foundation model of single-cell transcriptomics with federated learning and tabular modeling
背景概述
多细胞系统中一个引人注目的问题是,相同的基因组如何在发育和疾病过程中产生种类繁多的细胞类型和状态。不同的基因表达模式以及复杂的成对或更高阶调控相互作用是这种多样性的基础。想象一下,每个细胞状态都是转录组状态空间中的一个点,其中每个维度都对应一个基因。任何生物体中细胞状态的可行空间并不会占据整个状态空间,而通常被认为位于一个流形上,这个流形由主导的调控网络塑造而成。 尽管对调控网络进行全基因组范围的测量在很大程度上仍然难以实现,但单细胞基因组学的快速发展以及合作联盟的努力,如陈·扎克伯格倡议(CZI)、人类细胞图谱计划(Rozenblatt - Rosen等人,2017年)和人类生物分子图谱计划(HuBMAP,HuBMAP联盟,2019年),已使我们能够绘制出人类生物学中这一单细胞流形的很大一部分。
自然语言处理NLP、计算机视觉,以及最近蛋白质语言模型的最新突破表明,基于注意力机制的Transformer可以通过对大型数据集进行无监督自学习数据的基本结构,而无需依赖对语法、视觉几何或物理规则的显式建模。因此,大量单细胞数据的积累预示着人类生物学的新时代,使得单细胞基础模型的开发成为可能,有助于从根本上理解基因调控——这对几乎所有细胞过程都至关重要。
在过去的一年里,我们见证了单细胞基础模型的出现,特别是Geneformer、scFoundation、CellPLM、scGPT、UCE和NicheFormer。然而,目前的模型未能明确考虑 scRNA-seq 数据的表格结构,常常简单地将单个细胞内的基因表达转换为基因序列,以模仿自然语言处理中使用的单词序列。虽然这使自然语言处理范式适用于单细胞数据,但它忽略了scRNA-seq潜在数据结构的关键特征。因此,迫切需要开发新的预训练方法,明确对单细胞数据的表格结构进行建模。此外,此前有研究表明,scRNA-seq数据易受到隐私泄露问题 【1-3】,即一项研究中的信息可以与另一项研究相关联,从而识别出私人数据。随着开始利用来自数千个人的数千万个单细胞和数据集创建基础模型,这种隐私问题变得更加突出。
【1】A privacy concern: Bioinformatics and storing biodata
【2】Private information leakage from single-cell count matrices,Cell,2024
【3】PPML-Omics: A privacy-preserving federated machine learning method protects patients’ privacy in omic data,Science Advances,2024
为了填补这一空白,Tabula出现了,这是一种通过表格学习为 scRNA-seq 数据量身定制的隐私保护联邦基础模型。Tabula有两大创新之处:
- 第一,它将联邦学习(FL)引入基础模型训练,使多个客户端能够在不损害个体数据隐私的情况下协作训练模型。这种分布式计算框架还显著降低了本地训练成本。此外,虽然Tabula的联邦学习框架依赖于一个共享的表格 Transformer 来在客户端之间共享通用知识,但它也拥有特定于客户端的嵌入器和投影头,以捕捉每个客户端(例如组织)的独特特征。这种特殊设计提高了针对每个客户端特定下游任务的零样本学习性能。
- 第二,早期的单细胞基础模型将单细胞数据类比为自然语言数据(例如,将细胞视为句子,将基因视为单词),而Tabula则重新定义了这一范式,将单细胞数据视为表格数据,并通过表格学习对其进行相应建模。大量的基准测试表明,在基因层面和细胞层面的下游任务中,Tabula始终优于最先进的基础模型,这些任务包括细胞类型注释、批次校正、基因插补、单基因和双基因扰动响应预测以及反向扰动预测(预测扰动条件)。重要的是,Tabula还能够揭示多种生物系统中的成对甚至组合基因调控关系,包括造血、胰腺内胚层发育、神经发生和心脏发生等系统,在这些系统中,广泛的生化研究已经验证了核心调控网络。这些结果朝着构建一个具有机制解释和预测能力的单细胞基础模型迈出了重要一步。Tabula是AI Agent生态系统Chiron的一部分,使用PyTorch Lightning实现,可在https://github.com/aristoteleo/tabula上获取。
十年前,卡尔等人报告了首个细胞模型,该模型综合了多种数学方法来预测广泛的生物过程。鉴于单细胞基因组学的最新进展,以及不断扩大的细胞图谱分析工作,创建虚拟细胞——计算生物学长期追求的目标——似乎越来越可行。然而,与卡尔等人所展示的依赖明确的生物物理模型不同,生成式人工智能的进步将推动虚拟细胞发展的新阶段。生成式人工智能在理解自然语言处理(NLP)和计算机视觉等领域的多尺度复杂模式方面展现出了巨大潜力,在生物学中,对包含数千个变量的生物系统进行建模,尤其是在哺乳动物系统中,曾是难以想象的。由于一个终极的单细胞基础模型理论上可以整合所有已知的人类生物学知识,可以设想在未来,基于单细胞基础模型的虚拟细胞可用于模拟细胞发育、疾病的各个方面,通过预测最佳的药物、基因和细胞疗法,使疾病状态恢复正常,从而重塑人类医学的格局。
Tabula通过表格学习和联邦学习重新定义了单细胞基础模型
诸如Geneformer、scGPT等先驱性单细胞基础模型展现出大语言模型(LLM)在推动单细胞生物学发展方面的潜力。然而,这些框架以及近期的新进展,如UCE、CellPLM、NicheFormer等,都依赖集中式学习,即直接在聚合数据上训练统一模型,这引发了对数据隐私和伦理问题的担忧。此外,尽管单细胞数据显然没有内在顺序,但这些方法大多通过一些相当简单的排序策略,将单细胞中的无序基因转化为基因序列后,直接借用最初为顺序文本数据设计的传统大语言模型技术(图1a)。例如,Geneformer通过对每个细胞内标准化的基因表达进行排序生成基因序列,然后进行掩码语言建模。类似地,scGPT首先对基因进行分箱处理,然后通过自回归建模进行下一个基因的预测。

为了在保护数据隐私的同时对表格结构进行明确建模,Tabula被提出,这是一种新的单细胞基础模型,它整合了表格学习和联邦学习(图1a)。首先,利用联邦学习,使Tabula能够拥有不同的客户端,并在本地利用私有数据训练特定客户端的模型,而无需在机构间共享原始数据,从而消除了对源自患者或专有样本的潜在单细胞数据集的隐私担忧。其次,Tabula 没有将基因表达数据视为有序序列,而是使用自监督表格学习【4】对其内在的表格结构进行明确建模。
【4】Revisiting Deep Learning Models for Tabular Data,Nips,2021
具体来说,TABULA 将基因表达矩阵的每个细胞视为一行基因,这些基因具有排列不变性,其中每一列对应一个特定的基因(例如 g 1 , . . . , g m g_{1},...,g_{m} g1,...,gm),并且细胞和基因都涉及数值表达值,例如 X i , j X_{i,j} Xi,j 表示细胞 i i i 中基因 j j j 的测量表达水平。
列特征还可以包括元数据(meta data),如组织类型或细胞类型,提供额外的生物学背景信息。Tabula利用了一个大规模的预训练数据集,该数据集包含来自不同组织的1500万个单细胞(补充图1a和b),遵循 scaling law,即随着预训练数据集规模的增加,性能会显著提升(补充图1c和d)。


此外,Tabula可以生成组织特异性嵌入器,对各个组织的独特特征进行编码,从而更好地表示组织特异性生物学特征(补充图2)。与那些给基因强加人为顺序的基于序列的模型不同,Tabula的表格设计将每个基因视为一个独立的属性,尊重其无序的本质。通过结合细胞层面和基因层面的学习,Tabula有效地对表格状单细胞数据中的基因和细胞关系进行了建模。

- 补充图2a:以来自脑组织的内嗅皮层数据集为例。每幅图比较了由脑特异性Tabula生成的同类型细胞间的余弦相似度(蓝色线),以及来自不同组织(脑和肺特异性Tabula权重分别生成)的同类型细胞间的余弦相似度(橙色线)。该分布表明了相似程度,峰值接近1意味着组内一致性高。蓝色线的分布显著右移(*表示经威尔科克森检验和错误发现率校正后,p<0.05),这突出显示了组织特异性Tabula模型能够学习到组织独特的细胞分子特征。
- b与a图相同,但此处比较的是基因embedding的余弦相似度。
- c:组织特异性的Tabula模型在相应数据集上表现更优。脑特异性的Tabula嵌入器明显优于用其他组织的权重初始化的嵌入器以及随机初始化的嵌入器。这一发现凸显了采用组织特异性嵌入器对改善针对特定生物学背景的下游任务的优势。
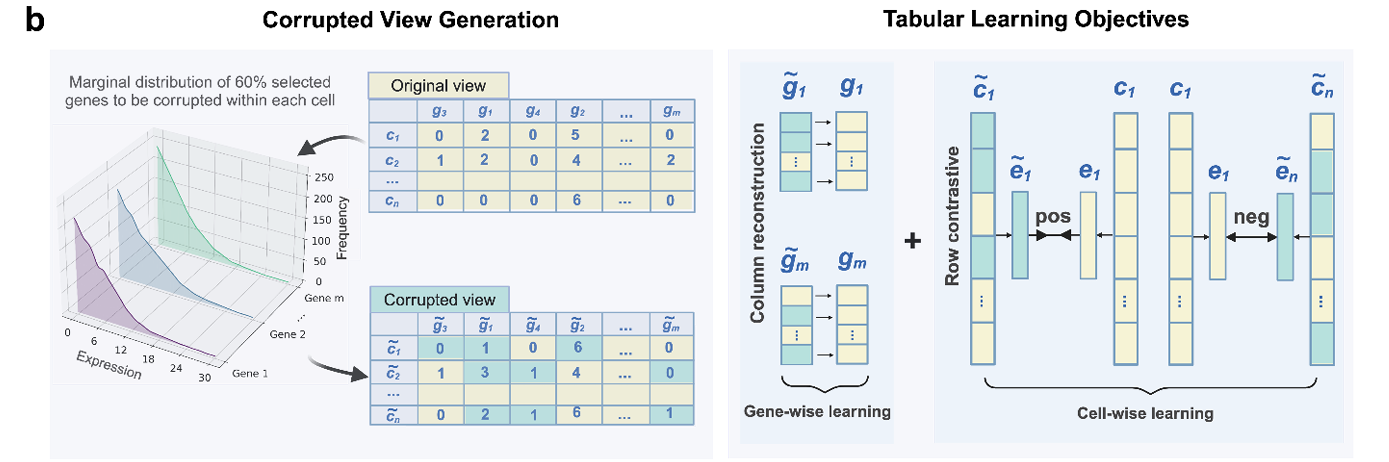
为了处理 scRNA-seq 数据集固有的表格结构,Tabula引入了一种新的自监督表格建模框架,该框架由基因层面的重建学习和细胞层面的对比学习组成(图1b)。
对于基因层面的重建,首先,随机选择每个细胞中60%的基因,将这些选定基因的表达值替换为从各基因在所有细胞中的边际分布中采样得到的值。然后,基因层面的重建尝试从损坏后的表达值中恢复原始的表达值。
相比之下,细胞层面的对比学习则试图在潜在空间中分别对齐或分离正样本细胞对和负样本细胞对。具体来说,每个细胞的基因表达数据,包括原始数据( c 1 c_{1} c1)和损坏后的数据( c ~ 1 \widetilde{c}_{1} c 1),首先被嵌入到潜在维度,得到( e 1 e_{1} e1)和( e ~ 1 \widetilde{e}_{1} e 1)。接着,利用对比学习确保代表同一细胞的正样本细胞对(例如 e 1 e_{1} e1和 e ~ 1 \widetilde{e}_{1} e 1)在潜在空间中共定位,而代表不同细胞的负样本细胞对(例如例如 e 1 e_{1} e1和 e ~ n \widetilde{e}_{n} e n,两个不同的细胞)在潜在空间中总体上相互分离。因此,基因层面的重建确保了稳健的基因水平表征,而细胞层面的对比学习既保证了细胞内的一致性,又保证了细胞间的变异性,从而沿着基因轴和细胞轴对单细胞的细胞-基因矩阵的表格结构进行了恰当的建模。
此外,为解决数据隐私问题,Tabula整合了联邦学习技术,该技术依靠在多个客户端进行分布式训练,无需共享原始数据(图1c)。Tabula的联邦学习框架基于一个统一的Transformer构建,客户端模型和全局模型共享该变换器的架构,但分别进行训练。如本文所示,Tabula的预训练利用了大规模的隐私保护数据集,每个数据集都与特定的客户端相关联,比如医院、研究机构或组织类型(例如肺、脑、心脏)。原始数据保留在客户端本地,只有本地表格Transformer的权重会与中央服务器共享,用于更新全局表格Transformer模型。每个客户端都包含特定于客户端的嵌入器和投影头(图1c),这些组件将细胞-基因表转换为嵌入向量,再由表格Transformer进行处理,以计算基因层面和细胞层面的学习损失。训练过程包括在交替循环中对本地和全局表格Transformer进行迭代更新。在客户端层面,本地Transformer学习特定于客户端(例如组织特异性)的模式,然后上传到中央服务器。在中央层面,全局Transformer汇总这些上传的权重以更新全局模型,然后将汇总后的权重广播回本地客户端,以构建一个跨客户端的更通用模型。中央服务器与客户端之间的这种持续通信确保了在不共享数据的情况下跨多种数据源进行知识交换,从而保护了数据的保密性。通过在分布式客户端上使用表格学习损失进行训练,Tabula为单细胞数据建立了一种全新的基础模型,该模型既能保护隐私,又能捕捉组织特异性和跨组织的生物学差异,同时尊重 scRNA-seq 数据的内在表格结构。

- 图1c:Tabula的模型架构和预训练方案。Tabula使用Transformer进行本地或全局建模。在预训练过程中,Tabula在每个客户端的本地模型是独立更新的。然后,更新后的本地模型权重会被发送到中央服务器,而无需共享原始数据,从而保护了数据隐私。在该研究中,Tabula将每个客户端设计为特定于一种组织类型(例如肺、脑、心脏),每个客户端包含一个组织特异性嵌入器和投影头,用于捕捉该组织的独特特征。本地训练和全局模型更新在跨客户端的持续隐私保护循环中交替进行。
基于Tabula的这些创新,Tabula可以应用于一系列细胞水平或基因水平的微调以及零样本学习应用中(图1d)。细胞水平的任务包括批次校正、细胞类型注释和多组学整合,而基因水平的任务包括基因插补、基因调控网络(GRN)推断和基因扰动分析。更重要的是,为了证明单细胞基础模型能够获得机制性和预测性的见解,Tabula首先展示了能够在一系列不同的生物系统中准确预测成对和高阶组合调控,并进一步证明Tabula能够准确预测细胞对各种扰动的转录反应,以及基因扰动如何改变细胞谱系。

- 图1d:Tabula的下游微调与零样本学习。预训练完成后,Tabula利用其组织特异性嵌入器和Transformer(本地或全局的均可)开展基因和细胞层面的下游任务。细胞层面的任务包括批次校正、细胞注释和多组学整合,而基因层面的任务则涵盖去噪、插补、基因调控网络推断以及基因扰动预测。
方法
预训练数据收集和预处理
为了给Tabula的自监督预训练奠定坚实的基础,汇集了一个庞大的 scRNA-seq 数据集,该数据集包含了约1500万个来自人类细胞的转录组数据,这些数据来源于CELLxGENE门户(https://cellxgene.cziscience.com/)。
鉴于CELLxGENE门户会定期更新,使用了2023年7月25日发布的数据。该数据集涵盖了来自一系列人类主要组织的细胞,包括肠道、胰腺、肺、心脏、血液、肾脏和大脑。此外,来自脊髓和脾脏等多种较少研究的人类组织的细胞被归为一个单独的类别,称为“Other”。这样汇总后,总共有8个类别,即“肠道”、“胰腺”、“肺”、“心脏”、“血液”、“肾脏”、“大脑”和“其他”,包含3799万个人类细胞。在联邦学习框架中,将客户端的数量设置为8个,每个客户端都与上述设定的一个不同的组织类别相对应。为了保持各个类别之间的数据平衡并确保有效的预训练,实施了一个筛选过程,将每个类别的细胞数量限制在最多300万个。
根据每个类别的原始数据集标识符对其进行了重新分组。然后,分别对属于同一源数据集的细胞执行了质量控制和数据预处理程序。在每个类别中,从预处理后的数据集里随机选取300万个细胞。对于可用细胞总数少于300万个的类别,则使用所有细胞。这一过程最终生成了一个包含1500万个细胞的预训练数据集。每个 tissue 客户端的预训练细胞数量如下:肠道:80,060个细胞;胰腺:220,436个细胞;肺:3,013,840个细胞;心脏:1,768,184个细胞;血液:3,057,298个细胞;肾脏:816,538个细胞;大脑:3,024,233个细胞;其他:3,046,184个细胞。
联邦学习的质量控制与数据预处理
实施了一种针对特定数据集的质量控制和数据预处理策略。这一策略与以往在质量控制和数据预处理之前先整合数据的方法不同,这够保留每个原始数据集的独特特征,并减少批次效应的影响。
对比scBaseCamp的观点:由于比对工具、基因组参考和计数策略的选择不同,这会引入分析的可变性。scBaseCamp证明了跨数据集的统一处理有助于减少因不一致的数据处理选择而引入的分析假象。
具体而言,过滤掉了检测到的基因数量少于250个的细胞,以排除潜在的空液滴、无活力细胞或严重降解的细胞。同时,还剔除了在少于250个细胞中被检测到的基因,以减轻低表达或稀有转录本的影响。为了捕捉与生物学相关的变异,在质量控制后,在每个数据集中识别出了1200个高变基因(HVGs)。值得注意的是,高变基因是在对每个组织的数据集进行汇总之前识别出来的,因此,即使在同一组织内,不同数据集的高变基因也可能有所不同。
选择这一策略是因为,从单个数据集或不同的背景中选择高变基因,既可以提高模型识别细胞特异性特征的能力,也能增强模型从各种生物学信号中学习可泛化特征的能力。为了对预训练数据进行标准化并进一步减轻批次效应,采用了值分箱技术,将每个细胞的表达值离散化为50个区间。这种转换对不同批次的基因表达尺度进行了归一化处理,为预训练过程创建了一个更统一的输入空间。选择50个区间在保留基因表达差异和减少特定批次的技术变异之间取得了平衡。
表格建模的数据预处理
模型采用表格学习方法进行自监督预训练,学习目标包括对比损失和重建损失。对比损失侧重于增强细胞之间的特征区分能力,而重建损失旨在捕捉每个细胞内基因之间的复杂关系。为了实现这些目标,需要对输入样本进行破坏处理,以便从原始样本视图构建出受损视图。参照了Xtab的方法,通过随机特征重采样来构建受损视图。具体来说,从一个训练批次的细胞中随机选择一部分基因子集,然后从同一训练批次内这些基因的经验边际分布中对这些基因的值进行重采样。将破坏比例设置为60%。这意味着对于每个细胞样本的原始视图及其受损视图,60%的基因值会被重采样,而40%的基因值保持不变。这种重采样策略将提供足够的扰动来增强模型的鲁棒性,同时保留足够的原始信息以维持生物学相关性。
表格建模架构
Tabula创新性地将单细胞数据(以细胞-基因矩阵形式呈现)视为类似于表格数据,并引入了带有注意力机制的表格Transformer,以促进对基因和细胞嵌入的无监督学习。此外,Tabula通过将模型划分为不同的客户端来处理跨组织的差异,每个客户端都配备了能够捕捉各组织特征的组织特异性嵌入器和投影头,同时还有一个共享的表格Transformer,用于存储跨组织的通用知识。需要注意的是,实施这种跨组织特定的客户端系统是为了展示联邦学习,不过一般来说,联邦学习可用于跨机构学习,通过避免机构间的数据共享来解决隐私问题,同时在预训练过程中还能从其他机构产生的数据中获取知识并从中受益。
与Tabula模型架构相关的四个主要模块为:嵌入器模块、表格Transformer模块、预训练目标以及协作式联邦学习框架。嵌入器模块将原始的细胞-基因表转换为嵌入向量,这些嵌入向量随后被用作表格Transformer的输入。接着,由FlashAttention-2驱动的表格Transformer利用这些嵌入向量,高效且有效地学习具有上下文信息的基因和细胞表征。表格Transformer的输出会由投影头进一步处理,以得出预训练损失。表格预训练目标基于自监督损失函数,该函数是通过细胞层面的行学习和基因层面的列学习,为细胞-基因表的学习量身定制的。协作式联邦学习框架模块详细说明了本地和全局表格变换器模型之间的更新过程。
TABULA零样本推断调控关系
左侧子图概述了Tabula通过迭代扰动零样本预测程序,预测调控基因与其靶基因之间跨细胞的成对调控的策略。(i) 这种迭代更新程序包括在各个细胞中持续将调控基因的基因表达排名提高或降低一位,然后在通过Tabula模型后对所有基因的表达进行零样本预测。接着,更新后的基因表达将作为下一次迭代的输入。(ii) 这样就可以得到在上述计算机模拟扰动下调控基因和靶基因的表达动态预测轨迹,随后可用于揭示调控基因 g 1 g_1 g1 对靶基因 g 2 g_2 g2 的影响。(iii) 靶基因表达分布图。迭代扰动前后靶基因的表达分布(中位数用红线表示)。默认情况下,该方法用于推断基因调控的类型,见(v)。(iv) 跨细胞调控比例图。跨细胞调控比例描绘了在所有细胞中,从调控基因到靶基因的激活、抑制(repressive)或中性调控模式的相对比例。(v) 根据迭代扰动前后的基因表达中位数,可以推断基因调控模式。在图示情况下,可以发现迭代扰动后 g 2 g_{2} g2 的表达下降,因此推断 g 1 g_1 g1 对 g 2 g_2 g2 存在抑制调控。注意,基于表达中位数的调控模式和跨细胞调控比例均可用于确定基因调控模式。
右侧子图以GATA1和FLI-1对EKLF的组合调控为例,说明了Tabula如何确定组合调控。首先枚举从GATA1和FLI1到EKLF的所有可能的布尔逻辑门,并按照左侧子图的程序进行迭代扰动预测,其中对GATA1和FLI1都执行扰动操作。请注意,如果在逻辑门上的值设为0(或者1),调控基因将使基因排名降低(或提高)一位。同样,根据在不同扰动输入下迭代过程中靶基因的表达动态,可以推断它与GATA1和FLI1对EKLF的组合逻辑相匹配。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









