







这几天有个任务需要用到对旋转目标的检测,而且目标大多数都是文字。所以和这个OCR任务十分相似,所以来对这类算法进行一个应用式的大致学习。首先说这个CTPN在之前阅读相关综述的时候就知道它其实对旋转目标的识别精度十分有限,但是一来本人对目标检测two-stage的算法还是理解的不是很透彻(原先用过目标检测,但基本上都是yolo系列的one stage算法),所以还是有必要精读一下这篇专于文本目标的基于深度学习的检测算法的开山之作,16年ECCV的CTPN。
一、核心idea
这篇文章还是提出了很多建设性的idea,主要的如下:
1.把整个文本框的回归问题化为多个小Anchors的回归问题,这样就大大提高了检测的精度,让网络能够很好地在小尺度文本候选框上回归。
2.文本检测的难点在于文本的长度是不固定,可以是很长的文本,也可以是很短的文本.如果采用通用目标检测的方法,将会面临一个问题:**如何生成好的text proposal**.针对上述问题,作者提出了一个vertical anchor的方法,具体的做法是只预测文本的竖直方向上的位置,水平方向的位置不预测。与faster rcnn中的anchor类似,但是不同的是,vertical anchor的宽度都是固定好的了,论文中的大小是16个像素。而高度则从11像素到273像素(每次除以0.7)变化,总共10个anchor。
3.采用RNN循环网络将检测的小尺度文本进行连接,得到文本行。
4.采用CNN+RNN端到端的训练方式,支持多尺度和多语言,避免后处理
5.为了最后生成的文本框能够精确地锁定文字,作者在回归anchor的中心纵坐标和高度的同时,也对边缘进行了回归,让最后得到的文本框左右和Ground Truth相差不会太大。

二、网络结构
文章的网络结构:
假设输入N副Images:
- 首先VGG提取特征,获得大小为
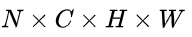 conv5 feature map。
conv5 feature map。 - 之后在conv5上做3*3的滑动窗口,即每个点都结合周围3*3区域特征获得一个长度为3*3*C的特征向量。输出
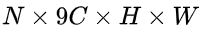 的feature map,该特征显然只有CNN学习到的空间特征。
的feature map,该特征显然只有CNN学习到的空间特征。 - 再将这个feature map进行Reshape:
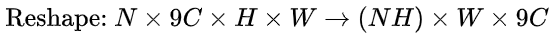
- 然后以Batch=NH且最大时间长度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









