









5个步骤将 Python 大文件处理代码性能提高 371%!
这篇博客将介绍如何将一段Python 大文件处理 代码运行速度从 29.3 秒运行时间提升到 6.3 秒,无需任何外部库!性能提升371%倍。
目标:分析存储在文本文件中的一些数据,提取第3列包含特定值的行。每行包含四个由空格分隔的数值,总共 46.66M 行。该文件的大小约为 1.11 GB,数据格式如下:
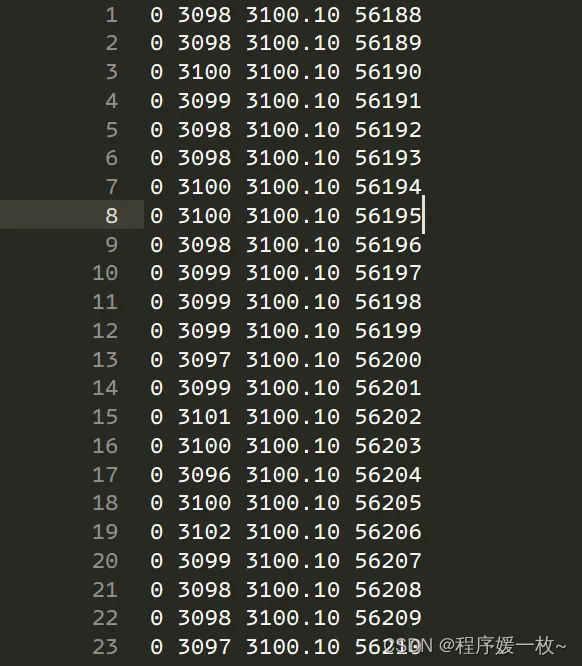
只需要提取第三列给定值的行(上图中的 3100.10) 尝试的第一件事是简单地使用 numpy.genfromtxt() 但它给出了内存错误,因为数据太大无法一次处理。
尝试将数据分割成更小的块并执行相同的操作,但是速度非常慢😫,因此尝试了各种方法以尽可能最快的方式完成工作。接下来展示代码以及如何优化。
最直接的方法
逐行遍历整个文件,包含特定值,写入新文件
- 29.3 s ± 56.7 ms
优化1: 循环不变性
查看代码,看看是否做了一些根本没有必要的事情。在迭代中,循环使用int(value)来比较值。可以通过提前一次性将值转换为int,并在循环中使用它来避免这种情况。这称为循环不变性
- 27.5 s ± 264 ms 通过更改一行代码,该代码比之前的代码获得了 6.5% 的性能提升。虽然提升幅度不大,但这是程序员很容易犯的错误。
优化2: 内存映射文件
内存映射文件是一种将整个文件加载到内存 (RAM) 中的技术,这比传统的文件 IO 快得多。传统IO使用多个系统调用从磁盘读取数据并通过多个数据缓冲区将其返回给程序。内存映射会跳过这些步骤并将数据复制到内存,从而提高性能(在大多数情况下)。 Python 有一个名为“mmap”的模块就是用于此目的。
- 22.8 s ± 124 ms 与之前的代码相比,其性能提高了 20%。
优化3:使用切片代替数据类型转换
在 int(float(line.split(b” “)[2]))==value 行中,对行进行切片以获取第三个元素,然后将字符串转换为 float,然后转换为 int 进行比较。
它就像“0 3098 3100.10 56188”->“3100.10:->3100.10->3100 现在不再使用 float 然后 int 将带小数的字符串转换为整数,而是使用切片,这导致了巨大的性能提升,因为字符串操作比数据转换更快。
- 20 秒 ± 171 仅仅改变一行代码,性能就比之前的代码提升了14%
优化4:使用find()查找操作
find()方法,在这之前一直在遍历各行,提取第三列值并进行比较,但这次使用查找操作来查找每行中所需的值。而且速度快得惊人!!
- 6.22 秒 ± 55.8 与之前的代码相比,性能提高了 221.5%。 与开始时相比,性能几乎提高了 4.7 倍。
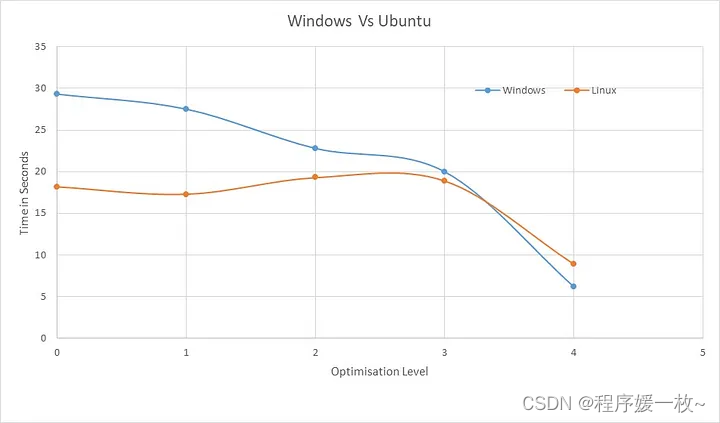
windows与linux优化效率对比
下面可以看到 Windows 10 与 ubuntu (22.04 LTS) 之间的比较!windows上提升更多,优化级别如下:
源码
# improve_effeciency.py
file = '1.txt'
# 最直接的方法:逐行遍历整个文件,包含特定值,写入新文件
def Function0():
output = "result.txt"
output_file = open(output, "w")
value = 3100.10
with open(file, "r") as f:
for line in f:
if (line != "\n"):
if (len(line.split(" ")) == 4):
try:
if (int(float(line.split(" ")[2])) == int(value)):
output_file.write(line)
except ValueError:
continue
f.close()
output_file.close()
# 0. 最直接的方法:逐行遍历整个文件,包含特定值,写入新文件
# 29.3 s ± 56.7 ms
# 优化1: 循环不变性 优化的第一步是查看代码,看看是否做了一些根本没有必要的事情。在迭代中,循环使用int(value)来比较值。可以通过一次将值转换为int,并在循环中使用它来避免这种情况。这称为循环不变性
def Function1():
output = "result.txt"
output_file = open(output, "w")
value = int(3100.10)
with open(file, "r") as f:
for line in f:
if (line != "\n"):
if (len(line.split(" ")) == 4):
try:
if (int(float(line.split(" ")[2])) == value):
output_file.write(line)
except ValueError:
continue
f.close()
output_file.close()
# 27.5 秒 ± 264 通过更改一行代码,该代码比之前的代码获得了 6.5% 的性能提升。虽然提升幅度不大,但这是程序员很容易犯的错误。
# 优化2: 内存映射文件 这是一种将整个文件加载到内存 (RAM) 中的技术,这比传统的文件 IO 快得多。传统IO使用多个系统调用从磁盘读取数据并通过多个数据缓冲区将其返回给程序。内存映射会跳过这些步骤并将数据复制到内存,从而提高性能(在大多数情况下)。 Python 有一个名为“mmap”的模块就是用于此目的。
import mmap
def Function2():
output = "result.txt"
output_file = open(output, "wb")
value = int(3100.10)
with open(file, "r+b") as f:
mmap_file = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
for line in iter(mmap_file.readline, b""):
if (line != b"\n"):
if (len(line.split(b" ")) == 4):
try:
if (int(float(line.split(b" ")[2])) == value):
output_file.write(line)
except ValueError:
continue
mmap_file.flush()
f.close()
output_file.close()
# 22.8 秒 ± 124 与之前的代码相比,其性能提高了 20%。
# 优化3:使用切片代替数据类型转换 在 int(float(line.split(b” “)[2]))==value 行中,对行进行切片以获取第三个元素,然后将字符串转换为 float,然后转换为 int 进行比较。
# 它就像“0 3098 3100.10 56188”->“3100.10:->3100.10->3100 现在不再使用 float 然后 int 将带小数的字符串转换为整数,而是使用切片,这导致了巨大的性能提升,因为字符串操作比数据转换更快。
def Function3():
output = "result.txt"
output_file = open(output, "wb")
value = int(3100.10)
with open(file, "r+b") as f:
mmap_file = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
for line in iter(mmap_file.readline, b""):
if (line != b"\n"):
if (len(line.split(b" ")) == 4):
try:
if (int(line.split(b" ")[2][:-3]) == value):
output_file.write(line)
except ValueError:
continue
mmap_file.flush()
f.close()
output_file.close()
# 20 秒 ± 171 仅仅改变一行代码,性能就比之前的代码提升了14%
# 优化4:使用查找操作 现在这是最后一颗钉子了,在这之前一直在遍历各行,提取第三列值并进行比较,但这次使用查找操作来查找每行中所需的值。而且速度快得惊人!!
def Function4():
output = "result.txt"
output_file = open(output, "wb")
value = int(3100.10)
value = (str(value) + ".").encode()
with open(file, "r+b") as f:
mmap_file = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
for line in iter(mmap_file.readline, b""):
find = line.find(value)
if (find >= 7 and find <= 11):
output_file.write(line)
mmap_file.flush()
f.close()
output_file.close()
# 6.22 秒 ± 55.8 与之前的代码相比,性能提高了 221.5%。 与开始时相比,性能几乎提高了 4.7 倍




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











