







目录
一.Abstract

VggNet全部采用3*3卷积核提取特征,并且将神经网络层数提高到16-19层(AlexNet只有8层,也可以说11层)并且在 ImageNet-2014在本地化和分类两个方向分别获得第一和第二名,并且表现最好的两个模型已经投入到未来研究中。
二.Introduction

简述了一下发展过程,意义不大。略
三.ConvNet Configuration

原文中并不太好理解网络架构,VGG16提供了更易理解的版本
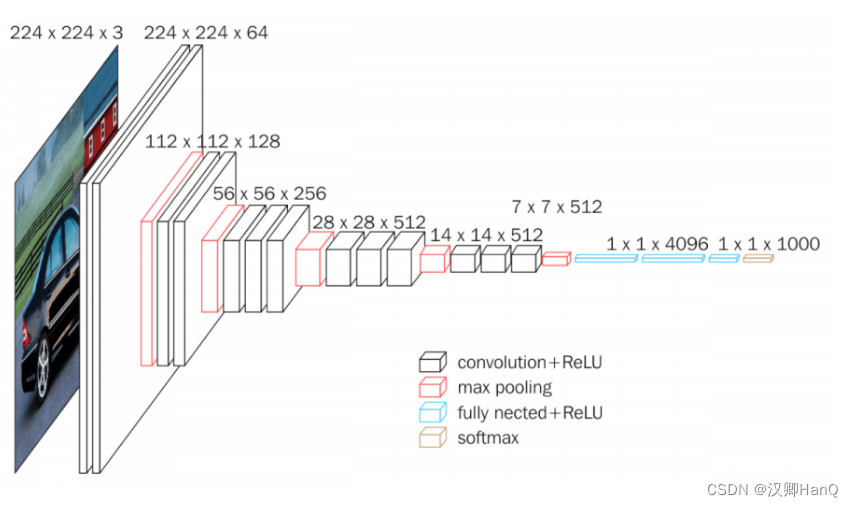
链接:VGG16 - Convolutional Network for Classification and Detection
3.1Architecture

在网络中,图像输入大小是224*224的RGB图像,所做的唯一预处理是从每个像素减去训练集上计算的平均值。使用3*3卷积核(stride=1)和1*1卷积核(2.3会详细说作用),并且进行padding=1操作,使用5个2*2max-pooling进行池化操作。
在卷积层后由三个FC(全连接层组成),分别为4096 4096 1000
在所有卷积操作后都加入了Relu进行非线性操作,并且与AlexNet不同的是去掉了LRN(4会详细说明LRN不会改善性能反而导致内存消耗和增加计算时间)
3.2Configuration

这里主要是为了2.3做铺垫,说明网络增加 ,但网络中的权重并不大于较浅的网络权重
3.3Discussion


不同于其他模型,VggNet使用细粒度更小的3*3卷积核进行提取特征,使用2个代替5*5,3个代替7*7 ,并且通过数学方法证明其更能节省参数且特征提取更加准确。


使用1*1卷积核提高模型的非线性

想了解更多可以见之前的博客:YOLO学习1.2-YOLOV1中部分术语含义和作用_汉卿HanQ的博客-CSDN博客

在不同模型中,不断将网络层数由11提高到19(为什么不更多了呢?),但其参数并没有出现爆炸式增加。可以在table 1看到,网络每经过一次max-pooling特征图个数就会增加,这是因为池化会丢失部分特征,因此通过增加特征图个数来弥补特征丢失。
四.Classification Framework

4.1Training

这里介绍了一些训练参数的设置和初始化
1.momentum=0.9
2.L2正则化=5*10^-4
3.Dropout=0.5
4.Learning rate=10^-2(当验证集准确度不变时,learning rate下降10^-1)
5.随机权重初始化:权重初始化为均值为0,方差为0.01的正态分布,偏差为0.
(作者论文提交后发现,可以不用上面的方法初始化权重而是直接使用 Glorot & Bengio(2010) 的随机初始化程序就能得到很好的效果)

6.图片输入大小:224*224
7.batch_size=256
关于图片的大小S使用了两种方法训练

1.第一种方法:固定 S,在实验中,评估模型用了两种图片大小:256 和 384。第一次训练固定图像大小 S = 256,为了加快 S = 384 的网络,将 S = 256 模型训练得到的参数作为 S = 384 模型的初始化权重,初始化学习率为 0.001。
2.第二种方法:多尺度的训练。不固定训练图片的大小,将其固定在一个范围中 [256, 512],在训练时,考虑到不同尺度的图片作为训练集训练网络对训练是有益的,也可以看做通过尺度抖动增加训练数据集。这样训练出来的模型可以识别各种大小的图片,由于速度方面的原因,我们训练多尺度模型的方法是对相同配置的单尺度模型的所有层进行微调,预先用固定的S = 384进行训练。
4.2Testing

在测试阶段,在使用一张测试图片的不同大小进行测试,最后取这些结果平均值作为结果也会改善其性能。
为了能够和全连接层连接上,在最后一个卷积层做一个max-pooling,这样即使不同大小的输入图像,通过最后一次池化,都可以连接在同一个全连接层。
为了增强数据集,通过水平翻转图像技术,最后将原始图片和反转图片结果平均值作为该图片的最终结果。
在评估网络时,把每张图片分为3个scale,每个裁处50个图片,这样一张图片九变成了150张。
4.3Implementation Detail

不同于AlexNet,VggNet使用单系统安装多GPU进行炼丹,因为梯度计算跨GPU同步 ,所以与单卡训练相同,在4张显卡的系统上,训练VggNet需要2-3周时间(因为层数增加,其训练时间比AlexNet要高出较多)
五.Classification Experiments

主要呈现了在 ILSVRC-2012 数据集上的分类结果,分类表现主要有两种评价指标:top-1 and top-5 errro,top-5 error 是 ILSVRC 的主要评价指标
5.1Single Scale Evaluation
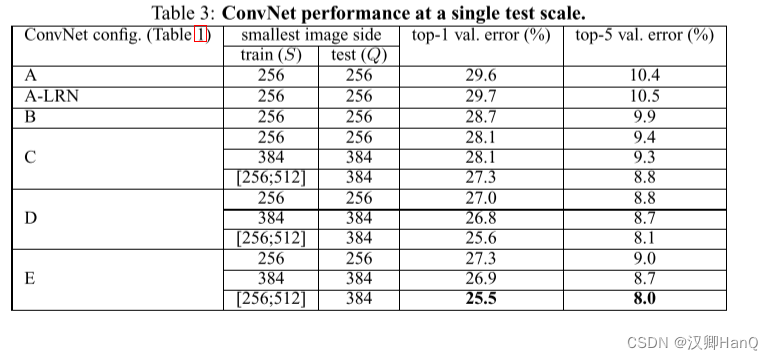
对于模型 A,A-LRN,B,它们都采用的是固定 S = 256,并且我们发现模型 A-LRN 的表现还没有模型 A 好,所以对于后面的模型,都没有使用 LRN(局部响应正则化),但是我们观察到从模型 A 到模型 B,随着深度的增加,top-1 和 top-5 error 也在下降。
再来观察模型 C、D、E,它们的 train 都测试了3种图片尺度,分别是 S=256,S=384,S=[256;512]。我们只看三个模型的 S=256 和 S=384,我们很容易发现不管哪一种模型,当 S=384,其模型的 top-1 和 top-5 是要优于 S=256 的。那是因为图片的分辨率越高,我们能够更容易捕捉到一些空间特征,所以其分类准确度就越高。
最后,我们再来看看的三种模型的 S=[256;512] 的这种情况,我们很容易发现这种情况的分类结果不管在哪一种模型中都是表现最好的。这也证明了通过尺度来扩充训练集确实有助于捕获多尺度图像统计。
5.2Multi Scale Evaluation


根据表格我们可以得出结论:在测试阶段的尺度抖动相较于单尺度的相同模型会有更好的表现。其中模型 D 和 E 表现最好。表现最好的单个网络在验证数据集上 top-1 和 top-5 error 达到了 24.8%/7.5%,在测试数据集上,模型 E 达到了 7.3 % 的 top-5 error。
5.3Multi Crop Evaluation
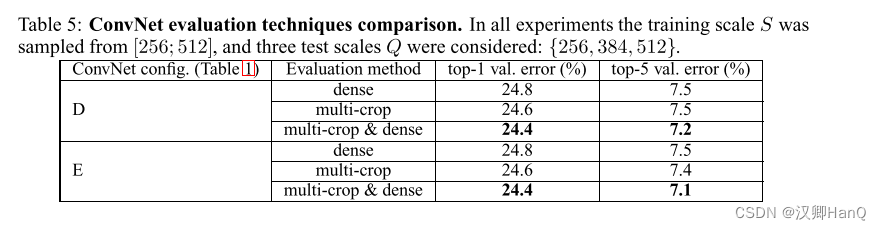
多裁剪评估。这里主要用到两种评估方法,一种是 dense,即评估时所使用的图片是整张图片,不经过任何裁剪。那么另一种就是 multi-crop,就是评估时使用的是裁剪后的图片。从评估结果来看使用Multi Crop比dense效果更好一些,而且因为两种方法是互补的,两种方法结合使用的表现比单独使用任何一种方法的效果都要好。
5.4Convent Fusion
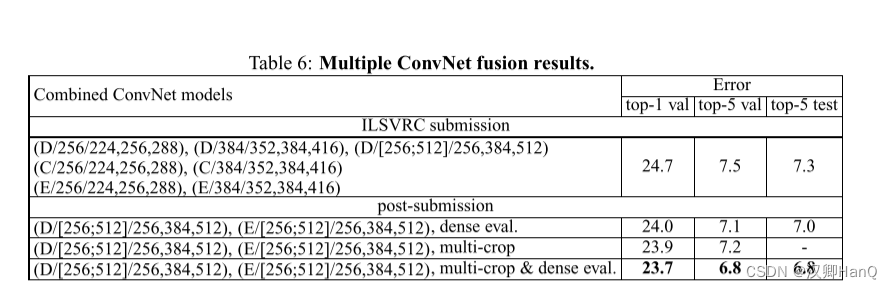
模型融合。通过融合几种模型,最后取各个模型的 soft-max 结果的平均值作为模型的输出,可以从实验结果发现,融合一个模型 D 和模型 E ,并且在评估时使用 multi-crop 和 dense 的方法得到的表现最好。
Comparison With The State Of The Art in ILSVRC classification
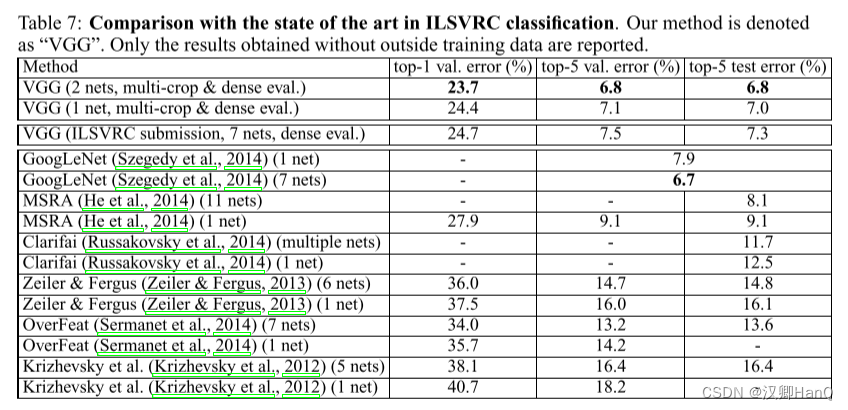
在 2014 年的挑战赛中,GoogLeNet 以 6.7% 的 error 夺冠,VGGNet 以 6.8% 的 error 获得第二名。但是如果从一个网络的分类准确度来看,VGG 是以 7.0% 的 error 要优于 GoogLeNet 的 7.9%。
六.Conclusion

在这项工作中,我们评估了用于大规模图像分类的非常深的卷积网络(多达19个权重层)。结果表明,表示深度对分类精度有好处,使用传统的 ConvNet 架构可以实现 ImageNet 挑战数据集的最先进的性能 (LeCun 等人,1989;Krizhevsky 等人,2012 年)大幅增加深度。在附录中,我们还展示了我们的模型可以很好地推广到广泛的任务和数据集,匹配或优于围绕较少深度图像表示构建的更复杂的识别管道。我们的研究结果再次证实了深度在视觉表现中的重要性。
七.Innovation point
1.整个网络采用3*3卷积核,提高特征提取细粒度,增加了神经网络深度,增加更多的线性变化,使用2个代替5*5,3个代替7*7还减少了参数数量。
2.引入1*1卷积核,在不影响输入输出维度情况下,引入非线性变化,增加网络表达能力,降低计算量等
3.通过预训练方式更好的初始化权重,加快训练的收敛速度
4.采用Multi-Scale的方式训练和预测,可扩充数据集,防止过拟合,提高准确率
5.提高了网络深度到16-19层
6.舍弃了AlexNet LRN层
7.采用了多个池化层,这些池化层使用了较小的池化窗口(通常是2x2)和较大的步长,从而减少了特征图的尺寸,同时有效地减少了计算量。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









