






自然语言处理之N-gram模型
该模型的核心思想是我们每个人想说的下一个字都基于之前我们所说的话得到一个条件分布,在这个条件概率中最大的那个字作为我们想要说的下一个字。比如我说举头望明月,低头思故。然后就从所有的汉字里面以这九个字作为条件,之后哪个字出现的概率是最大的,那就是相对应的那个字。
N-gram模型基于这样一个假设,第n个词的出现只与前面n-1个词相关,而与其他词都不相关。整句话的概率就是各个词出现概率的乘积。它是一个语言模型(language model),一个基于概率的判别模型,输入一句话,输出的是这句话出现的概率,也就是这些词的联合概率。
N-gram模型常见的有Uni-gram,Bi-gram,Tri-gram。其中
Uni-gram:假设不考虑任何的条件概率
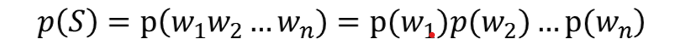
Bi-gram:后一个词的出现只依赖于前一个词
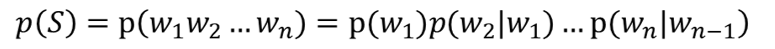
Tri-gram:后一个词的出现依赖于前两个词
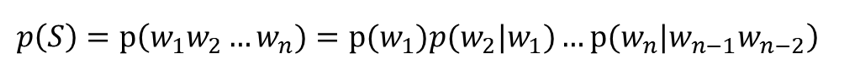
举个栗子:
以Bi-gram为例,假如我们有这样一个语料库

在上面的语料库中不难发现 “I”出现了3次,“I am"出现了1次,因此可以计算概率:
p(am|I)=1/3
如果我们想要计算出I am sunny这句话出现的概率,则需要计算
p(I|)=2/3,p(am|I)=1/3,p(sunny|am)=1/3,p(|sunny)=2/3
则
p(I am sunny)=1/3x2/3x1/3x1/3x2/3=4/243
该模型的优缺点:
其中常用的就是Bi-gram,Tri-gram模型,而且效果还不错,但是高于四元的就用的很难少了,因为训练它需要很庞大的语料,而且数据稀疏严重,时间复杂度高,精度却没有提升多少。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











