







注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
TODO:
这篇真不错,用简单例子讲清RNN和LSTM
还讲了梯度消失和爆炸的原因以及解决方法
循环网络 Recurrent Network
回到之前的 N-gram 语言模型:
- 可以简单地通过数单词频次实现(并配上smoothing)
- 也可以通过前馈神经网络实现
- 在生成句子这块,以 trigram model为例,我们会根据前面两个单词以及第三个单词同时出现的概率来判断是否下一个单词是正确的:
I saw a
I saw a table
I saw a table is
I saw a table is round
I saw a table is round and 至此都还比较通顺
I saw a table is round and about 但这一次生成的单词就不咋样。 - 造成这个原因是因为有限的上下文。
因此有了…
1 循环神经网络(Recurrent Neural Networks)
1.1 RNN
循环神经网络简称 RNN
- 允许表示任意大小的输入
- 核心思想:通过应用递归公式,一次处理一个输入序列
- 使用一个状态向量来表示以前处理过的上下文
这个递归公式如下:
s
i
=
f
(
s
i
−
1
,
x
i
)
s
i
+
1
=
f
(
s
i
,
x
i
+
1
)
s_i = f(s_{i-1},x_i)\\ s_{i+1} = f(s_i,x_{i+1})
si=f(si−1,xi)si+1=f(si,xi+1)
其中,
s
i
s_i
si是新状态,
s
i
−
1
s_{i-1}
si−1是前一个状态,
x
i
x_i
xi是输入。
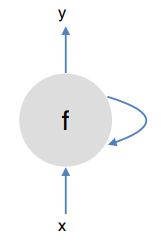
即,上一递归函数的值是下一个递归函数的输入。
这个函数
f
f
f即RNN函数:
s
i
=
t
a
n
h
(
W
s
s
i
−
1
+
W
x
x
i
+
b
)
s_i=tanh(W_ss_{i-1}+W_xx_i+b)
si=tanh(Wssi−1+Wxxi+b)
这个函数和之前的前馈神经网络不同的就是,多了一个循环的过程,也就是我们的输入多了前一个状态的信息。
1.2 RNN展开

如果把递归的过程展开(根据时间轴展开),就可以得到上面这幅图,这是一个最简单的 RNN 。
s
i
=
t
a
n
h
(
W
s
s
i
−
1
+
W
x
x
i
+
b
)
y
i
=
σ
(
W
y
s
i
)
s_i = tanh(W_ss_{i-1}+W_xx_i+b)\\ y_i = \sigma(W_ys_i)
si=tanh(Wssi−1+Wxxi+b)yi=σ(Wysi)
这里除了生成状态信息
s
i
s_i
si,还会输出一个
y
i
y_i
yi可以理解为当前的输出结果。比如说之前的文本生成,
y
i
y_i
yi即每一个新生成的单词,然后下一个单词生成的依据是前一个状态(过去记忆总结)和新的输入。
注意:每个函数中的参数都是一样的,会被用在所有时间步中。
举例:拿之前奶牛吃草的例子

最开始的输入是一个单词 a,然后经过第一轮简单的递归(仅包含
s
0
s_0
s0 状态)得到输出
y
1
=
“
c
o
w
”
y_1=“cow”
y1=“cow”,然后
s
1
s_1
s1总结前面单词的信息,把它传递到下一个函数用来判断 a 后面生成什么单词会好一点。
- 现在下方红圈是当前输入 x i = “ e a t s ” x_i=“eats” xi=“eats”(也是上一个函数的输出),把它对应到word embedding之后,作为输入。
- s i − 1 s_{i-1} si−1包含了前面单词的信息(“a cow”)
- y i = " g r a s s " y_i="grass" yi="grass"是输出的单词,也是下一个函数的输入。
1.3 训练RNN
-
一个展开的RNN只是一个非常深的神经网络。这里虽然在计算状态4,并输入状态3和 x 4 x_4 x4,但实际上需要递归计算到状态0那步。

-
但参数在所有时间步骤中都是共享的
-
为了训练RNN,我们只需要在给定的输入序列中创建展开的计算图。
-
并像往常一样使用反向传播算法来计算梯度
-
这个过程被称为通过时间的反向传播(backpropagation through time)(可参看RNN的反向传播)。
例子:
接着把之前奶牛吃草的例子拿出来:

假设要训练的语料库只有一句话 “a cow eats grass”
那么现在词汇表里只有 [a, cow, eats, grass]
带入函数:
s
i
=
t
a
n
h
(
W
s
s
i
−
1
+
W
x
x
i
+
b
)
y
i
=
s
o
f
t
m
a
x
(
W
y
s
i
)
s_i = tanh(W_ss_{i-1}+W_xx_i+b)\\ y_i = softmax(W_ys_i)
si=tanh(Wssi−1+Wxxi+b)yi=softmax(Wysi)
- 先将单词转换成 one-hot 向量 x i x_i xi作为输入,然后通过 W x x i W_xx_i Wxxi变成了word embedding形式,再结合先前 s i − 1 s_{i-1} si−1状态的线性变换 W s s i − 1 W_ss_{i-1} Wssi−1,以及偏置向量 b b b,一起输入到 t a n h tanh tanh函数中,从而计算到隐藏状态 s i s_i si。
- 对于第一个初始状态 s 0 s_0 s0来说,我们可以简单地设置为 0,也可以将其随机初始化,然后通过模型来学习到一个好的 s 0 s_0 s0。
- 得到 y 1 y_1 y1每个词的分布概率之后,我们知道 a 后面是 cow ,所以在看 cow 所在位置的概率为 0.3,然后计算log损失/交叉熵损失)。随后将 cow 座位下一个时间步的输入,再结合之前的状态…以此类推。
- 最终训练结束,我们会得到cow, eats, grass 这三个单词的损失函数值(求平均或者求和),然后想办法优化model,这样就得出了一个模型。
1.4 RNN 生成句子

利用上面训练好的模型来做测试,这里为了简单,就仍然用奶牛吃草这句话当测试集。选取
y
1
y_1
y1概率分布中概率最高的单词即我们想要生成的单词(cow),然后将它作为下一个函数的输入…
1.5 RNN生成模型的潜在问题
- 训练和解码之间的不匹配(因为存在损失,而且我们假设的是概率最高的那个就是最好的,但在整句话中不一定是最合适的)
- 错误传播:无法从中间步骤的错误中恢复过来 (因为会出现概率最高但不是最合适的情况出现,再加上后面生成的会基于前面已经生成的句子来判断,所以有时会错上加错)
- 倾向于产生 "平淡(bland) "或 "通用(generic) "语言(由于选取的是概率最高的,所以如果这类词/组合经常出现,那一定会有很高的概率,那这就相当于生成一些“废话”)
2 长短期记忆网络
Long Short-Term Memory Networks,简称 LSTM
回顾: 语言模型
- RNN的递归能力,看似有能力根据无限的上下文来搭建模型
- 但它现实中真的能看到很长范围的文字依赖关系吗?不行,因为会存在梯度消失(vanishing gradients)
- 简单来说,随着时间推移(或者句子逐渐变长),梯度会越来越小,以至于到很后面时,最开始输入的几个单词已经不会对当前的单词产生很大影响,从而导致他们的参数也不会得到太多更新。
- 由于反向传播,所以在后面的时间步中的梯度会迅速减小。(后期会写详细一篇RNN梯度消失的原因)
- 最早输入的状态没有得到太多的更新。
因此引入了长短期记忆网络…
2.1 LSTM
- 引入LSTM来解决梯度消失问题
- 核心思想:有 “记忆单元”,可以跨越时间储备梯度。
- 对记忆单元的访问由 "门 (gates)"控制
- 对于每个输入,一个门可以决定:
- 有多少新的输入应该被写入存储单元中。
- 当前存储单元的内容应被遗忘多少。
2.2 门(gate)
- gate g 是一个向量,向量中的每个元素的值都在0~1之间。
- g 与向量 v 是分量(component-wise)相乘,即元素之间对应相乘。通过这种形式对向量 v 中的信息进行保留。
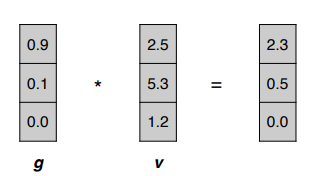
(可以理解为,2.5可以有百分之90的信息被留下 ,变为2.3) - g 是通过sigmoid函数来产生的,这样值就会在 0 ~ 1 之间。
2.3 简单RNN vs. LSTM
简单 RNN
下图中有三个时间步:
x
t
−
1
,
x
t
,
x
t
+
1
x_{t-1}, x_t, x_{t+1}
xt−1,xt,xt+1,只有一个简单的函数 tanh 处理 ,将
x
t
x_t
xt和之前的状态
h
t
−
1
h_{t-1}
ht−1处理得到新的状态
h
t
h_t
ht,再循环往复。

LSTM
先看下面一条线,处理过程不只一个 tanh 函数,总共包含四个交互层(sigmoid,sigmoid,tanh,sigmoid),其中三个sigmoid函数对应了LSTM中的三个门。下面这条线表示前一个状态向量,上面那条表示记忆细胞,记忆细胞可以算是另一种状态向量,只不过是用于存储较长时间跨度上的依赖关系(就相当于对以前那些状态的某些记忆)。

2.4 LSTM:遗忘门(Forget Gate)
第一个门是遗忘门(forget gate),公式表示如下所示:
f
t
=
σ
(
W
f
⋅
[
h
t
−
1
,
x
t
]
+
b
f
)
f_t = \sigma(W_f \cdot [h_{t-1},x_t]+b_f)
ft=σ(Wf⋅[ht−1,xt]+bf)
其中,
σ
\sigma
σ函数为了生成 0 - 1值,
[
h
t
−
1
,
x
t
]
[h_{t-1},x_t]
[ht−1,xt]将两向量合并,
h
t
−
1
h_{t-1}
ht−1是前一个状态,
x
t
x_t
xt是当前输入(word embedding)。

- 控制在记忆细胞中 "遗忘 "多少信息(记忆细胞即上面一条线的 C t − 1 C_{t-1} Ct−1)。
- 以 “The cats that the boy likes” 为例,当前记忆细胞
C
t
−
1
C_{t-1}
Ct−1 存储的名词信息是 cats,当读到 boy 之后,细胞应该忘记 cats 而是存入 boy 从而能正确预测后面动词的单数形式 likes。
简单来说就是把前面一个状态的内容忘记一点(进行筛选过滤)。
2.5 LSTM:输入门(Input Gate)
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C t ~ = t a n h ( W C ⋅ [ h t − 1 , x t ] + b C ) i_t=\sigma(W_i\cdot[h_{t-1},x_t]+b_i)\\ \tilde{C_t}=tanh(W_C\cdot[h_{t-1},x_t]+b_C) it=σ(Wi⋅[ht−1,xt]+bi)Ct~=tanh(WC⋅[ht−1,xt]+bC)
- 第一个公式表示 输入门主要是控制有多少新的信息要被放进记忆细胞
-
C
t
~
\tilde{C_t}
Ct~表示要加入记忆细胞的 蒸馏信息(distilled information) ,以此处的 “boy” 为例,相当新加入的信息(注意:这里没有使用 sigmoid 函数)

2.6 LSTM:更新记忆细胞
公式:
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
t
~
C_t=f_t*C_{t-1}+i_t*\tilde{C_t}
Ct=ft∗Ct−1+it∗Ct~
其中
f
t
f_t
ft 是遗忘门,
i
t
i_t
it 是输入门,
C
t
~
\tilde{C_t}
Ct~指新信息。
所以我们通过遗忘门和输入门去更新记忆细胞,即遗忘部分信息然后新加入部分信息。

2.7 LSTM:输出门(Output Gate)
公式:
o
t
=
σ
(
W
o
⋅
[
h
t
−
1
,
x
t
]
+
b
o
)
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
o_t = \sigma(W_o\cdot[h_{t-1},x_t]+b_o)\\ h_t = o_t*tanh(C_t)
ot=σ(Wo⋅[ht−1,xt]+bo)ht=ot∗tanh(Ct)
输出门控制记忆细胞中能蒸馏出多少信息从而生成下一个状态
h
t
h_t
ht

2.8 LSTM: 总结

遗忘门,输入门,输出门,蒸馏新信息,更新记忆斯堡,输出新状态。

李宏毅老师这篇视频28分处ppt动态举例LSTM,可以观看。
LSTM的缺点是什么:
- 仍然无法捕捉到非常长距离的依赖关系(一整个document的时候就很不好)
- 比简单的RNN慢得多(因为包含更多的计算)
3 应用
RNN和LSTM可以有很多生成类应用:
- 莎士比亚生成器:所有的训练数据是莎士比亚的创作
- 维基百科生成器:训练数据是100mMB的维基百科原始数据
- 代码生成器
- 莎士比亚十四行诗生成器
\
RNN还可以应用于:
- 文本分类:尤其是可以应用于需要单词顺序的任务(情感分类)

- 序列标注
对于序列标注问题也很不错(比如词性标注)

4 LSTM的变体
4.1 Peephole连接
Peephole 连接(peephole connections)是LSTM的一种变体。
- 它除了参考
h
t
−
1
h_{t-1}
ht−1前一个状态和
x
t
x_t
xt 输入以外,还会考虑到上一个记忆细胞的信息。
f t = σ ( W f [ C t − 1 , h t − 1 , x t ] + b f ) f_t=\sigma(W_f[C_{t-1},h_{t-1},x_t]+b_f) ft=σ(Wf[Ct−1,ht−1,xt]+bf)
4.2 门控循环单元(GRU)
门控循环单元(Gated recurrent unit,GRU)是另一种变体。
相比LSTM,它取消了记忆细胞,并且只有两个门。一个是更新门
z
t
z_t
zt,另一个是重置门
r
t
r_t
rt 。"然后我们计算 蒸馏隐藏状态
h
t
~
\tilde{h_t}
ht~ ,它表示我们从当前输入中提取到的希望加入隐藏状态的信息,和之前的
C
t
~
\tilde{C_t}
Ct~ 类似,但计算过程有些差别:其中包含了当前输入
x
t
x_t
xt 和之前的隐藏状态
h
t
−
1
h_{t-1}
ht−1,并且在计算之前,我们还将重置门
r
t
r_t
rt 和之前的隐藏状态
h
t
−
1
h_{t-1}
ht−1 中的对应元素相乘。重置门
r
t
r_t
rt 的作用是在计算蒸馏隐藏状态前,将之前的隐藏状态
h
t
−
1
h_{t-1}
ht−1 中某些无用的元素归零。然后,我们用更新门
z
t
z_t
zt 来更新隐藏状态。相比 LSTM 中更新记忆细胞时使用两个独立的门(遗忘门和输入门),GRU 在更新隐藏状态时只用到了一个更新门:这里
z
t
z_t
zt 扮演了类似输入门的角色,而
(
1
−
z
t
)
(1-z_t)
(1−zt) 则扮演了类似遗忘门的角色。
实践中,GRU 和 LSTM 的性能相当,并且由于少了一个门和记忆细胞,GRU 的参数要比 LSTM 少一些。但是,GRU 并没有在参数数量上取得太大的优势,因为绝大部分(90% 左右)的参数集中在嵌入矩阵中,所以节省一个门可能只是减少了几百/几千个参数,而这些减少对于训练一个很大的模型并没有太大差别。"


4.3 多层LSTM


“我们可以叠加多层 LSTM 来处理这个问题:我们将前一层 LSTM 的输出结果作为下一层 LSTM 的输入,以此类推,将最后一层输出结果作为下一个单词。
实践中,在训练数据充足的情况下,多层 LSTM 的表现要优于单层 LSTM。从直觉上,在靠近原始输入层的底层 LSTM 中,其捕获到的更多是一些句法 (syntactic) 相关的信息,例如,词性标签 (POS) 等;而在更上层的 LSTM 中,其捕获到的更多是一些更加高层次的语义 (semantic) 方面的信息,例如,语篇 (discourse) 结构层面的信息,这也是其比单层 LSTM 效果更好的原因。”
4.4 双向LSTM

y
i
=
s
o
f
t
m
a
x
(
W
x
[
s
i
,
u
i
]
)
y_i=softmax(W_x[s_i,u_i])
yi=softmax(Wx[si,ui])
“双向 LSTM 包含一个从左至右的 LSTM 和一个从右至左的 LSTM。当我们处理一个给定单词时,它将结合第一个 LSTM 从左至右的隐藏状态 s i s_i si 和第二个 LSTM 从右至左的隐藏状态 u i u_i ui,所以,我们无法用它来预测下一个单词。因此,我们无法用双向 LSTM 来实现语言模型。
但是,双向 LSTM 很适合处理序列标注问题,例如:词性标注。假设我们现在需要预测单词 “cow” 的词性,第一个方向的 LSTM 提供了 “cow” 之前的单词的词性,而第二个方向的 LSTM 则提供了 “cow” 之后的单词的词性,这使得我们在预测单词 “cow” 的词性时,有了更多可以利用的信息。
计算过程也非常简单,只需要将两个方向的状态连接,然后进行线性变换,输入 softmax 函数即可得到可能的词性概率分布向量。”
总结
- 优点:
- 具有捕捉远距离背景的能力
- 与前馈网络一样:灵活
- 缺点:
- 由于顺序处理,速度比前馈网络慢
- 实际应用中不能很好地捕捉长范围的依赖(在生成很长的文本时很明显)。
- 在实践中也不能很好地堆叠(对于多层LSTM来说)。
- 由于更多先进架构(transformer!)的出现,如今已不再流行















 4980
4980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









