










Fast-RCNN基本实现端对端(除了proposal阶段外),下一步自然就是要把proposal阶段也用CNN实现(放到GPU上)。这就出现了Faster-RCNN,一个完全end-to-end的CNN对象检测模型。
一、经典的Fast RCNN存在的问题:
region proposal的提取仍然采用selective search,整个检测流程时间大多消耗在这上面(生成region proposal大约2~3s,而特征提取+分类只需要0.32s)。这一点也是Faster RCNN的改进之一。
二、网络模型
不再使用SS算法提取候选区域,而是采用RPN(区域生成网络)生成ROI,RPN集成到Fast RCNN中一起训练,可以大大提高效率。

1.区域生成网络

得到最终用来预测的feature map: 图片在输入网络后,依次经过一系列conv+relu (套用ImageNet上常见的分类网络即可 本论文实验了5层的ZF,16层的VGG-16)得到的feature map,额外添加一个conv+relu层,输出5139256维特征(feature map)。准备后续用来选取proposal,并且此时坐标依然可以映射回原图。
计算Anchors: 在feature map上的每个特征点预测多个region proposals。具体作法是:把每个特征点映射回映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同scale、aspect ratio的anchor。共51*39个中心,每个中心生成9个候选框(3种面积{128*128,256*256,512*512}×3个aspect ratio {1:1,1:2,2:1} )。

样本
考察训练集中的每张图像:
a. 对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
b. 对a)剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本
c. 对a),b)剩余的anchor,弃去不用。
d. 跨越图像边界的anchor弃去不用
代价函数
同时最小化两种代价:
a. 分类误差
b. 前景样本的窗口位置偏差
2.共享特征
区域生成网络(RPN)和fast RCNN都需要一个原始特征提取网络(下图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
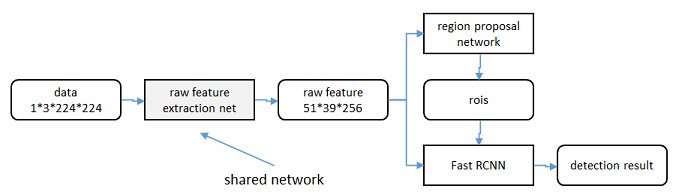
轮流训练
a. 从W0W0开始,训练RPN。用RPN提取训练集上的候选区域
b. 从W0W0开始,用候选区域训练Fast RCNN,参数记为W1W1
c. 从W1W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
近似联合训练
直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
联合训练
直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。
三、改进与不足
-
改进:
- 将生成候选区域的任务交给神经网络,简化步骤,提高速度。 不足:
- ROI pooling layer两次量化,无法将feature map与原像素精准对齐。生成的ROI不够准确。这一点是Mask RCNN的改进之一。
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











