









论文地址:https://arxiv.org/abs/1406.2661
翻译后的论文地址:深度学习:生成式对抗网络,让机器在博弈中实现“自我成长” - 前沿洞察 - 恒生研究院 (hundsun.com)
一、论文核心要点:
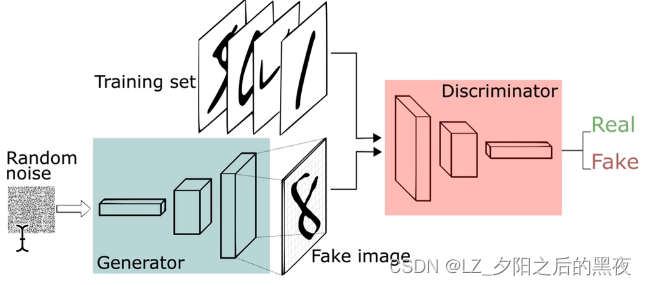
- 提出了一个基于对抗的新生成式模型,它由一个生成器和一个判别器组成
- 生成器的 目标是学习到样本的数据分布,从而能生成样本欺骗判别器;判别器的目标是判断输入样本是生成/真实的概率
- GAN模型等同于博弈论中的二人零和博弈
- 对于任意的生成器和判别器,都存在一个独特的全局最优解
- 生成器和判别器都由多层感知机实现,整个网络可以用反向传播算法来训练
- 通过实验的定性与定量分析显示,GAN的潜力很大
二、研究背景:
1、判别式模型
- 模型学习的是条件概率分布P(Y|X):(X成立时Y成立的样本数)/(X成立的样本数)
- 任务是从属性X(特征)预测标记Y(类别)
- 线性回归、逻辑回归、K近邻(KNN)、支持向量机(SVM)、决策树、条件随机场(CRF)、boosting方法
2、生成式模型
- 模型学习的是联合概率分布P(X,Y):(X与Y同时成立的样本数)/(总样本数)
- 任务是得到属性为X且类别为Y时的联合概率
- 朴素贝叶斯、混合高斯模型、隐马尔科夫模型(HMM)、贝叶斯网络、马尔可夫随机场、深度信念网络(DBN)、变分自编码器(VAE)
3、零和博弈
- 一方的收益必须意味着另一方的损失,博弈各方的收益和损失相加永远为“零”,双方不存在合作的可能
4、Minimax
- 在零和博弈中,为了使己方达到最优解,所以把目标设为让对方的最大收益最小化
5、GAN历史意义
- 使AI具备了图像视频的创作编辑能力
- 启发了无/弱监督学习的研究
6、GAN应用领域
- 图像生成 Image Generation
- 图像转换 Image Translation
- 图像编辑 Image Editing
三、论文结构
- 提出GAN模型
- 解决问题,模型组成,训练方式
- 无向图莫下,DBNs,GSN,VAE
- 价值函数
- 训练过程,全局最优性,收敛性
- 结果比对,生成图像展示
- 各方法综合比对
- 条件生成式模型
1、价值函数
x:从真实数据中的采样
data:真实数据
D:判别器,输出值为0(假)或1(真),代表输入来自真实数据的概率,D(x)属于0~1,二分类神经网络
z:随机噪声
G:生成器,输出为合成数据
x~Pdata(x):真实数据服从的概率分布
Pz(z):随机噪声服从的概率分布
D的目标是最大化加载函数V,对数函数log在底数大于1时,为单调函数,最大化V就是最大化D(x)和1-D(G(z)),队任意的x,都有D(x)=1和D(G(z))=0,即判别器对真实数据的采样判定为真实数据,对生成器生成的数据判断为合成数据。
G的目标是针对特定的D,去最小化价值函数V,最小化V就是最小化D(x)、1-D(G(z)),对任意的z都有D(G(z))=1,即使判别器对来自生成器的数据都认为是合成的数据。
在训练开始时,G性能较差,D(G(z))接近0,此时,log(1-D(G(z)))的梯度值较小,log(D(G(z)))的梯度值较大,把G的目标改为最大化log D(G(z)),在早期学习在能提供更强的梯度。
gan.py
import jittor as jt
from jittor import init
from jittor import nn
from jittor.dataset.mnist import MNIST
from jittor.dataset.dataset import ImageFolder
import jittor.transform as transform
import argparse
import os
import numpy as np
from loguru import logger
import time
import cv2
jt.flags.use_cuda = 1
logger.add('BCELoss_celebA_log.log')# 生成训练日志文件
img_save_path = './images'# 生成器生成的图片保存地址
os.makedirs(img_save_path, exist_ok=True)
model_save_path = './save_models'# 训练完的模型保存地址
os.makedirs(model_save_path, exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument('--n_epochs', type=int, default=2000, help='训练的时期数')
parser.add_argument('--batch_size', type=int, default=64, help='批次大小')
parser.add_argument('--lr', type=float, default=0.0002, help='学习率')
parser.add_argument('--b1', type=float, default=0.5, help='梯度的一阶动量衰减')
parser.add_argument('--b2', type=float, default=0.999, help='梯度的一阶动量衰减')
parser.add_argument('--n_cpu', type=int, default=8, help='批处理生成期间要使用的 cpu 线程数')
parser.add_argument('--latent_dim', type=int, default=100, help='潜在空间的维度')
parser.add_argument('--img_size', type=int, default=28, help='每个图像尺寸的大小')
parser.add_argument('--sample_interval', type=int, default=10000, help='图像样本之间的间隔')
parser.add_argument('--channels', type=int, default=3, help='图像通道数')
parser.add_argument('--dataclass', type=str, default='celebA', help='数据集类型')
parser.add_argument('--train_dir', type=str, default='./Dataset/CelebA_train', help='数据集地址')
# parser.add_argument('--channels', type=int, default=1, help='图像通道数')
# parser.add_argument('--dataclass', type=str, default='MNIST', help='数据集类型')
# parser.add_argument('--train_dir', type=str, default='./Dataset/MNIST', help='数据集地址')
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
# 保存生成器生成的图片样本数据
def save_image(img, path, nrow=None):
N,C,W,H = img.shape# (25, 1, 28, 28)
'''
[-1,700,28] , img2的形状(1,700,28)
img[0][0][0] = img2[0][0]
img2:[
[1*28]
......(一共700个)
](1,700,28)
'''
img2=img.reshape([-1,W*nrow*nrow,H])
# [:,:28*5,:],img:(1,140,28)
img=img2[:,:W*nrow,:]
for i in range(1,nrow):#[1,5)
'''
img(1,140,28),img2(1,700,28)
img从(1,140,28)->(1,140,28+28)->...->(1,140,28+28+28+28)=(1,140,140)
np.concatenate把两个三维数组合并
'''
img=np.concatenate([img,img2[:,W*nrow*i:W*nrow*(i+1),:]],axis=2)
# img中的数据大小从(-1,1)--(+1)-->(0,2)--(/2)-->(0,1)--(*255)-->(0,255)转换成了像素值
img=(img+1.0)/2.0*255
# (1,140,140)--->(140,140,1)
# (channels通道数,imagesize,imagesize)转化为(imagesize,imagesize,channels通道数)
img=img.transpose((1,2,0))
# 根据地址保存图片样本数据
cv2.imwrite(path,img)
# 生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(scale=0.2))
return layers
self.model = nn.Sequential(*block(opt.latent_dim, 128, normalize=False), *block(128, 256), *block(256, 512), *block(512, 1024), nn.Linear(1024, int(np.prod(img_shape))), nn.Tanh())
def execute(self, z):
img = self.model(z)
img = img.view((img.shape[0], *img_shape))
return img
# 判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(nn.Linear(int(np.prod(img_shape)), 512), nn.LeakyReLU(scale=0.2), nn.Linear(512, 256), nn.LeakyReLU(scale=0.2), nn.Linear(256, 1), nn.Sigmoid())
def execute(self, img):
img_flat = img.view((img.shape[0], (- 1)))
validity = self.model(img_flat)
return validity
# bce loss分类器 (b这里指的是binary,所以用于二分类问题)
'''
源码:
class BCELoss(Module):
def __init__(self, weight=None, size_average=True):
self.weight = weight
self.size_average = size_average
def execute(self, output, target):
return bce_loss(output, target, self.weight, self.size_average)
# weight:表示对loss中每个元素的加权权值,默认为None
# size_average:指定输出的格式,包括'mean','sum'
# output:判别器对生成的数据的判别结果(64*1)
# target:判别器对真实的数据的判别结果(64*1)
def bce_loss(output, target, weight=None, size_average=True):
# jt.maximum(x,y):返回x和y的元素最大值
# 公式:损失值 = -权重*[ 理想结果*log(判别结果) + (1-理想结果)*log(1-判别结果) ]
loss = - (
target * jt.log(jt.maximum(output, 1e-20))
+
(1 - target) * jt.log(jt.maximum(1 - output, 1e-20))
)
if weight is not None:
loss *= weight
if size_average:
return loss.mean()# 求均值
else:
return loss.sum()# 求和
'''
# 对抗性损失函数
adversarial_loss = nn.BCELoss()
# 初始化生成器和判别器
generator = Generator()
discriminator = Discriminator()
# 配置数据加载器
def DataLoader(dataclass, img_size, batch_size, train_dir, eval_dir):
if dataclass == 'MNIST':
Transform = transform.Compose([
transform.Resize(size=img_size),
transform.Gray(),
transform.ImageNormalize(mean=[0.5], std=[0.5])])
train_loader = MNIST (data_root=train_dir, train=True, transform=Transform).set_attrs(batch_size=batch_size, shuffle=True)
eval_loader = MNIST (data_root=eval_dir, train=False, transform = Transform).set_attrs(batch_size=1, shuffle=True)
else:
# celebA数据集中有20万张图片,每张图片的尺寸178*218
Transform = transform.Compose([
transform.Resize(size=img_size),
transform.ImageNormalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5])])
train_loader = ImageFolder(train_dir)\
.set_attrs(transform=Transform, batch_size=batch_size, shuffle=True)
eval_loader = ImageFolder(eval_dir)\
.set_attrs(transform=Transform, batch_size=batch_size, shuffle=True)
return train_loader, eval_loader
# 加载训练集数据
train_loader, eval_loader = DataLoader(dataclass=opt.dataclass,
img_size=opt.img_size,
batch_size=opt.batch_size,
train_dir=opt.train_dir,
eval_dir=opt.train_dir)
# 优化器
optimizer_G = jt.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = jt.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
warmup_times = -1
run_times = 3000
total_time = 0.
cnt = 0
# ----------
# 训练
# ----------
for epoch in range(opt.n_epochs):#[1,2000),2000次迭代
for (i, (real_imgs, _)) in enumerate(train_loader):# 938
'''
valid表示真,全为1,fake表示假,全为0
img.shape[0]:图像的垂直尺寸(高度)h
[ [1.0]...(一共h个)...[1.0] ] 64*1的数组
'''
valid = jt.ones([real_imgs.shape[0], 1]).stop_grad()
fake = jt.zeros([real_imgs.shape[0], 1]).stop_grad()
# --------------------- 训练生成器 ---------------------
# TODO 第一步:生成服从正态分布的噪音数据
'''
随机生成一个符合正态分布的噪声,numpy.random.normal(loc=0.0, scale=1.0, size=None)
loc:正态分布的均值,对应着这个分布的中心,0说明这一个以Y轴为对称轴的正态分布
scale:正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦
shape:(图片的高度h,潜在空间的维度100) == (64,100) == z.shape
'''
z = jt.array(np.random.normal(0, 1, (real_imgs.shape[0], opt.latent_dim)).astype(np.float32))
# TODO 第二步:生成器加载噪音数据生成图片数据[64,1,28,28]
'''
gen_imgs的形状:(64,1,28,28), 64*1中每个元素都是28*28
[
[28*28]
...... (一共64个28*28)
]
'''
gen_imgs = generator(z)
# TODO 第三步:根据生成数据的判别结果和真的数据(都是64*1)计算损失值
'''
把生成的图片数据放进判别器中,让判别器对其进行分类,计算出数据可能是真实数据的概率值(0-1之间的数)
valid当作是判别器分类的结果,全为1说明判别器认为这个数据来源于真实图片
adversarial_loss会调用bce_loss求损失值
因为我们需要使生成器生成的数据越来越像真实的数据,所以我们需要这两个数据越来越相似[discriminator(gen_imgs)和valid]
loss(x,y)=-w*[ylogx+(1-y)log(1-x)]
生成器理想条件下,discriminator(gen_imgs)=1,loss(1,1)=0
'''
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
# TODO 第四步:反向传播,训练生成器的参数
optimizer_G.step(g_loss)
# --------------------- 训练判别器 ---------------------
# TODO 第一步:根据训练集中的数据和真的数据计算损失值
'''
real_imgs:加载的训练集数据
把训练集数据放进判别器,得到判别器对训练集数据的判别结果,计算出数据可能是真实数据的概率值
valid当作是判别器分类的结果,全为1说明判别器认为这个数据来源于真实图片
因为我们需要使判别器把训练集数据判别为真实数据,所以我们需要使这两个数据越来越相似[discriminator(real_imgs), valid]
loss(x,y)=-w*[ylogx+(1-y)log(1-x)]
判别器理想条件下,discriminator(real_imgs)=1,loss(1,1)=0
'''
real_loss = adversarial_loss(discriminator(real_imgs), valid)#
# TODO 第二步:根据生成数据的判别结果和假的数据(都是64*1)计算损失值
'''
gen_imgs:生成器生成的图片数据
把生成的图片数据放进判别器中,让判别器对其进行分类,计算出数据可能是真实数据的概率值(0-1之间的数)
fake当作是判别器分类的结果,全为0说明判别器认为这个数据来源于生成的数据,而不是真实现实中的数据
调用bce_loss求损失值
因为我们需要使判别器能识别出机器生成的图片数据,所以我们需要使这两个数越来越相似[discriminator(gen_imgs), fake]
loss(x,y)=-w*[ylogx+(1-y)log(1-x)]
判别器理想条件下,discriminator(gen_imgs)=0,loss(0,0)=0
'''
fake_loss = adversarial_loss(discriminator(gen_imgs), fake)#
# TODO 第三步:对这两个损失值求平均
d_loss = ((real_loss + fake_loss) / 2)
# TODO 第四步:反向传播,训练判别器的参数
optimizer_D.step(d_loss)
# ---------------------
# 打印训练进度,打印生成器和判别器的损失值
# 保存生成器生成的图片样本数据
# ---------------------
if warmup_times==-1:
'''
D loss:判别器的损失值,越小越好(0-1的数)
G loss:生成器的损失值,越小越好(0-1的数)
numpy():把Var数据类型的数据转换成array数据类型
'''
# [0,200) * 938 + [0,938) = [0,199*938+937] = [0,187599]
batches_done = ((epoch * len(train_loader)) + i)
# opt.sample_interval = 10000 , 187599 / 400 = 468
if ((batches_done % opt.sample_interval) == 0):
loss_log = '[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]' % (epoch, opt.n_epochs, i, len(train_loader), d_loss.numpy()[0], g_loss.numpy()[0])
print(loss_log)# 打印每次训练的损失值
logger.debug(loss_log)# 把每次训练的损失值保存到日志文件中去
# gen_imgs.data[:25] -> (25, 1, 28, 28)
path = os.path.join(img_save_path, '%d.png'%batches_done)# 图片保存路径
save_image(gen_imgs.data[:25], path, nrow=5)
else:
jt.sync_all()
cnt += 1
print(cnt)
if cnt == warmup_times:
jt.sync_all(True)
sta = time.time()
if cnt > warmup_times + run_times:
jt.sync_all(True)
total_time = time.time() - sta
print(f"run {run_times} iters cost {total_time} seconds, and avg {total_time / run_times} one iter.")
exit(0)
# 没训练10个批次,保存一次模型
if (epoch+1) % 10 == 0:
generator.save(os.path.join(model_save_path,'BCE_generator_celebA.pkl'))
discriminator.save(os.path.join(model_save_path,'BCE_discriminator_celebA.pkl'))
gan_model_load_test.py
import jittor as jt
from jittor import init
from jittor import nn
import argparse
import numpy as np
import cv2
jt.flags.use_cuda = 1
parser = argparse.ArgumentParser()
parser.add_argument('--latent_dim', type=int, default=100, help='潜在空间的维度')
parser.add_argument('--img_size', type=int, default=28, help='每个图像尺寸的大小')
parser.add_argument('--channels', type=int, default=1, help='图像通道数')
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
# 生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(scale=0.2))
return layers
self.model = nn.Sequential(*block(opt.latent_dim, 128, normalize=False), *block(128, 256), *block(256, 512), *block(512, 1024), nn.Linear(1024, int(np.prod(img_shape))), nn.Tanh())
def execute(self, z):
img = self.model(z)
img = img.view((img.shape[0], *img_shape))
return img
# 判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(nn.Linear(int(np.prod(img_shape)), 512), nn.LeakyReLU(scale=0.2), nn.Linear(512, 256), nn.LeakyReLU(scale=0.2), nn.Linear(256, 1), nn.Sigmoid())
def execute(self, img):
img_flat = img.view((img.shape[0], (- 1)))
validity = self.model(img_flat)
return validity
def deal_image(img, path=None, nrow=None):
N,C,W,H = img.shape# (25, 1, 28, 28)
'''
[-1,700,28] , img2的形状(1,700,28)
img[0][0][0] = img2[0][0]
img2:[
[1*28]
......(一共700个)
](1,700,28)
'''
img2=img.reshape([-1,W*nrow*nrow,H])
# [:,:28*5,:],img:(1,140,28)
img=img2[:,:W*nrow,:]
for i in range(1,nrow):#[1,5)
'''
img(1,140,28),img2(1,700,28)
img从(1,140,28)->(1,140,28+28)->...->(1,140,28+28+28+28)=(1,140,140)
np.concatenate把两个三维数组合并
'''
img=np.concatenate([img,img2[:,W*nrow*i:W*nrow*(i+1),:]],axis=2)
# img中的数据大小从(-1,1)--(+1)-->(0,2)--(/2)-->(0,1)--(*255)-->(0,255)转换成了像素值
img=(img+1.0)/2.0*255
# (1,140,140)--->(140,140,1)
# (channels通道数,imagesize,imagesize)转化为(imagesize,imagesize,channels通道数)
img=img.transpose((1,2,0))
if path:
# 根据地址保存图片样本数据
cv2.imwrite(path,img)
cv2.imshow('1',img)
cv2.waitKey(0)
# 初始化生成器和判别器,并加载模型,训练了2000批次
generator = Generator()
g_model_path = "./save_models/BCE_generator.pkl"
generator.load_parameters(jt.load(g_model_path))
generator.load(g_model_path)
discriminator = Discriminator()
d_model_path = "./save_models/BCE_discriminator.pkl"
discriminator.load_parameters(jt.load(d_model_path))
discriminator.load(d_model_path)
z = jt.array(np.random.normal(0, 1, (64, opt.latent_dim)).astype(np.float32))
gen_imgs = generator(z)
deal_image(gen_imgs.data[:25], "./images_test/BEC_1.png",nrow=5)














 1991
1991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









