






论文标题;MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
论文链接:2303.09975.pdf (arxiv.org)![]() https://arxiv.org/pdf/2303.09975.pdf
https://arxiv.org/pdf/2303.09975.pdf
论文: MedNeXt:用于医学图像分割的转换器驱动的ConvNets缩放
摘要
人们对采用基于TransformerTM的架构进行医学图像分割的兴趣与日俱增。然而,由于缺乏大规模的标注医学数据集,使得获得与自然图像相同的性能具有挑战性。相比之下,卷积网络具有更高的感应偏差,因此很容易训练成高性能。最近,ConvNeXt架构试图通过镜像变压器块来实现标准ConvNet的现代化。在这项工作中,我们对此进行了改进,以设计一种现代化的、可扩展的卷积体系结构,以应对数据稀缺的医疗环境的挑战。本文介绍了一种Transformer型的大核分割网络MedNeXt,它引入了
1)完全ConvNeXt 3D编解码器网络用于医学图像分割,
2)剩余的ConvNeXt上下采样块以保持跨尺度的语义丰富,
3)通过对小核网络进行上采样来迭代增加核大小,以防止有限医疗数据的性能饱和,
4)MedNeXt的多层次(深度、宽度、核大小)的复合伸缩。
这导致了在CT和MRI模式和不同数据集大小的4个任务上的最先进的性能,代表了医学图像分割的现代化深度架构。
1 介绍
Transformers在医学图像分割中被广泛采用,作为混合架构的组件或独立技术,以实现最先进的性能。学习远程空间依赖关系的能力是Transformer架构在视觉任务中的主要优势之一。然而,由于其有限的归纳偏差,Transformers受到大型注释数据集的必要性的困扰,以最大限度地提高性能优势。虽然这些数据集在自然图像中很常见(ImageNet-1 k ,ImageNet-21 k ),但医学图像数据集通常缺乏丰富的高质量注释。为了保留卷积固有的归纳偏差,同时利用变压器的架构改进,最近引入了ConvNeXt ,以重新建立卷积网络对自然图像的竞争性能。ConvNeXt架构使用了一个反向瓶颈,反映了Transformers的瓶颈,由一个深度层、膨胀层和收缩层组成。除了大的依赖性内核,以复制其可扩展性和远程表示学习。作者将大型内核ConvNeXt网络与巨大的数据集配对,以超越以前最先进的基于Transformer的网络。相比之下,堆叠小内核的VGGNet 方法仍然是设计医学图像分割中ConvNet的主要技术。开箱即用的数据高效解决方案,如nnUNet,使用标准UNet 的变体,在广泛的任务中仍然有效。
ConvNeXt架构将Vision和Swin Transformers的可扩展性和远程空间表示学习能力与ConvNets的固有归纳偏差相结合。此外,反向瓶颈设计允许我们扩展宽度(增加通道),同时不受内核大小的影响。在医学图像分割中的有效使用将允许以下益处:
1)通过大内核学习长距离空间依赖性,
2)不那么直观,同时缩放多个网络级别。
要实现这一点,需要一些技术来对抗大型网络在有限的训练数据上过度拟合的趋势。尽管如此,最近已经尝试将大内核技术引入医学视觉领域。在[18]中,通过将内核分解为dependency和dependency扩张内核来使用大内核3D-UNet [5],以提高器官和脑肿瘤分割的性能-探索内核缩放,同时使用恒定数量的层和通道。ConvNeXt架构本身用于3D-UX-Net [17],其中SwinUNETR [8]的Transformer被ConvNeXt块取代,以实现多个分割任务的高性能。然而,3D-UX-Net仅在标准卷积编码器中部分使用这些块,限制了它们可能的好处。
在这项工作中,我们最大限度地发挥了ConvNeXt设计的潜力,同时独特地解决了医学图像分割中有限数据集的挑战。我们提出了第一个完全ConvNeXt 3D分割网络MedNeXt,这是一个可扩展的编码器-解码器网络,并做出了以下贡献:
- 我们利用纯粹由ConvNeXt块组成的架构,使ConvNeXt设计具有网络范围的优势。
- 我们引入了残差反向瓶颈来代替常规的上采样和下采样块,以保持上下文的丰富性,同时重新调整以利于密集分割任务。修改后的残差连接特别改善了训练期间的梯度流。
- 我们引入了一种简单但有效的迭代增加内核大小的技术UpKern,通过使用经过训练的上采样小内核网络进行初始化来防止大内核MedNeXts的性能饱和。
- 由于我们的网络设计,我们建议应用多个网络参数的复合缩放,允许宽度(通道),感受野(内核大小)和深度(层数)缩放的正交性。
MedNeXt相对于由基于transformer的卷积和大型内核网络组成的基线实现了最先进的性能。我们在不同模态(CT,MRI)和大小(范围从30到1251个样本)的4个任务上显示了性能优势,包括器官和肿瘤的分割。我们提出MedNeXt作为标准ConvNets的强大和现代化的替代方案,用于构建医学图像分割的深度网络。
2 方法
2.1 完全ConvNeXt 3D分割架构
在以前的工作中,ConvNeXt将Vision Transformers和Swin Transformers的架构见解提炼成卷积架构。ConvNeXt模块继承了Transformers的许多重要设计选择,旨在限制计算成本,同时扩展网络,这表明与标准ResNet相比,性能有所改善。在这项工作中,我们利用这些优势,采用ConvNeXt的总体设计作为类似3D-UNET宏观体系结构的构建块,以获得MedNeXt。我们还将这些块扩展到上采样层和下采样层,形成了第一个用于医学图像分割的完全ConvNeXt体系结构。宏体系结构如图1a所示。MedNeXt块(类似于ConvNeXt块)具有3层镜像变压器块,C通道输入说明如下:
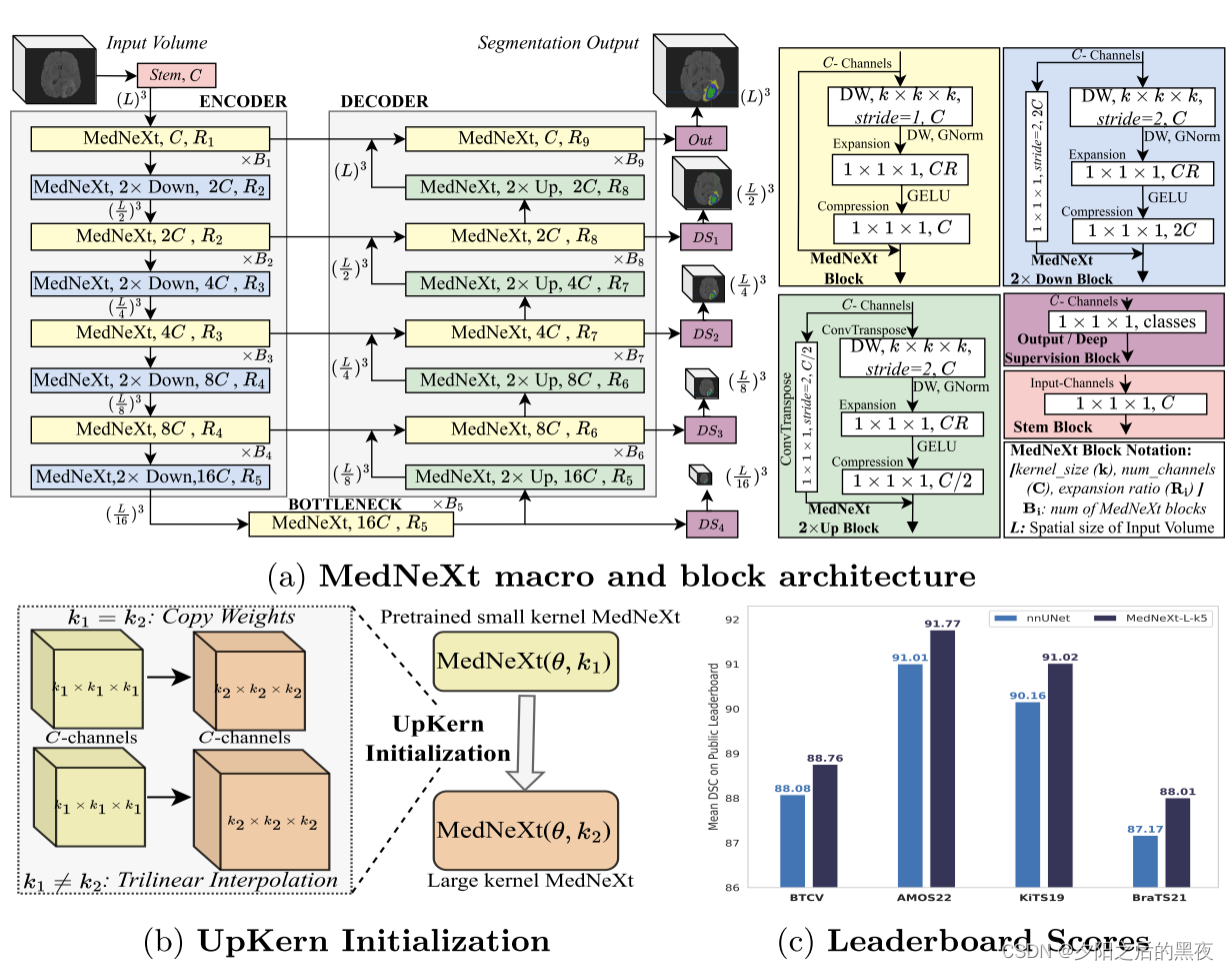
1.去卷积层:这一层包含一个内核大小为k × k × k的Dependency卷积,然后进行归一化,输出通道为C。我们使用通道式GroupNorm [32]来实现小批量的稳定性[27],而不是原始的LayerNorm。卷积的依赖性允许这一层中的大内核复制Swin-Transformers的大注意力窗口,同时限制计算,从而将“繁重的工作”委托给扩展层。
2.扩展层:对应于Transformers中的类似设计,该层包含具有CR输出通道的过完备卷积层,其中R是扩展比,然后是GELU激活。较大的R值允许网络在计算1×1×1内核限制时进行宽度扩展。重要的是要注意,这一层有效地将宽度缩放与前一层中的感受野(内核大小)缩放相结合。
3.压缩层:卷积层,具有1×1×1内核和C输出通道,执行特征图的通道压缩。
MedNeXt是卷积的,并保留了ConvNets固有的归纳偏差,允许在稀疏医学数据集上进行更容易的训练。我们的完全ConvNeXt架构还支持在标准和上/下采样层进行宽度(更多通道)和感受野(更大的内核)缩放。除了深度缩放(更多层),我们还探索了这3种正交缩放类型,以设计一种复合可扩展MedNeXt,用于有效的医学图像分割。
2.2 剩余反向瓶颈恢复
最初的ConvNeXt设计使用了独立的下采样层,这些下采样层由标准的跨距卷积组成。一个等价的上采样块将是标准跨距转置卷积。但是,此设计不会在重采样时隐式利用宽度或基于内核的ConvNeXt缩放。我们通过将反向瓶颈扩展到MedNeXt中的重采样块来改进这一点。这是通过在分别用于下采样和上采样MedNeXt块的第一深度层中插入步进卷积或转置卷积来实现的。相应的通道减少或增加被插入到我们的MedNeXt 2×Up或Down块设计的最后一个压缩层中,如图1a所示。此外,为了实现更容易的梯度流,我们增加了1×1×1卷积的残差连接或步长为2的转置卷积。这样做,MedNeXt充分利用了Transformers反向瓶颈的优势,在其所有组件中以较低的空间分辨率保留了丰富的语义信息,这将有利于密集医学图像分割任务。
2.3 UpKern:无饱和的大核卷积
大卷积核近似于Transformers中的大注意力窗口,但仍然容易出现性能饱和。自然图像分类中的ConvNeXt架构,尽管具有ImageNet-1 k和ImageNet-21 k等大型数据集的优势,但在大小为7×7×7的内核上饱和。医学图像分割任务具有显著较少的数据,并且在大型内核网络中性能饱和可能是一个问题。为了提出一个解决方案,我们从Swin Transformer V2 中汲取灵感,其中一个大注意力窗口网络被另一个用较小注意力窗口训练的网络初始化。具体来说,Swin Transformers使用偏置矩阵B ∈ R(2 M −1)×(2 M −1)来存储学习到的相对位置嵌入,其中M是注意力窗口中的补丁数量。在增加窗口尺寸时,M增加并且需要更大的B。作者提出了将现有的偏置矩阵空间插值到更大的尺寸作为预训练步骤,而不是从头开始训练,这证明了性能的提高。我们提出了一个类似的方法,但定制卷积内核,如图1b所示,以克服性能饱和。UpKern允许我们通过对大小不兼容的卷积核(表示为张量)进行三线性上采样,用兼容的预训练小核网络初始化大核网络,从而迭代地增加核大小。具有相同张量大小的所有其他层(包括归一化层)通过复制未更改的预训练权重来初始化。这导致了一种简单但有效的MedNeXt初始化技术,它有助于大型内核网络克服医学图像分割常见的相对有限的数据场景中的性能饱和。
2.4 深度、宽度和感受野的复合标度
复合缩放[29]是这样一种想法,即在多个级别(深度,宽度,感受野,分辨率等)上同时缩放提供了超越单一级别缩放的好处。在3D网络中无限缩放核大小的计算要求很快变得令人望而却步,并导致我们在不同级别上同时进行缩放。与图1a保持一致,我们的缩放测试了块计数(B),扩展比(R)和内核大小(k)-对应于深度,宽度和感受野大小。我们使用MedNeXt的4种型号配置来完成此操作,详见表1(左)。基本功能设计(MedNeXt-S)使用的通道数(C)为32,R = 2,B = 2。其他变体仅在R(MedNeXt-B)或R和B(MedNeXt-M)上增加。最大的70-MedNext-block架构使用高R和B值(MedNeXt-L),用于证明MedNeXt能够显著扩展依赖性(即使在标准内核大小下)。我们进一步探索大的内核大小,并对每种配置进行k = {3,5}的实验,以通过MedNeXt架构的复合缩放来最大化性能。
















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









