






文章思路
缩写说明
- G-FSD:Generalized Few-Shot Object Detection
- 本文算法:Retentive RCNN
- base classes、base dataset: C b \boldsymbol{C_b} Cb、 D b \boldsymbol{D_b} Db
- novel classes、novel dataset: C n \boldsymbol{C_n} Cn、 D n \boldsymbol{D_n} Dn
- base model : f b \boldsymbol{f^b} fb
- novel model : f n \boldsymbol{f^n} fn
算法
- 整个流程:1.基于 D b \boldsymbol{D_b} Db训练一个 f b \boldsymbol{f^b} fb 2.基于 D n \boldsymbol{D_n} Dn(或者组合 D n \boldsymbol{D_n} Dn和 D b \boldsymbol{D_b} Db)微调 f b \boldsymbol{f^b} fb从而训练一个 f n \boldsymbol{f^n} fn
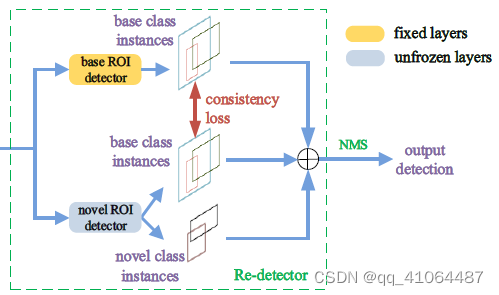
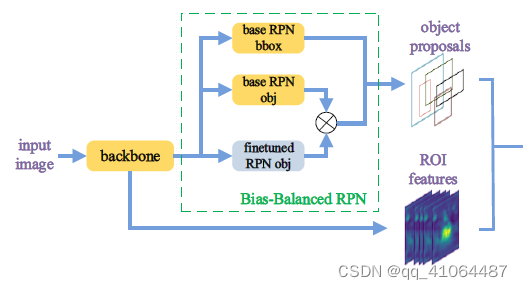
- 框架包括两个大部分:1.Bias-Balanced RPN 2. Re-detector
- Re-detector :有两个并行的detector,同时从RPN产生的proposal中预测 C b \boldsymbol{C_b} Cb以及 C b ∪ C n \boldsymbol{C_b∪C_n} Cb∪Cn。预测 C b \boldsymbol{C_b} Cb的detector(缩写为 d e t b \boldsymbol{det^b} detb)的权重和 f b \boldsymbol{f^b} fb中一样。另一个detector就是用来微调的,缩写为 d e t n \boldsymbol{det^n} detn。
| detector | 权重 | 结构 |
|---|---|---|
| d e t b \boldsymbol{det^b} detb | 和 f b \boldsymbol{f^b} fb中一样 | fully-connected layer for classification |
| d e t n \boldsymbol{det^n} detn | 不固定,微调 | cosine 分类器 |
为了让
d
e
t
n
\boldsymbol{det^n}
detn继承
d
e
t
b
\boldsymbol{det^b}
detb的信息,让两个detector在检测base class能结果相似,因此提出一致性loss函数
L
c
o
n
\boldsymbol{L_{con}}
Lcon,加在
d
e
t
n
\boldsymbol{det^n}
detn原有的classification loss和box regression loss后面形成Re-detector总的loss函数。
- Bias-Balanced RPN:只有objectness分支在进行微调,bbox regression被冻结,参数和预训练相同。微调阶段的objectness打分根据base objectness分数和finetuned objectness分数取最大值。
可尝试
- 特征范数:特征的L2范数代表了当前输入下对特征的激活情况。作者研究了基于 D b \boldsymbol{D_b} Db预训练的一个R-CNN网络, C b \boldsymbol{C_b} Cb、 C n \boldsymbol{C_n} Cn经过网络后输出的ROI特征的L2范数,seen class的范数普遍比没见过的class范数大,比较unseen class里面的一些和见过的class相似的class的范数会偏大,由于cosine similarity对特征范数不敏感,所以可以有效区分
- KL散度形式的一致性loss
- TFA算法是baseline
联系其他文章
- f b \boldsymbol{f^b} fb 具有稳定性,遇到novel class也不会产生FP,能够很好的保存来自 D b \boldsymbol{D_b} Db的信息,比较LSTD中TK的思路,差别在:TK是计算对于novel class两个模型预测出来的可能性最高的分类结果之间的熵,而本文是计算每个proposal对于每个class的置信度与base之间的熵。
- RPN 也有类别倾向性,因此不能微调的时候冻结。FSCE在微调classification和regression分支的同时,也unfroze了RPN和ROI 特征提取层(冻结backbone、ROI pooling),不过解冻有解冻的附加手段(见FSCE文章)。














 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









