







ComfyUI入门教程01——模型下载以及使用
前言
本篇教程可以衔接自《WSL-Debian部署ComfyUI》教程。
一、准备材料
1.1 完成前置教程操作
1.2 CivitAI网址:【https://civitai.com/?1=1】
1.3 本篇教程依然不会涉及到任何【科学上网】相关的内容
二、操作步骤
2.1 访问CivitAI
该网站如下图所示:
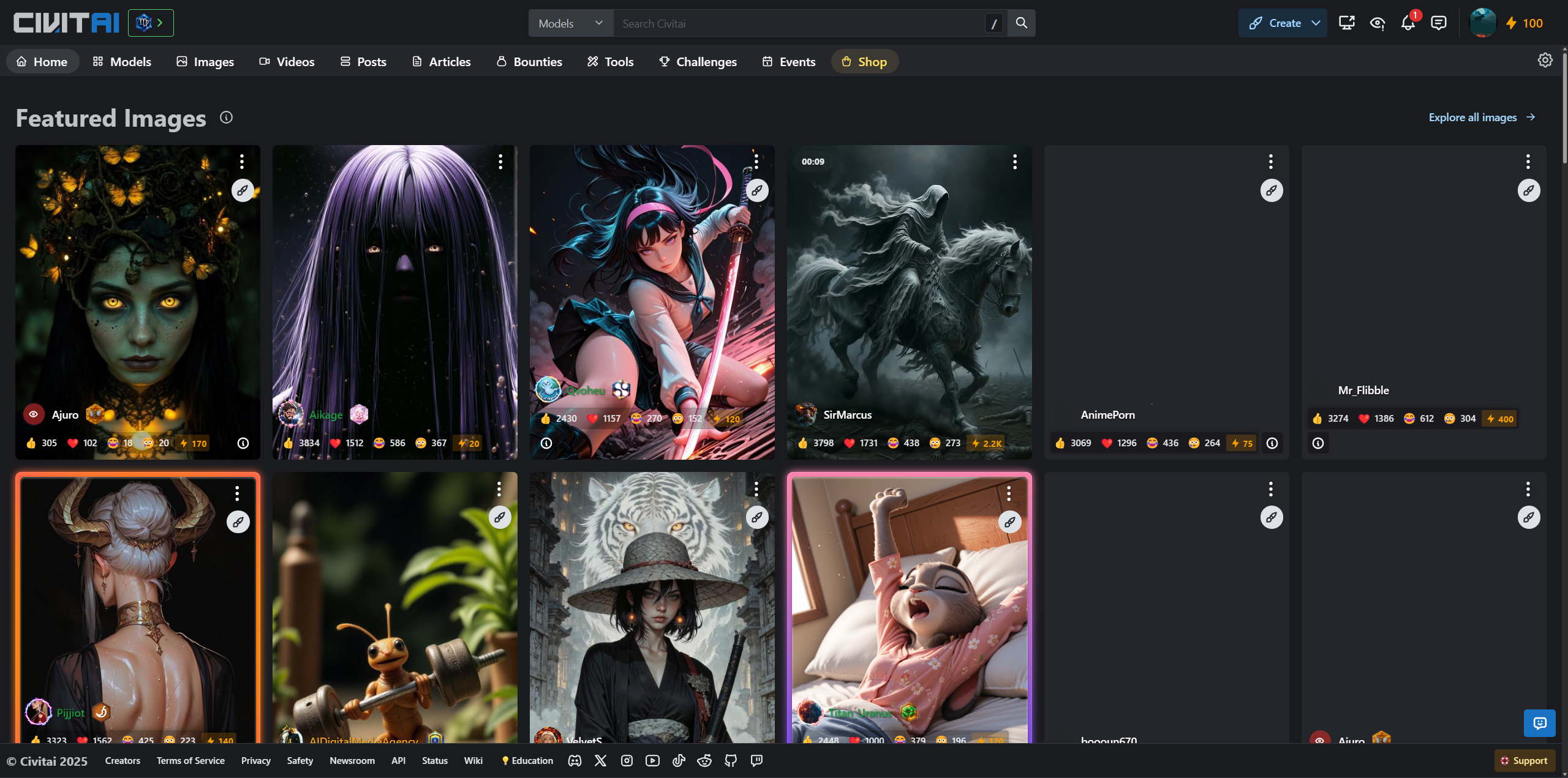
简单介绍:
(1).建议注册账号登录,因为某些模型的下载需要账号登录
(2).导航栏有很多选项,但是较为常用的是【Models】选项
点击Models即可访问到该网站的所有模型,如下图所示:
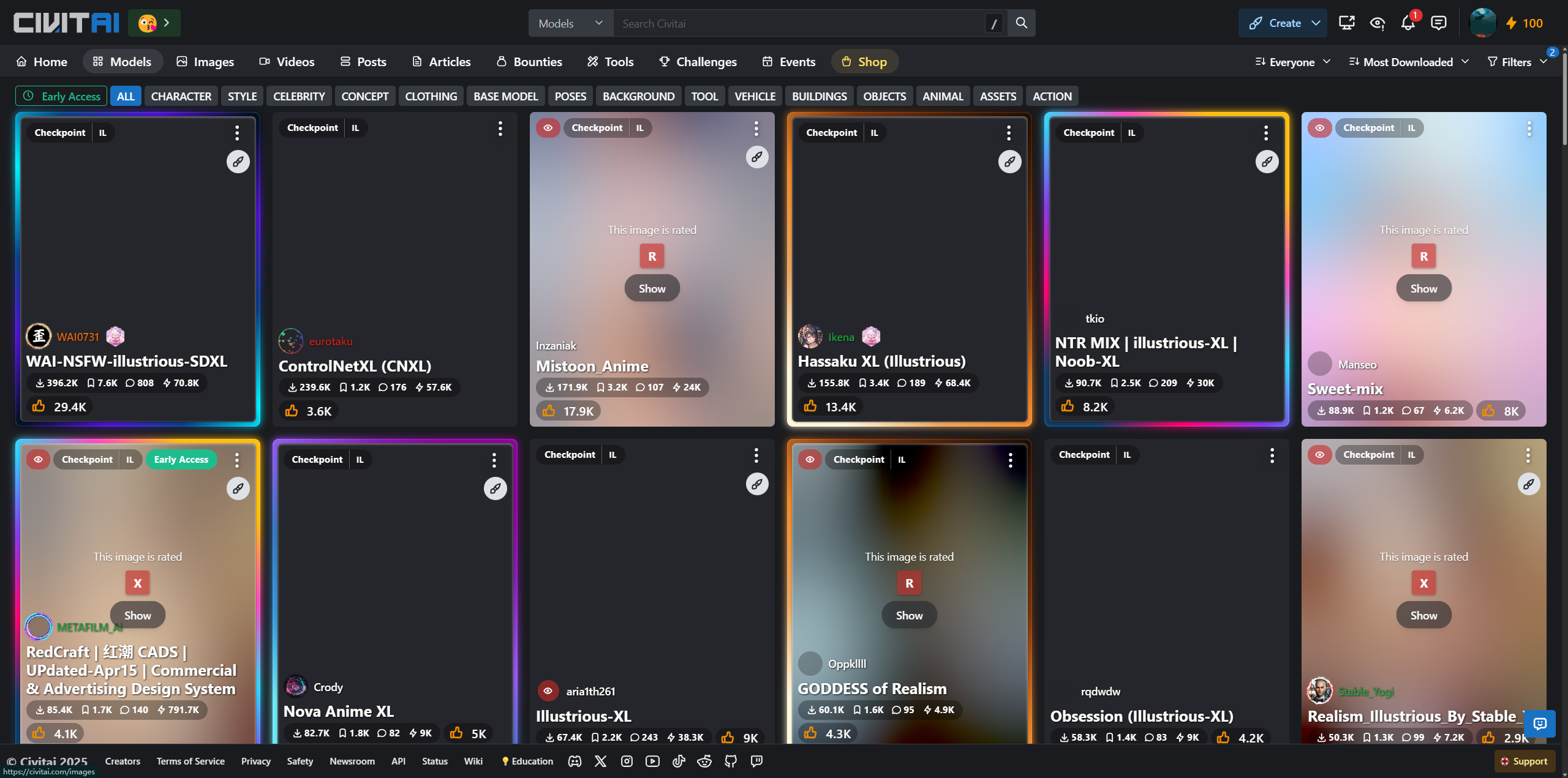
(3).模型分类有很多,导航栏下方提供了种类/类型分类,有所有、角色、风格等,大家根据自己的需求有选择下载即可
(4).在每个模型展示窗口我们可以看到类似【checkpoint|il】的文字说明
这里单独简单介绍下:
checkpoint,在Stable Diffusion的基础模型(如Stable Diffusion v1.5、v2.0、XL等)上进行微调(fine-tuning)后得到的模型。此外,【ckpt】并不是指一个具体的文件或文件夹名,而是指在训练过程中保存的【模型状态】。它通常会包含模型的权重、训练进度等信息。对于ckpt而言,为了提高其训练或推理性能,我们通常可以采取“微调”来实现。这就导致在C站中即便两个模型都是ckpt,但可能也会有些许差异。如:ckpt-lighting、ckpt-merge等。简单来说,我们可以尝试将ckpt理解为“存档”,它记录了模型在某个阶段、某个时刻下的状态,但它绝对不会是游戏本身!
对于ckpt模型而言,现在C站主流提供的文件格式为【.safetensors】。safetensors,是Huggingface 推出的一种可靠、易移植的机器学习模型存储格式,用于安全地存储Tensor,而且存储速度较快(零拷贝),对于其详细介绍,可以自行参阅HuggingFace文档:【https://huggingface.co/docs/safetensors/index】。
除了ckpt以外,还有一个叫做【Lora】的单次可能会被经常提及到。Lora(即,Low-Rank Adaptation of LargeLanguage Models,大语言模型低阶适应)什么意思呢?很抽象。需要我们结合上ckpt来综合理解。让我们再回到ckpt上,ckpt前面介绍过,它是某个基础模型的基础上得到的模型在某个阶段、步骤、时刻时的状态。那么其本质上还是一种模型,准确来说是一种深度学习模型。以较为基础且常见的一种深度学习模型——CNN(卷积神经网络)为例,其通常会包含:输入层——>卷积层——>激活函数——>池化层——>全连接层——>输出层。好像更难理解了?
输入层:很好理解,训练模型,首先需要解决将数据输入模型的问题,在此层级我们可以将数据输入到模型,模型可以接收数据。
卷积层:说卷积很抽象,但其本质上就是【加权叠加】。加权叠加仍然不好理解。在这里举个简单例子,假设我们现在接到一个任务:让我们预测商品A的在下个月的销量。再假设,商品A的销量变化符合线性上升。那么就是线性方程(这里不要将讨论复杂化,不要去纠结x和y之间到底是正比例关系还是反比例关系等):y=kx+b(未知数x和y;斜率k以及偏移量/截距b)。结合上CNN的层级,又可以得知,x是输入数据;y是输出数据。具体到该简单案例,x就是商品A的历史数据,y就是需要我们去预测的商品A的下个月的销量。此时,如果我们想要手动求解y,就必须算出k和b。而k和b可以通过商品A的历史数据计算得出。但如果我们手算求解,那么就不具备通用性、智能性,因为一旦当预测的商品不是A,变成了商品B,那么k和b也会变化,我们又得重新根据商品B的历史数据算出k与b。所以可以类似的线性预测问题抽象成一个模型,这个模型专门用来求解y=kx+b方程(具体是先根据输入的历史数据计算出k和b后,再去预测y)。所以此时的模型的一个关键任务就是去根据输入数据/历史数据求解k与b。
那么这个简单的模型就可以简画为如下图所示意的样子(这里不要去先入为主的代入已有的CNN架构去理解,而是假设自己刚刚学习CNN时如何一步一步地去了解它、认识它。当然,每个人的接受程度都有不同,作者提供的理解思路也并非通用。):
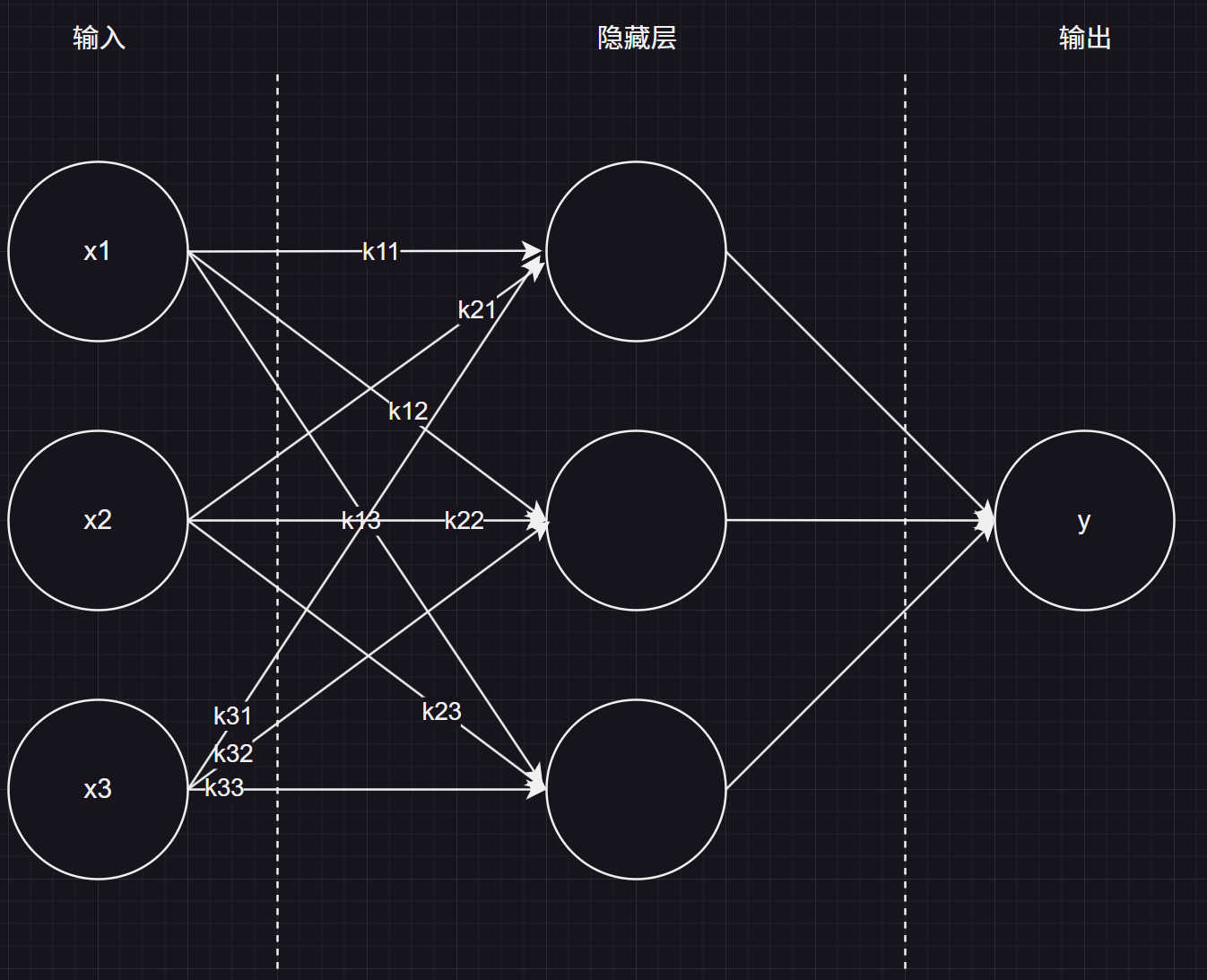
当然,实际情况可能更加复杂,虽然每个输入数据都符合y=kx+b,但是每个输入数据之间是否需要考虑权重问题呢?实际上是需要的,因为实际场景中,我们无法保证数据完全贴合y=kx+b。可能输入数据/历史数据1在这条直线的上面一点点,输入数据/历史数据2在这条直线的下面一点点,输入数据/历史数据3刚好在这条直线上。也就是说,它们对应的k很可能不是完全一致的。类似的还有b。
围绕此例子,隐藏层就是卷积。该层(卷积层)实现了对输入数据的加权操作,但是此案例过于简单,无法很好体现出叠加的作用。
上面的举例使用的是商品的销量数据为例进行阐述的,但是实际上,我们输入的数据可能是图片。那么图片如何输入呢?这里就不过多探讨了,简单来说,可以将图片抽象为像素点,每个点都有各自负责记录的色彩/信息,最终组合成一张完整图片。那么只要想办法将图片抽象为数据即可。我们可以使用RGB值来表示,(red,green,blue)每个颜色都可以用0~255范围内的数值来表示。这里我们就不探讨加上“灰度”概念的RGB值了。示意图如下:
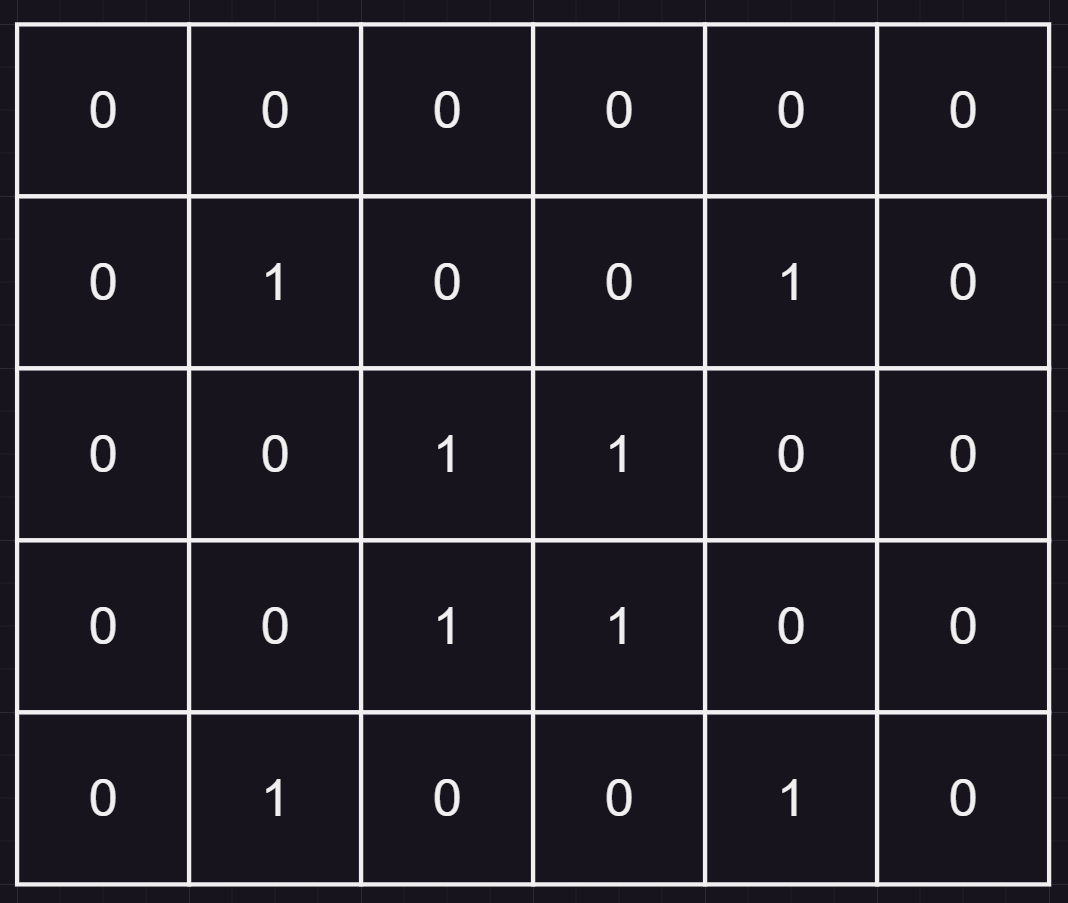
如果我们将这样一种【5x6】的矩阵(注意,上图示意的仅仅只是一个像素点或一块图像区域的数据)作为输入,输入给CNN,那么计算量就非常大了,效率也会很慢。所以就得想办法去“降维”了。如何去降维?假设有一个【2x2】的矩阵,如下图所示:
我们拿着这个【2x2】的矩阵去和【5x6】的矩阵相乘(注意:每次只取这个【5x6】矩阵中的【2x2】部分的数据来乘)。
在这个案例中,这个【2x2】的矩阵,就是卷积。此时,卷积起到了“降维”的作用。
所以上面提到了“说卷积很抽象,但其本质上就是【加权叠加】。”中的“叠加”其实就是“降维”的意思。当然从目的上看,为什么要去降维呢?我们可以这样去理解:在上述案例【2x2】和【5x6】矩阵去相乘时,其实每次都只会从【5x6】大矩阵中找一个【2x2】的小矩阵相乘。这个过程类似于“聚焦”,目的是“提取(图像)特征”。
池化层:略,简单来说就是在取区域平均或最大。也可以说是在“降维”(请一定注意,文中的降维,更多的表达的是一种矩阵大小的降低)。那如果说是降维,是不是和卷积重合了?并不是这样的,如果说卷积是降维为了“提取特征”;那么池化就仅仅只是在降维。这样不仅减少了维度,还在此基础上尽地保留了特征。
全连接层:略,简单来说就是Flat,或者说是平铺。将多维最终铺平成一维。
在上面的表述中,请大家无需过多纠结“提取特征”和“降维”,通过如上表述,其实可以较为明显的发现:“好像降维和提取特征相差不大”。这一点很好理解,降低了维度,就可以让我们聚焦,聚焦本身就比较类似于特征提取。反过来,如果我们要提取图片的特征,大概率就需要我们去聚焦、去降维。除非面试或其他专业场景需要,日常学习、理解其实不必深入到咬文嚼字的境地。
在此过程中,案例中的模型都是极其简化的,是为了方便理解的,但是整体而言,核心原理不会出现太大变化。而在实际工程项目中,模型的复杂度远超于此,模型的中的参数不计其数,尤其是Transformer架构的大语言模型!如果模型初始参数最终的训练效果不符合预期,往往都需要去通过调参的方式实现效果的提升。对于案例中简化模型而言,调参的难度并不大,但是实际项目中,参数多,调参的工作量也比较大:需要确定调整哪些参数,要如何调整等。虽然并不是每一个参数都需要单独调整,但仍然会比较麻烦以及吃经验和理解。
到了这里可能有人已经忘记了我们其实是要讲Lora模型的,只不过为了更好的方便没基础的朋友理解,所以前置引入了CNN相关概念。
虽然Lora并非传统意义上的深度学习框架所开发出的模型(它是基于Transformer的),但仍旧可以续接上文对于CNN的描述去讨论和理解。本文并不会去介绍Transformer,所以就让我们假设Lora是一种基于CNN的模型。对于一个训练出来以供进行图生文的模型(这里就叫模型A,假设它也是CNN且用于生成人物),它有N多层级(卷积层、池化层、激活函数、全连接层等)我们需要对该模型进行微调(微调的目的希望它能够实现生成亚洲人种的人物),那么有一个粗暴的方式就是对模型A所有层级中所有可微调的参数进行全量微调。这种方案完全可行,但是往往成本太高、太麻烦。那么有没有一种相对简单、成本更低的方式来微调呢?那就是局部微调(局部微调的方式也有很多,如:freeze)
假设在模型A的N多层级中,有一个层级用来单独提取脸部特征的,相对于我们的目的而言(希望模型经过微调能够实现生成亚洲人种的人物),其实我只需要保证脸部特征能够呈现出亚洲脸孔的特征即可。那对于其他层级(比如层级A关注服饰,层级B关注发型等)其实我并不需要特别关注。
Lora正是类似原理的一种微调模型,你甚至可以将其理解为复杂大系统中的一个小插件,仅仅关注某一个较为细分的功能调优。
通过上面的表述其实不难可以得出Lora的一些特点:
①.它必须依赖于某一个大模型存在
②.它更多的是赋予这个底层大模型某个特殊buff/增益/技能/专精
(5).右上角位置有【Filters】选项
通过该选项我们可以筛选想要展示出的模型,如下图所示:
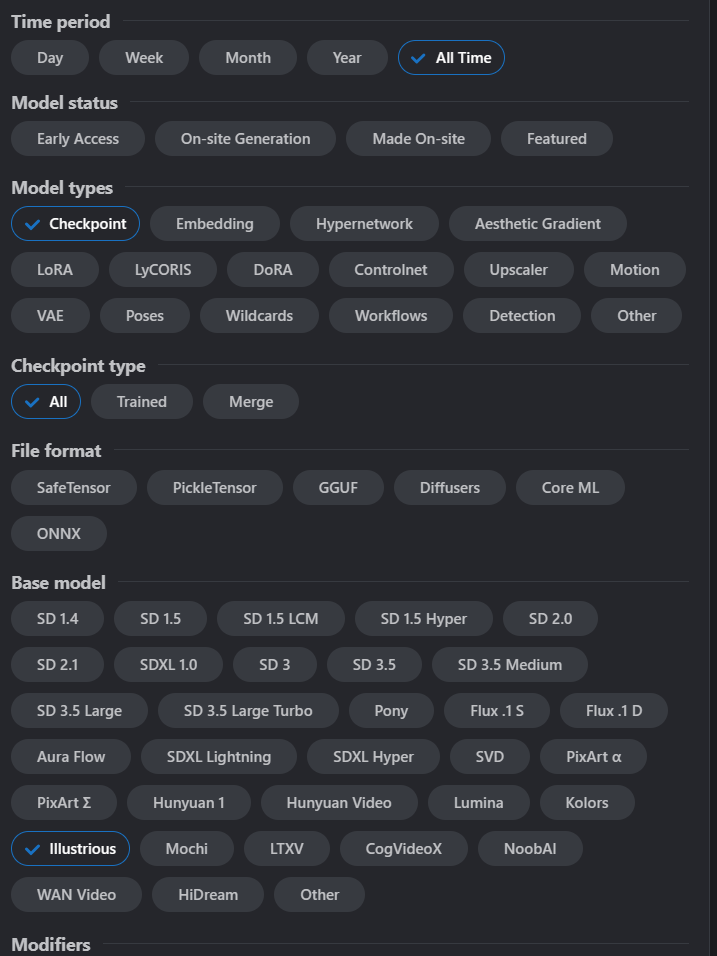
其中我们可以看到,Checkpoint属于【models types】,这恰巧应证了之前提到过的:“ckpt并非一种具体模型文件”。并且可以看到还有一个叫做【Base model】的选项。前面我们提到过,ckpt是需要基于某个“基础/底座模型”微调、操作后得到的,那么在【Base model】选项中也提供了多种基础模型以供选择。较为通用的、推荐的是【SDXL】模型。
要注意的是,如果你ckpt全都下载的是SDXL的,那么如果你想要使用Lora,也得和ckpt类型保持一致,都得是SDXL的。否则可能会出现Bug。
2.2 下载自己需要的模型
2.3 将下载好的模型复制到WSL-Debian挂载到Windows的目录
该目录较为常用必要时可以记忆【/home/用户名/】
注意,上传文件完成后通常会在本地生成对应的验证文件,可以手动删除
命令:
rm -rf *.Identifier
2.4 将ckpt以及lora模型移动至comfyui项目对应的目录下即可
命令:
mv /home/leo/lora/*.safetensors /projects/ComfyUI/models/loras/
mv /home/leo/checkpoints/*.safetensors /projects/ComfyUI/models/checkpoints/
通过如上命令即可得知,对于ComfyUI项目所需的模型需要放置到/path/to/your/ComfyUIProjectPath/models/目录下,至于到底放置到models的哪个目录下,需要根据模型类型来确定,这里暂时只涉及到【ckpt】以及【lora】(且是.safetensors格式)模型。暂时记住这两种模型的对应目录即可。
2.5 启动ComfyUI
启动前记得先切换到comfyui虚拟环境!
命令:
conda activate comfyui
python main.py

启动后根据打印输出到控制台的日志访问ComfyUI-WEBUI界面。

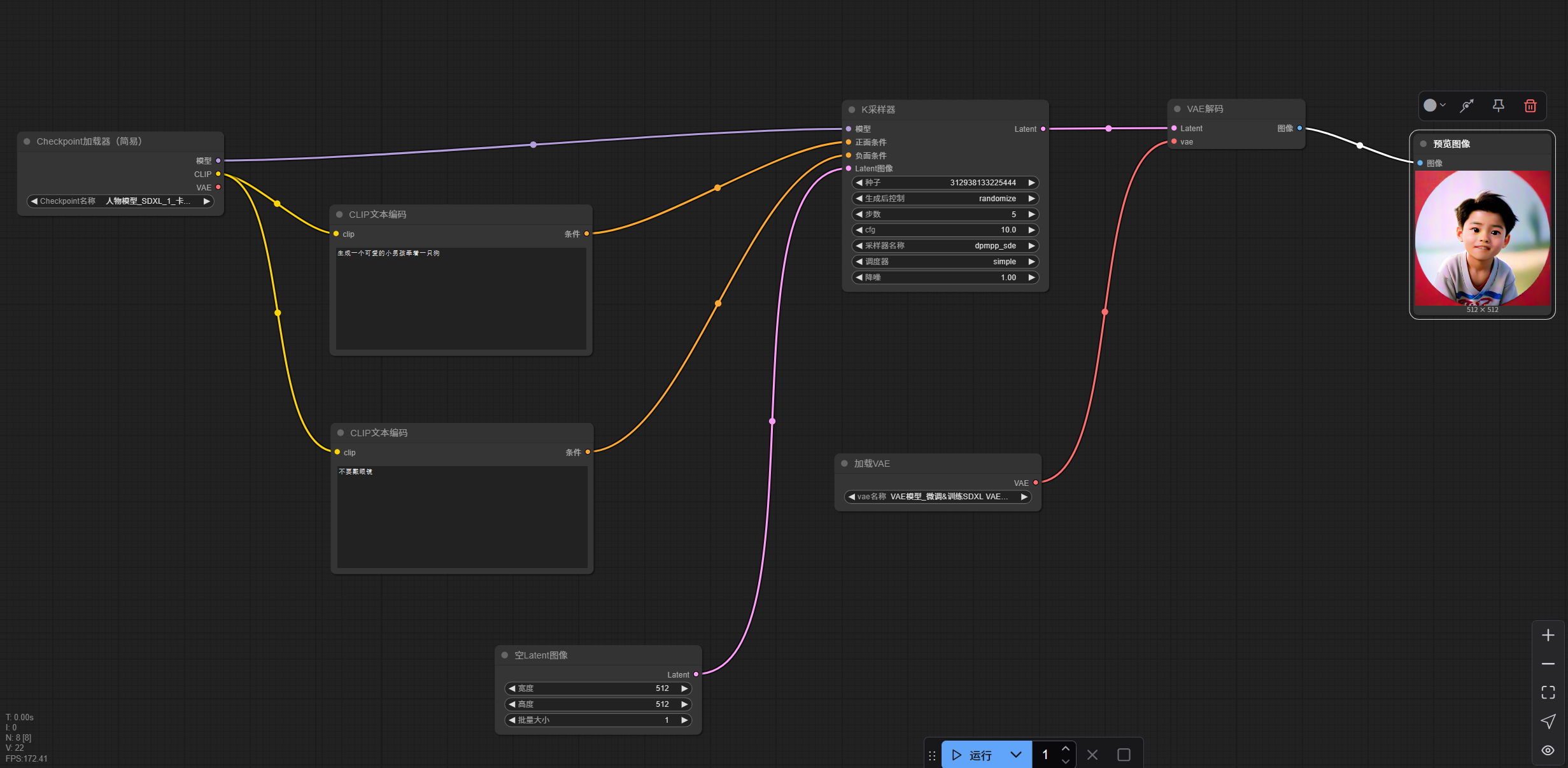
三、入门案例之☞简单图生文-CKPT模型的使用
3.1 在操作台空白处右键——>添加节点——>加载器——>ckpt加载器
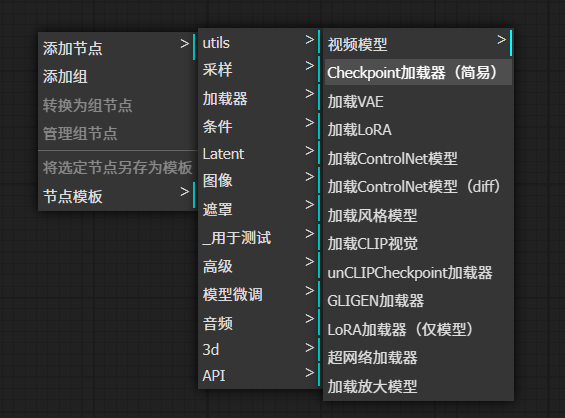
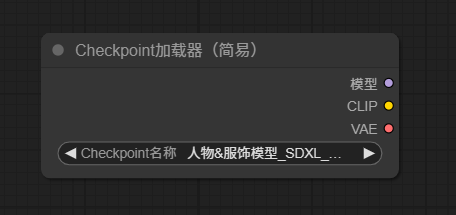
点击ckpt名称的位置即可选择提前下载好的ckpt模型了,根据自己需要去选择即可。这里我就选择“3D可爱人物”模型

模型:可以连接至其他模型,如lora模型,从而进行特定优化。
clip:可以简单看成是提示词,可以连接至clip节点,从而指定提示词
3.2 再右键——>添加节点——>采样——>K采样器
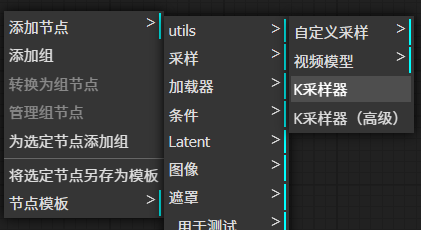
创建k采样器节点
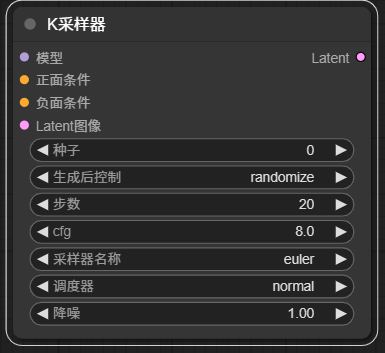
3.3 将ckpt加载器节点的模型连接至K采样器节点的模型
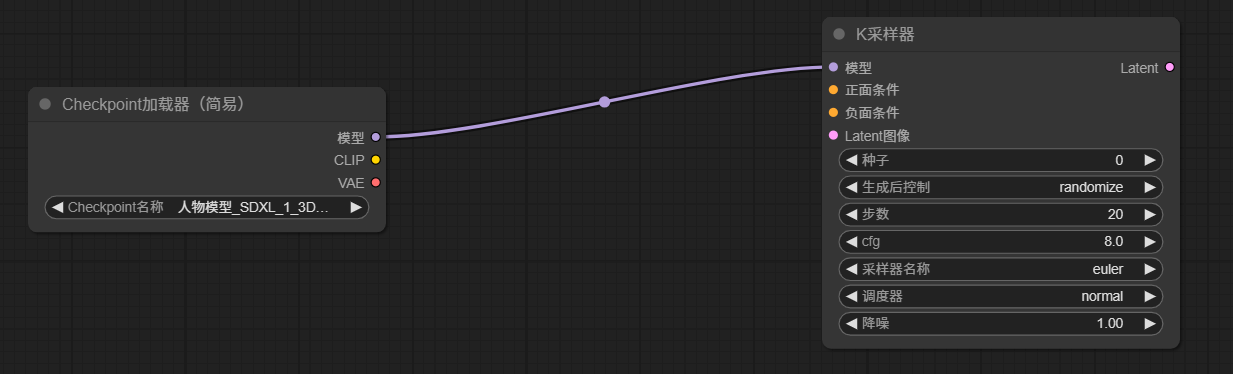
3.4 K采样器有两个条件,正面和负面,这里的条件可以简单视为提示词
可以引出两个clipencode节点,并将clip节点右侧条件连接至正面条件与负面条件,左侧连接至ckpt节点的clip,如下图所示:
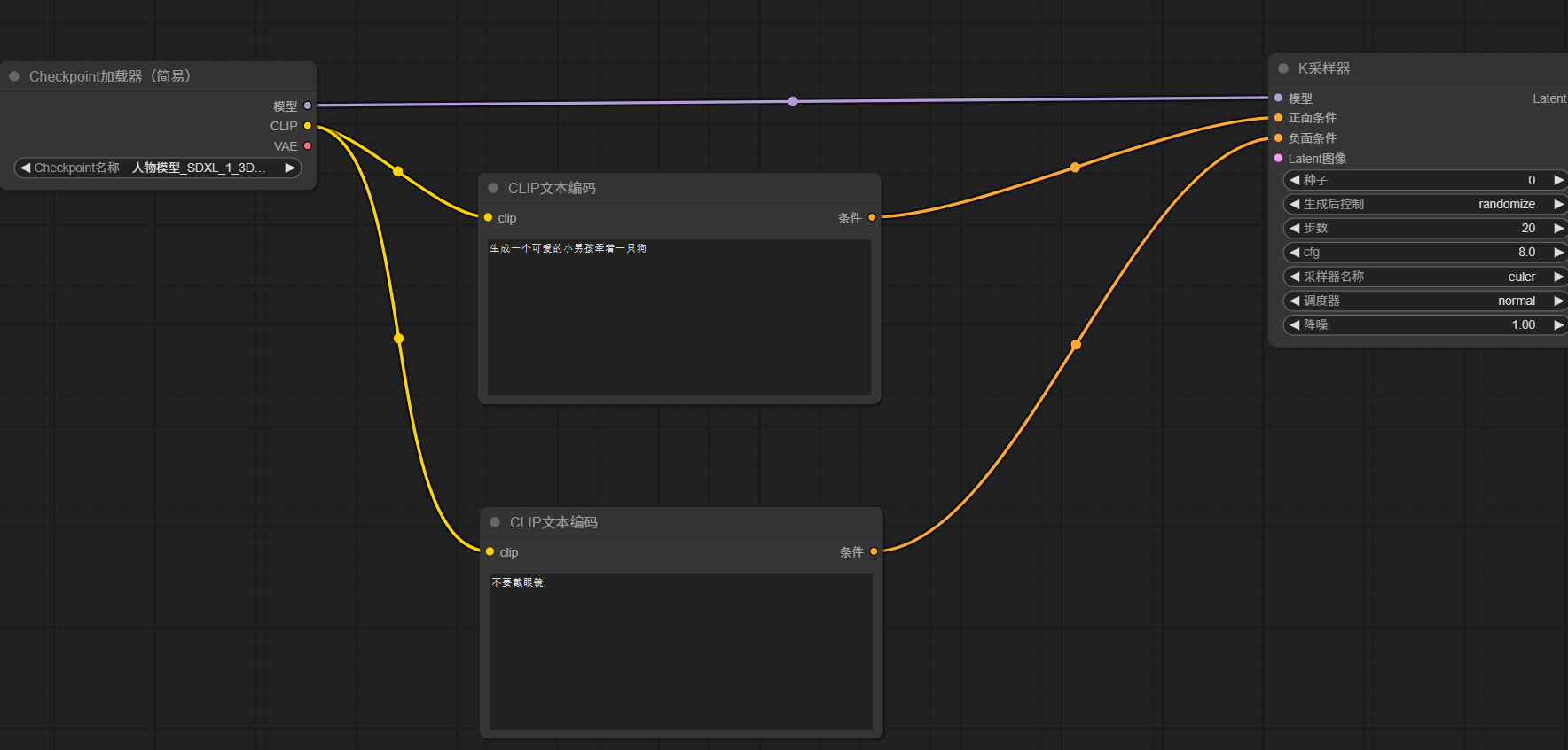
可以自行在clip节点中添加提示词,建议使用英文。当然,实际上使用中文提示词还是英文提示词还是需要根据模型来确定。
并引出Latent图像节点
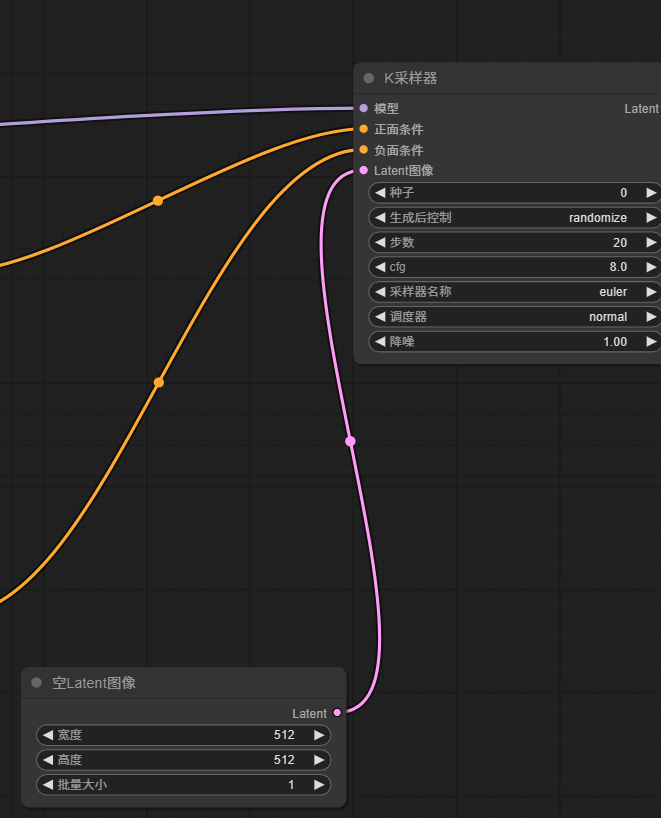
3.5 从k采样器节点左侧Latent引出VAE解码节点,再在VAE解码节点左侧图像引出预览图象节点(或保存图像节点)
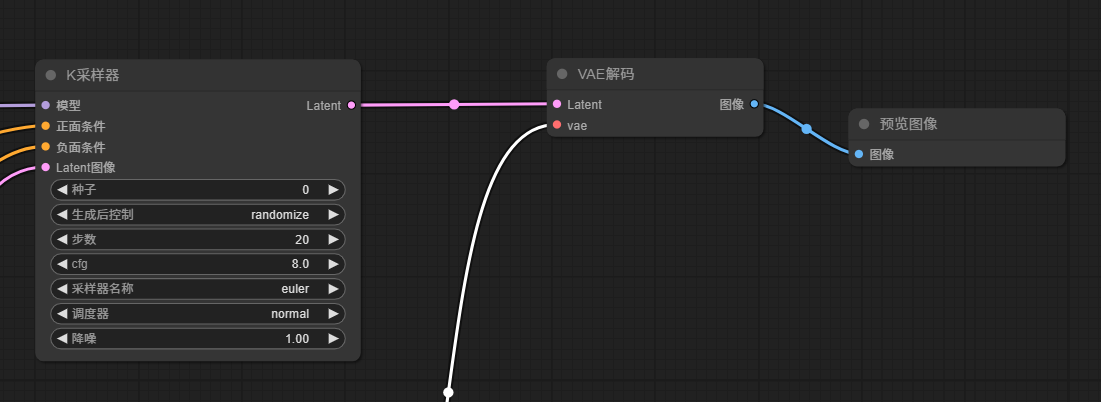
3.6 在VAE解码节点右侧vae引出vae加载器节点
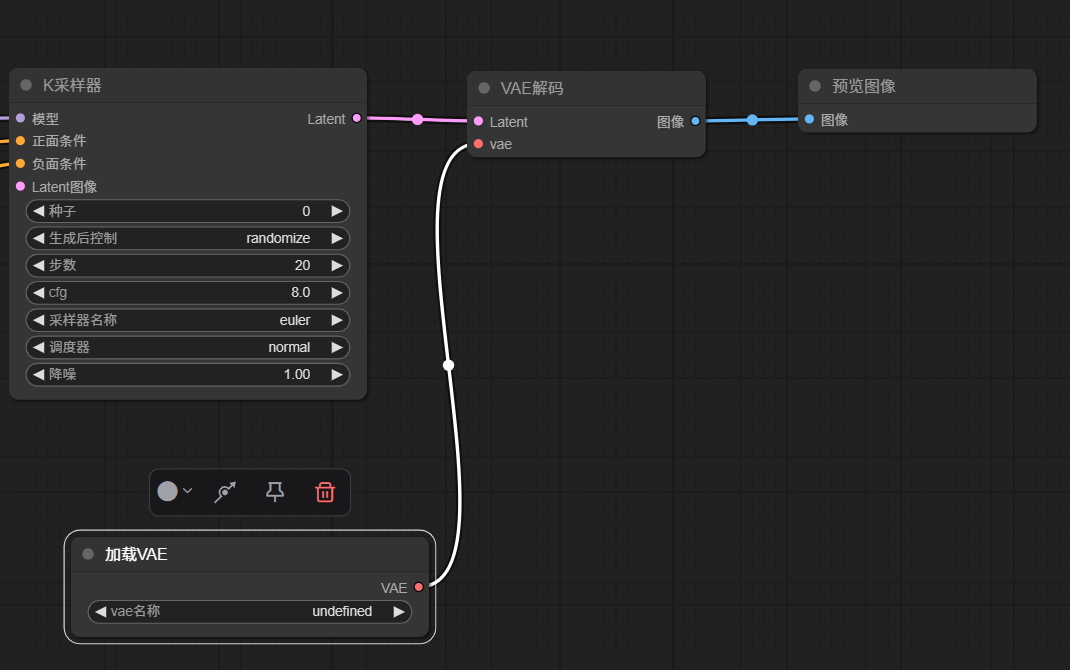
3.7 再尝试自行下载一个合适的VAE模型以供自己使用。
增加新的模型后记得重启ComfyUI程序!
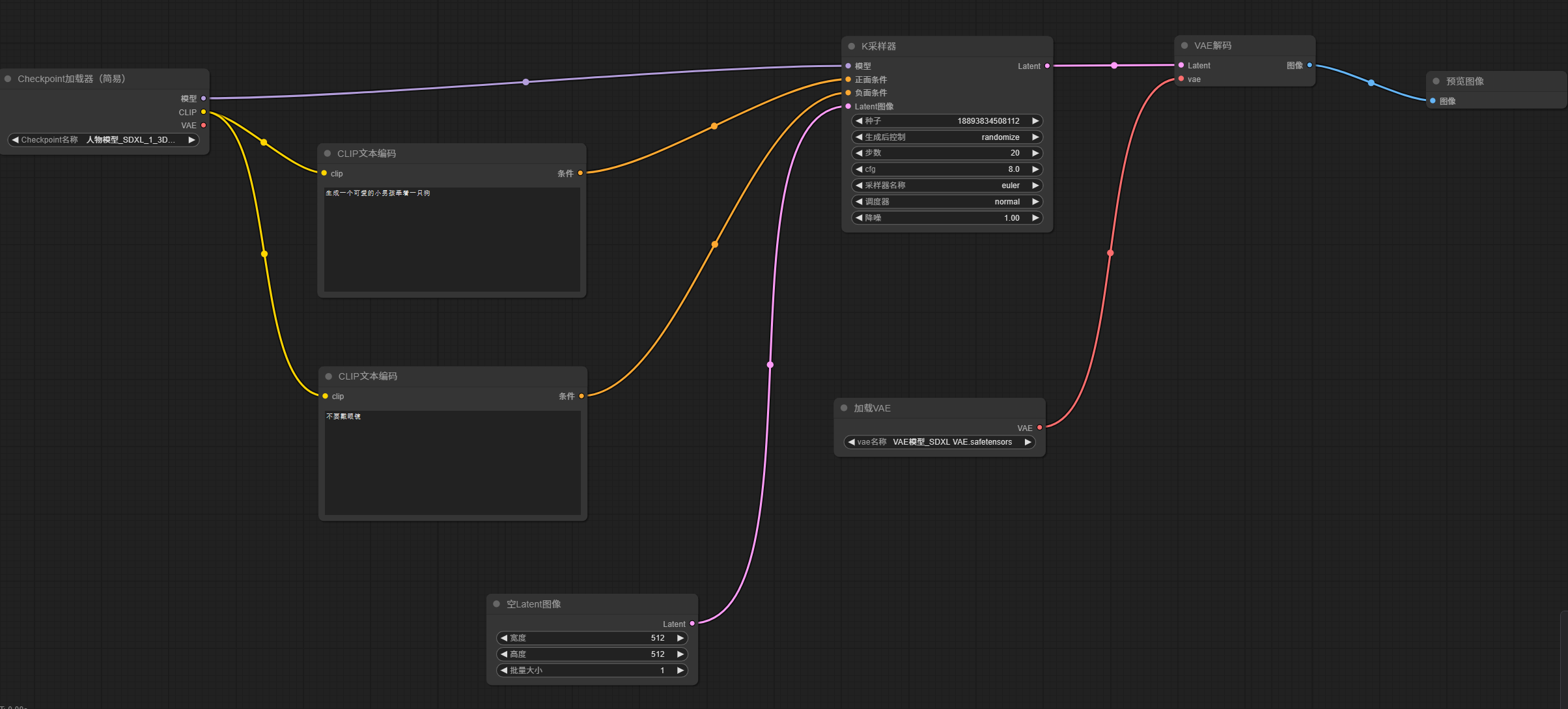
选择好VAE模型后,整体工作流如下图所示:
3.8 尝试点击运行工作流以生成图像

运行后观察预览图是否符合预期来决定是否进行调参
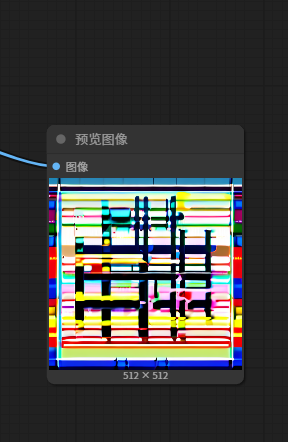
明显的,这里的图片预期效果很差,就需要进行调参,主要需要调整K采样器,也可以尝试更换ckpt模型或VAE模型。具体调整过程暂略,最终调整如下图所示。

















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









