







Word2Vec
- Embedding(嵌入)
- 数学上的一种映射(向量化)
- 特征的另一种表示,低维稠密向量表示一个对象(词,物品,图节点)
- Embedding将高维稀疏向量转换成低维稠密向量,在低维的条件下,向量表示的泛化性更强了,包含的隐含信息更多,比如BF两个字母的缩写既可以表示Boy Friend又可以表示Best Friend,此外由于低维向量的参数更少,所以存储低维向量或者使用其进行相似性计算速度都更快
Word2Vec:两个训练方案+两个提速手段
Word2Vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包
- 参考资料
- https://blog.csdn.net/itplus/article/details/37969979
- https://zhuanlan.zhihu.com/p/158004718
一、Word2Vec两个训练方案
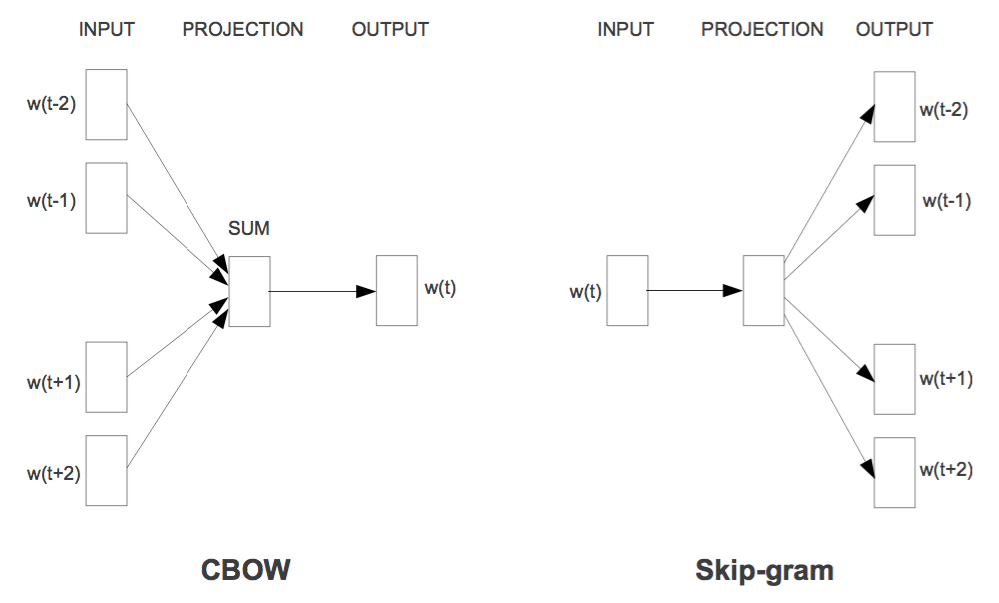
1.1CBOW
-
CBOW知道词的上下文情况下预测当前词
-
CBOW网络结构分为三层,分别是输入层、投影层和输出层
-
Hierarchical Softmax是Word2Vec中用于提高性能的一项关键技术,输出层是一个Huffman树,本质是把多分类问题转换为多次的二分类问题
1.2Skip-Gram
-
Skip-Gram:知道词的情况下,对词的上下文进行预测
-
Skip-Gram网络结构分为三层,分别是输入层、投影层和输出层
- 输入层:只包含当前样本的中心词的词向量
- 投影层:本质是恒等投影
- 与CBOW模型一样,输出层也是一棵Huffman树
1.3基于负采样(Negative Sampling)的CBOW和Skip-Gram模型
-
提高训练速度改善所得词向量的质量,只有正样本收敛速度慢,且效果较差
-
与Hierarchical Softmax相比,NEG不再使用复杂的Huffman树,而是利用相对简单的随机负采样,大幅提高性能,可看做是Hierarchical Softmax的一种替代
-
要预测的词w是一个正样本,其他词是就是负样本
- 负采样的确定本质是一个带权采样的问题
- 词典D中的词在语料c中出现的次数有高有低,对于那些高频词,被选为负样本的概率比较大,对于那些低频词,其被选中的概率就比较小
- 优化目标变为增大正样本的概率同时降低负样本的概率
二、Word2Vec使用方式
- 有监督学习获取数据的Embedding
- https://blog.csdn.net/leitouguan8655/article/details/108534694
2.1预训练的词向量模型
- Gensim 提供了一些预训练的词向量模型,如 Google News Word2Vec 或 GloVe 等。这些模型是在大规模语料库上训练得到的,并且已经包含了丰富的语义信息。可以直接加载这些预训练的模型,并使用其中的词向量进行各种任务,而不需要重新训练模型。
# from gensim.models import KeyedVectors
# # 加载预训练好的Google News Word2Vec 模型
# model = KeyedVectors.load_word2vec_format('path/to/GoogleNews-vectors-negative300.bin', binary=True)
# # 打印指定词对应的词向量
# vector = model['和谐']
# # 打印词向量
# print(vector)
2.2自定义训练
- 根据自己的文本语料库训练自定义的 Word2Vec 模型。这通常用于针对特定任务或特定领域的文本数据进行词向量训练。在这种情况下,需要提供自己的文本语料库,并使用 Gensim 中的 Word2Vec 对其进行训练。这样,模型将学习到与自定义语料库相关的语义信息和上下文关系。
from gensim.models import Word2Vec
sentences = [["I", "love", "python"], ["I", "am", "learning", "NLP"], ["Word2Vec", "is", "powerful"]]
# 创建 Word2Vec 模型并训练
model = Word2Vec(sentences, min_count=1)
# 获取单词的词向量
vector = model.wv['python']
print(vector)
# 寻找与给定词最相似的词语
similar_words = model.wv.most_similar('python')
print(similar_words)
[ 4.6100351e-03 -2.6877164e-03 -4.6958611e-03 3.0468244e-04
-2.7079065e-03 -1.8303745e-04 4.3957890e-03 -1.8013853e-03
6.6447037e-04 -4.8731295e-03 -1.7679805e-03 -3.9050835e-03
-3.7450008e-03 -4.7681653e-03 -1.3188801e-03 -2.8200704e-03
-1.6427526e-03 -3.9925352e-03 -4.3981811e-03 5.5540196e-04
1.5218572e-04 -4.0903022e-03 2.1552474e-03 4.4050869e-03
8.3954335e-04 -4.0551890e-03 3.9640376e-03 -4.5576650e-03
-4.2956937e-03 -2.4739124e-03 -3.2197270e-03 -4.6744193e-03
1.7741695e-03 -2.4243158e-03 1.6728792e-03 4.2315321e-03
-4.8412262e-03 -1.3971498e-04 3.0005523e-03 -1.4921250e-03
4.4700297e-04 4.6475958e-03 3.8773920e-03 -2.7271598e-03
4.2089075e-03 3.4843548e-03 4.9385000e-03 -2.1269456e-03
2.2038878e-03 1.4139626e-03 4.5646038e-03 -1.8024573e-03
2.6856943e-03 -1.5719072e-03 3.4778723e-03 -4.2683319e-03
2.1306232e-04 1.3741445e-03 8.1011205e-04 1.2764095e-03
-2.3312110e-03 1.3274167e-03 2.2324563e-03 -5.9850997e-04
2.5543785e-03 4.7245948e-03 -3.4602673e-04 -3.9076181e-03
4.0990142e-03 -1.1029245e-03 4.2209355e-03 6.0706900e-04
-9.7411656e-05 -6.6820701e-04 -4.4655050e-03 -3.1912755e-03
-1.8369574e-03 3.5525854e-03 4.7852140e-04 -2.4729066e-03
-4.8386790e-03 4.3674237e-03 -4.8090742e-04 4.9325749e-03
-5.9049763e-04 8.3033164e-04 4.3395674e-03 2.9358899e-03
-7.6214067e-04 2.1011308e-03 1.5566606e-03 2.6018803e-03
-2.5030728e-03 2.2383672e-03 -3.8490396e-03 3.0125759e-03
-2.0404253e-03 3.5302280e-03 -4.7193137e-03 -2.3887493e-03]
[('love', 0.17537280917167664), ('I', 0.022930819541215897), ('NLP', 0.010224614292383194), ('learning', -0.009643614292144775), ('Word2Vec', -0.010928258299827576), ('powerful', -0.053783513605594635), ('am', -0.06325794756412506), ('is', -0.0781039372086525)]
2.3Word2Vec模型参数
- size:指定生成的词向量的维度的大小,较大的值通常需要更大的训练数据来获得更好的效果
- window:指定当前词与目标词之间的最大距离(以词的个数计算),窗口大小确定了当前词周围的上下文词汇,用于训练词向量。默认值为5。
- min_count:设定词汇表中词语的最低频次阈值。频次低于这个阈值的词语将被忽略,默认值为5。
- sg:指定训练算法的类型,取值0表示使用CBOW,取值为1表示使用Skip-Gram算法,默认为0。
- hs:指定训练室是否使用层次化Softmax,取值为0表示负采样,取值为1表示层次化Softmax,默认为0。
- negative:指定负采样数量,用于设置为负样本的数量,默认为5-20之间的值。
- iter:指定训练过程中的迭代次数,默认为5,指定了在整个训练数据上进行多少次迭代,每一次迭代模型会更新词向量的权重,以更好的捕捉单词的语义信息,迭代次数的选择在一定程度上取决于数据集的规模和任务的复杂性。通常情况下,迭代次数越多,模型能够更好地学习到数据中的潜在模式和语义信息,但也可能导致过拟合(overfitting)的情况。
- workers:指定使用的线程数来训练模型,加快训练速度,通常将其设置为CPU核心数。
2.4停止词
- 在Word2Vec模型中,停止词(Stop Words)是指在文本处理任务中被认为对结果没有实际意义、常见且频繁出现的单词。这些单词通常是语言中的功能词(如冠词、代词、介词)或者常见的连接词(如“and”、“the”、“in”等),它们在句子中的出现频率很高,但对于理解文本的语义并不具有很大的贡献。
# 使用remove_stopwords方法去除停止词
from gensim.parsing.preprocessing import remove_stopwords
# Example sentence
sentence = "This is an example sentence with some stop words."
# Remove stop words
filtered_sentence = remove_stopwords(sentence)
print(filtered_sentence)
This example sentence stop words.
remove_stopwords方法用于去除停止词。该方法默认会去除以下英文停止词
STOPWORDS = frozenset([
'ourselves', 'hers', 'between', 'yourself', 'but', 'again', 'there', 'about', 'once', 'during', 'out', 'very',
'having', 'with', 'they', 'own', 'an', 'be', 'some', 'for', 'do', 'its', 'yours', 'such', 'into', 'of', 'most',
'itself', 'other', 'off', 'is', 's', 'am', 'or', 'who', 'as', 'from', 'him', 'each', 'the', 'themselves',
'until', 'below', 'are', 'we', 'these', 'your', 'his', 'through', 'don', 'nor', 'me', 'were', 'her', 'more',
'himself', 'this', 'down', 'should', 'our', 'their', 'while', 'above', 'both', 'up', 'to', 'ours', 'had', 'she',
'all', 'no', 'when', 'at', 'any', 'before', 'them', 'same', 'and', 'been', 'have', 'in', 'will', 'on', 'does',
'yourselves', 'then', 'that', 'because', 'what', 'over', 'why', 'so', 'can', 'did', 'not', 'now', 'under', 'he',
'you', 'herself', 'has', 'just', 'where', 'too', 'only', 'myself', 'which', 'those', 'i', 'after', 'few', 'whom',
't', 'being', 'if', 'theirs', 'my', 'against', 'a', 'by', 'doing', 'it', 'how', 'further', 'was', 'here', 'than'
])
remove_stopwords仅支持去除英文停止词,若要去除其他语言的停止词可以使用
from nltk.corpus import stopwords
import nltk
from nltk.corpus import stopwords
import jieba
# 下载中文停用词表
nltk.download('stopwords')
# 加载中文停用词表
stop_words = set(stopwords.words('chinese'))
# 示例文本
text = "我喜欢用Python进行自然语言处理。"
# 使用jieba分词
tokens = jieba.cut(text)
# 去除停用词
filtered_tokens = [token for token in tokens if token not in stop_words]
# 打印结果
print(filtered_tokens)
[nltk_data] Downloading package stopwords to /home/mw/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.839 seconds.
Prefix dict has been built succesfully.
['喜欢', 'Python', '自然语言', '。']















 3332
3332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









