






首个深度学习web应用,基于Flask和Keras
缘起
随着疫情缓解,在家自学TF、看看论文然后混吃喝的happy日子被迫结束T T。前往一家互联网公司的web开发组实习。期间,接触到了很多之前完全不了解的方方面面,促使我从程序员职业的角度开始思考自己的未来,这部分另有博客分析。这里主要介绍我利用摸鱼时间把学到的web开发内容和机器学习结合起来,完成的我的第一个web应用!
功能隐约眼熟?
核心功能:对上传的猫狗图片进行分类,并给出分类概率。没错 _, 挺鸡肋的。就算上传人类的图片也会强行分类成猫或者狗,只是概率会接近50%。
如果看了后面的界面和功能,眼尖的人一定会发现,没错,本应用在结构上参考了塞巴斯蒂安的Python Machine Learning第九章。主要区别有:
- 我使用的keras预训练模型进行fine tuning,书中使用的scikit;
- 我使用图片上传,返回图片分类和分类概率,书中是电影评论的情感分析;
- 我使用了多线程来降低更新模型的等待时间;
- 我没有使用SQL数据库,而是在文件夹中保存图片。
为什么使用Flask和keras?
使用keras是因为其提供了预训练的MobileNet权重,非常适合拿来迁移学习做fine tunning。这样在CPU上做推理的时候,假设中的用户不会等的想砸电脑。不过我也没有实际去探究哪些预训练的模型做推理效率高。
其实,python进行web开发实在是小众,实习中后端还是用的Java+Spring MVC,前端用的js+VUE。但是Flask作为轻量级的后端框架,最大的好处就是python的后端代码和keras的模型训练等语法可以无缝衔接。并且小白一个人开发整个应用,并不会JS,所以flask的模板引擎jinja2提供了很简易(但丑)的前端,只需掌握基本的html语法就能写出前端。
功能和界面
参考Python Machine Learning第九章,用户使用的流程是
光秃秃的选择文件表单和上传按钮0.0
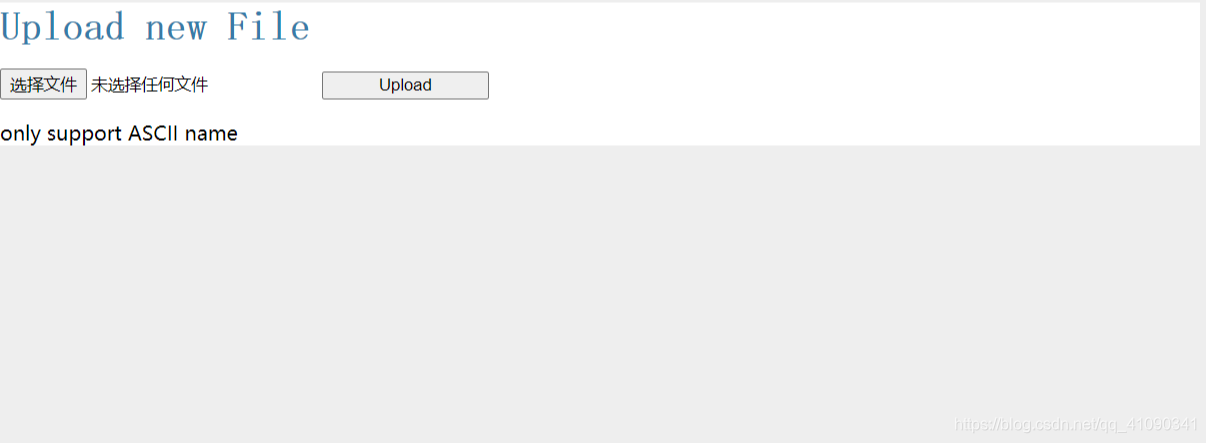
因为后面代码中secure_filename()的存在,这里偷懒,只支持英文命名的JPG和PNG格式图片,后缀不区分大小写。如果上传中文,会显示“only support ASCII name”。

这一步
- 图片上传至
./uploads保存; - 从
./uploads取出图片放入./static/images,并用保存的MobileNet权重对图片进行推理; - 前端显示上传图片、分类和分类概率;
用户可以根据自己的判断选择应用分类的正确或者错误,用于给图片打标签,后续扩充训练集,更新模型权重。

- 点击确认后,如果存在同名文件会提示"File already exists or has the same name";
- 否则根据用户选择的
Correct或Incorrect将新图片移入./static/image/Cat或者./static/image/Dog。相当于将确认图片打上标签,扩充训练集,用于更新模型权重。 - 模型权重更新需要重新训练,耗时较长,故使用子线程后台运行,先返回前端,再完成更新。
Note: 上文中的相对路径都是相对于app.py的。
项目结构和代码
目录结构
│ app.py
│ repredict.py 加载权重用于预测
│ TryMobile.py 更新权重
├─static
│ │ cats_dog_mobileNet.h5 用于预测的权重
│ │ files_cat.npy
│ │ files_dog.npy 保存新增标签图片path的numpy数组
│ │ style.css 从flask教程白嫖来的样式表
│ └─images
│ │ 存放用户未提供反馈,没打标签的图片
│ ├─Cat
│ │ 存放标签为猫的图片
│ └─Dog
├─templates
│ show.html
│ thanks.html
│ upload.html
└─uploads 保存所有上传图片
代码
请见我的github仓库 MobileNet_Flask_Web_Application 欢迎各位大佬来star、提issue,共同学习~
以下只列出开发过程中遇到的难点。
上传图片并显示
不懂js,好在Flask的模板引擎jinja2提供了向html文件动态传入变量的途径。
def render_photo_as_page(filename):
"""
调用repredict.py的函数对上传图片进行预测
每次调用都将上传的图片复制到static中"""
img = Image.open(os.path.join(UPLOAD_FOLDER, filename)) #上传文件夹和static分离
img.save(os.path.join('./static/images', filename))
#predict
preds = repredict(filename)
result = {}
result["prediction"] = preds[0]
result["probability"] = preds[1]
result["fileName"] = filename
return result
@app.route('/upload/<path:fileName>', methods=['POST', 'GET'])
def update(fileName):
"""输入url加载图片,并返回预测值;上传图片,也会重定向到这里"""
result = render_photo_as_page(fileName)
return render_template('show.html', fname='images/'+fileName, result=result)
#向前端传入图片路径和预测结果
前端
<div>
<h1>上传图片</h1>
<img src="{{ url_for('static', filename = fname) }}" />
<p>对上传照片的分类为:{{result["prediction"]}}</p>
<p>分类概率为:{{result["probability"]}}</p>
</div>
此处filename = fname即前端传入的图片路径,result即预测值的字典。
Fine-tunning
使用Keras自带的Mobilenet在ImageNet上训练的.h5文件,去掉其分类器部分:最后的GAP层和Softmax层,替换为两层FC分类器
x = Dense(1024, activation='relu')(x)
#添加类别分类器,只有两类
classifier = Dense(1, activation='sigmoid')(x)
最后一层的激活函数使用sigmoid,用于二分类(原来是1000类)。使用2000张猫和狗的图片作为训练集,1000张做验证集,在CPU上用了约20分钟5轮将验证集精度达到90%以上。
- 8月10日更新
原来结构用的GAP改成FC层没有必要,增加了很多参数,但是练手项目懒得重新训练了
自定义生成器更新权重
想要使用./static/image/Cat_or_Dog文件夹中用户打过标签的图片用于更新模型权重,但又要避免重复训练。第一想法是每次对目录下的文件名set和上一次的set求差集,剩下的就是新增的。当新增数量大于一个batch,就开启训练。
这里其实有flow_from_frame这个新增的方法使用,将所有新增文件写入pandas的csv文件,但是我的老版keras没有这个方法。所以考虑自定义一个生成器。
def read_img(path, target_size):
'''读取单张图片,返回channel_first的4d数组'''
try:
img = Image.open(path).convert("RGB")
img_rs = img.resize(target_size)
except Exception as e:
print(e)
else:
x = np.expand_dims(np.array(img_rs), axis=0) #0指定channel在前
return x
def img_gen(NewImgSet, batch_size, target_size):
"""NewImgSet是元组分别存new_Cat路径和new_Dog路径
cat label is 0
dog label is 1
"""
length = NewImgSet.shape[1]
steps = math.ceil(length/batch_size) #确定每轮多少个batch,向上取整
print(length, steps)
while True:
for i in range(steps):
print(i)
batch_list = NewImgSet[0][i*batch_size: (i+1)*batch_size] #这里真的不会上溢?
label_list = NewImgSet[1][i*batch_size: (i+1)*batch_size]
img = [read_img(path, target_size) for path in batch_list]
#print(img)
batch_img = np.concatenate([array for array in img]) #?
yield batch_img, label_list
def update():
"""新增文件更新训练"""
# 必须要外部.npy文件存储上一次的所有标签图片
old_files_cat = set(np.load('./static/files_cat.npy'))
old_files_dog = set(np.load('./static/files_dog.npy'))
#print(old_files_cat)
path_cat = './static/images/Cat/'
path_dog = './static/images/Dog/'
files_cat = np.array([path_cat+file
for file in os.listdir(path_cat)]) #给每个file加上路径
files_dog = np.array([path_dog+file
for file in os.listdir(path_dog)])
np.save('./static/files_cat.npy', files_cat)
np.save('./static/files_dog.npy', files_dog)
#每次新图片上传都没有编号,其实应该编号啊.......
new_cat = list(set(files_cat) - old_files_cat)
#print(set(files_cat) - old_files_cat)
new_dog = list(set(files_dog) - old_files_dog)
NSet = new_cat + new_dog
label_cat = np.zeros(len(new_cat))
label_dog = np.ones(len(new_dog))
labels = np.concatenate((label_cat, label_dog)) #only one axis
ImgSet = np.array([NSet, labels])
# 可以用flow_from_dataframe代替,传入path,但需要安装新的tf2.0
# 原训练集猫狗各1000张,validation猫狗各500张
update_gen = img_gen(ImgSet, BATCH_SIZE, TARGET_SIZE)
#重新加载模型,设置分类器为可训练
with CustomObjectScope({'relu6': relu6,'DepthwiseConv2D': DepthwiseConv2D}):
model = load_model("./static/cats_dog_mobileNet.h5")
#先冻结所有层,再将倒数两层解冻
for layer in model.layers:
layer.trainable = False
model.layers[-1].trainable = True
model.layers[-2].trainable = True
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
model.fit_generator(update_gen, steps_per_epoch=5, epochs=5)
#steps_per_epochs决定每轮生成器生成多少次,samples/batch_sizes
model.save('./static/cats_dog_mobileNet_ver1.h5')
#这里最好加入版本号,但是那样前面repredict也要改
return
实验表明,预训练的网络功能过于强大,已经能在测试集上达到99%的精度,权重更新在这里显得没有太大实质意义。但是对于数据缺乏的任务,权重更新就会很有意义。
总结
整个项目的功能到实现都是我拍脑袋想的,而且我是零web开发基础,所以和实际应用肯定有很多不符之处,还要很多可以改进之处,这里略举几例:
- 用户恶意打标签可以让权重崩坏
- 最后的更新权重线程还是要结束之后才能重新用于预测
- 由用户打过标签的图片,应该给于编号
实习期间的收获有:
- 学习SQL基础,对数据库和后端的关系有了基本了解,不过在这个项目中并没有用上;
- 学习Flask框架,并用于开发博客、AI应用,实践了将keras模型嵌入到web应用中;
- 学习html基础,能根据手册大致读懂文件;
参考
- 自定义生成器 https://zhuanlan.zhihu.com/p/32679425
- 《Python Maschine Learning》 Chapter9
- 上传图片并显示 https://blog.csdn.net/dcrmg/article/details/81987808#comments_12912975















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









