






MACER: A Modular Framework for Accelerated Compilation Error Repair
基本信息
博客贡献人
页禾七
作者
Darshak Chhatbar, Umair Z. Ahmed,Purushottam Kar
摘要
- 自动编译错误修复,即对无法编译的错误程序提出修复建议的问题,近年来引起了人们的极大兴趣,其中自动代码修复对于那些认为编译器错误消息晦涩难懂的新手程序员来说具有重要的教学应用价值;
- 现有方法在很大程度上利用高强度生成式学习技术的黑盒应用来解决这个问题,例如序列到序列预测(TRACER)或强化学习(RLAssist),这类方法训练时间方面变得庞大,并且在针对特定错误类型时效率低下;
- 作者提出 MACER,该技术基于将修复过程模块化分离为修复识别和修复应用,使用强大但廉价的判别学习技术(例如多标签分类器和排名器)首先识别所需的修复类型,然后应用建议的修复;
- 通过实验表明MACER 采用的细粒度方法不仅提供了卓越的纠错能力,而且具有更快的训练和预测速度。MACER 在针对常见错误时提出与学生所需修复完全匹配的修复建议方面比现有方法高出 20%。 MACER 在所有错误类型上(包括常见和罕见的)都具有竞争力或优于现有方法。 MACER 的训练时间比 TRACER 快 2 倍,比 RLAssist 快 800 倍,而测试时间比两者都快 2-4 倍。
相关研究
- DeepFix:首次尝试使用深度学习技术(序列到序列模型)来定位和修复错误的模型;
- RLAssist:引入使用强化学习的自学习技术,以消除对训练数据的需求,但是该方法训练时间很慢;
- TRACER : 将整个修复流程分为修复行定位和修复预测两部分,该方法具有更好的修复性能。
本文贡献
- 相较于TRACER,DeepFix等之前依赖于高强度生成式学习技术,及将修复类别识别和应用两个操作一步执行(一步法)的方法,MACER建立了一个模块化处理流程:除了定位需要修复的代码行,还识别需要修复的代码行所需的维修类型(该代码行的修复类)以及该代码行中的何处进行维修,进一步隔离修复流程,最后应用该修复(该行的修复配置文件);
- 之前的方法采用生成机制,在训练和预测成本高,并且一步法使得微调以前的方法去更多地关注某些类型的错误变得具有挑战性,而MACER能够专门针对某些错误类型。具体来说,MACER 能够单独关注每个修复类别,以提供卓越的错误修复;
- MACER将大规模多类和多标签学习任务中使用的技术(例如层次分类和重排序技术)引入到程序修复问题中(首次应用);
- MACER能准确预测修复等级。因此教师可以结合 MACER 给出的修复建议为常见的修复类手动重写有用的反馈,从而提供更大的教学价值;
- 提出一种高效优化的端到端工具链,整个修复流程是端到端且完全自动化的,即修复类别的创建等步骤可以复制到任何可以进行静态类型推断的编程语言中;
- MACER不仅在各项指标优于现有技术,并且训练和预测时间也比现有技术快几个数量级。
问题设定和数据预处理
MACER根据多对程序形式的训练数据来学习错误修复策略,其中一个程序无法编译(称为源程序),而另一个程序没有编译错误(称为目标程序),同时仅对两个程序在一行中不同的那些对进行训练(但是MACER 能够对多行可能需要修复的程序进行修复,并且在实验中包含了此类数据集)。

源(或目标)程序中的不同行称为源行(或目标行)。对于每个这样的程序对,本文同时收集 Clang 编译器在编译源程序时生成的 errorID 和消息。下表列出了一些错误 ID(共148个) 和错误消息。从表数据可以看出,某些错误类型极少遇到,而其他错误类型则非常常见。

符号设定
使用尖括号表示n元语法。
例如,语句 a = b + c;包含一元词<a>、<=>、<b>、<+>、 和 <;>,以及包含二元词 <a =>、<= b>、<b +>、<+ c>, <c ;> 和 <;;EOL〉。在对二元组进行编码时,包含行尾字符 EOL有助于 MACER 区分该位置,因为多项修复(例如插入表达式终止符号)需要在行末尾进行编辑。
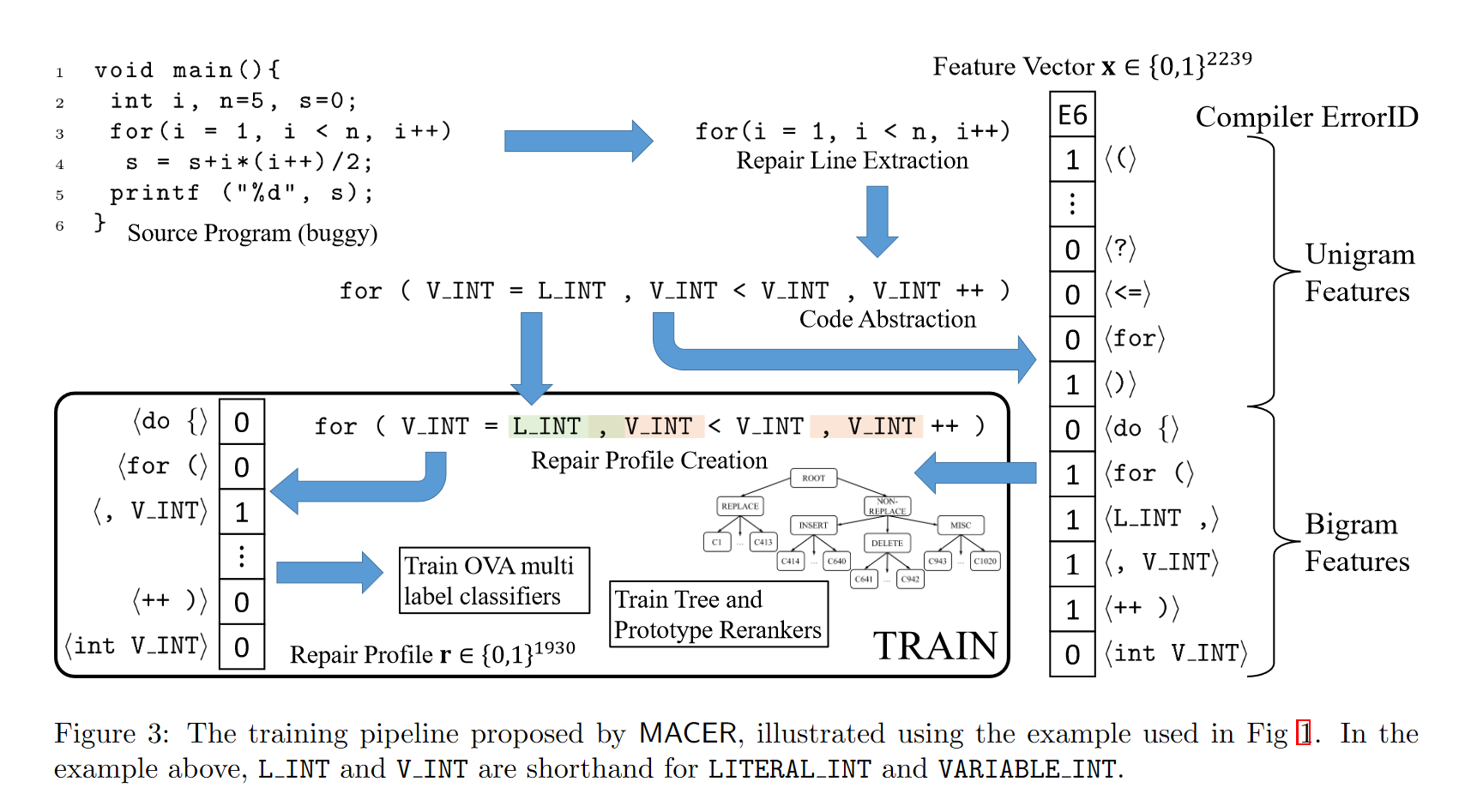
特征编码
将变量值和标识符替换为相应的抽象LLVM标记类型同时保留关键字和符号(字符串文字例外,并且格式说明符(例如 %d 和 %s)按原样保留,因为它们本身通常是错误来源),未声明/无法识别的标识符将替换为通用标记 INVALID。
例如,语句 int abc = 0;被转换为抽象语句 int VARIABLE INT = LITERAL INT ;
对于本文数据集,通过该过程一共产生了161 个一元组和 1930 个不相同二元组的词汇量。
MACER将每个源行表示为2239维二进制向量,其中前 148 个维度存储在该源代码行上生成的编译器 errorID 的 one-hot 编码,接下来的 161 个维度存储源行的 one-hot 一元特征编码,其余 1930 个维度存储抽象源行的 one-hot 二元特征编码。
修复类创建
源代码行的修复类对要应用于该行的修复进行编码。(这些修复类别是根据训练数据自动生成的)
-
类似于TEGCER,首先将 148 个编译器生成的 errorID 集合扩展为更大的1016个修复类集合。
对于同一个errerID,可能存在多种实例,例如, errorID E6 可以表示 for 循环标头内缺少分号;,也可以表示在 do-while 块的末尾缺少分号;或者在switch case 块中缺少冒号 :
修复类以元组的形式编码,其中包含该源代码行的编译器错误errerID,后跟必须删除的的标记的枚举(按照它们在源代码行中从左到右出现的顺序),最后是必须插入的标记的枚举(按照源行中从左到右的插入点顺序)。如下所示:
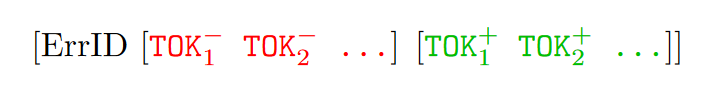
一共确定了 1016 个此类。其中不需要插入(或删除)的修复类称为删除(或插入)修复类,删除与插入次数一样多并且是在删除的位置插入的修复类称为替换修复类,下表说明了一些维修类别。

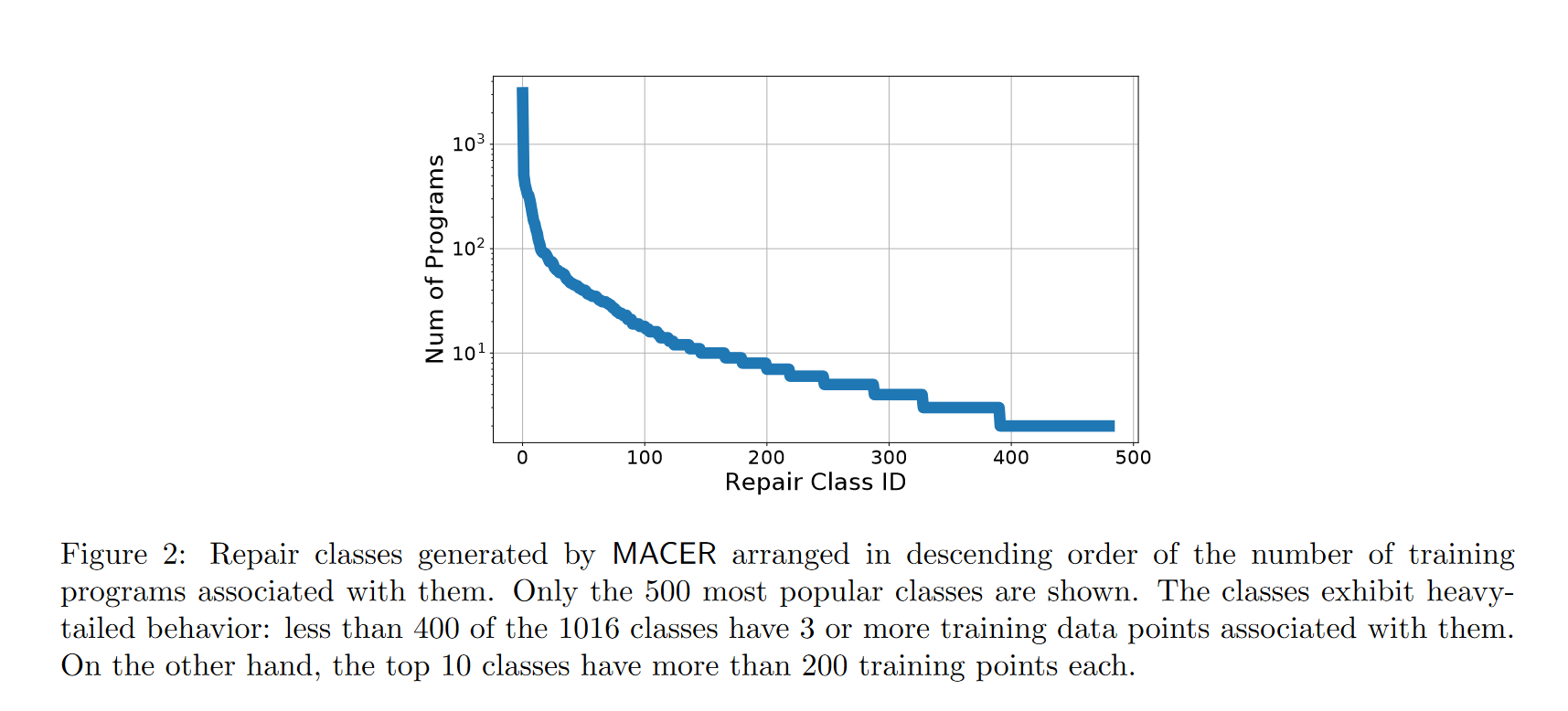
修复类表现出重尾(见下图),常见的类具有数百个训练点,而绝大多数(罕见)修复类仅具有个位数的训练实例。
修复配置文件创建
源代码行的修复配置文件对该行中的位置进行编码,以应用其修复类中编码的修复
训练对的修复配置文件存储这些需要对该源行进行修改的二元组的标识。这些二元组的集合的独热表示,即二进制向量 r ∈ { 0 , 1 } 1930 \mathbf{r}\in\left\{0,1\right\}^{1930} r∈{0,1}1930被视为该源行的修复配置文件。
工作数据集
经过特征编码,修复类创建,修复配置文件创建后,构成新的数据集 { ( x i , y i , r i ) } i = 1 n \left\{(\mathbf{x}^i,y^i,\mathbf{r}^i)\right\}_{i=1}^n {(xi,yi,ri)}i=1n。
对于训练数据集中的每一个源-模目标对i,包含:
- 类标签 y i ∈ [ 1016 ] y^i\in[1016] yi∈[1016]:展示该源代码行的修复类
- 特征表示 x i ∈ { 0 , 1 } 2239 \mathbf{x}^i\in\left\{0,1\right\}^{2239} xi∈{0,1}2239:展示errerID,源行的一元组和二元组表示
- 稀疏布尔向量 r i ∈ { 0 , 1 } 1930 \mathbf{r}^i\in\{0,1\}^{1930} ri∈{0,1}1930:展示修复配置
MACER方法
修复过程
- 修复行:在源代码中找到哪些行是错误的并且需要修复。
- 特征编码:对于找出来的错误行,进行代码抽象和特征编码,获得2239维的特征向量
- 修复类别预测:使用特征向量来预测1019个修复类别中哪一个适用
- 修复定位:使用特征向量来预测源行内应用修复的位置
- 修复应用:在预测位置应用预测的修复
- 修复具体化:撤销代码抽象并且编译
修复行
-
编码器报告遇到错误的行号不一定是需要修复的行号(只有80%符合)
-
现有方法采用不同技术来定位错误行:
-
RLAssist采用强化学习定位
-
DeepFix训练专用神经网络来标识可疑标记(及位置),实现约86%的定位精度
-
TRACER依赖编码器报告的错误行号并考虑该行的上下两行,获得87%的定位精度
-
-
MACER使用和TRACER相同的技术,在本文的训练数据集中获得约90%的定位召回率
修复类别预测
-
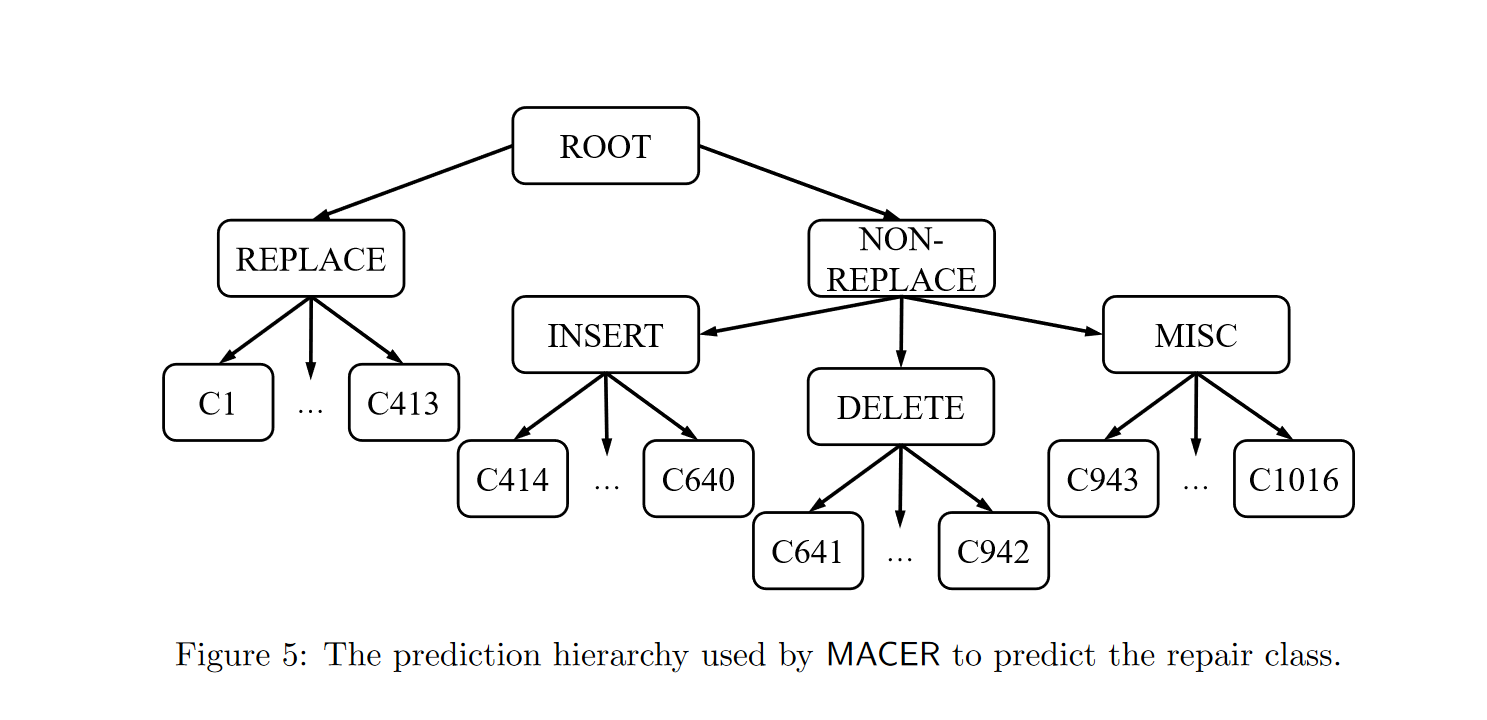
本文采用1016个修复类别,为了快速准确地预测适用于给定源代码行的正确修复类别,MACER 使用了大规模多类和多标签分类问题领域中流行的分层分类技术
-
由于我们的问题设置中存在自然的层次结构,本文使用固定的层次结构。鉴于修复类别的很大一部分(大约 40%)涉及替换修复,本文首先将需要替换修复的源代码行与其他代码行隔离开
-
MACER使用的分类层次结构如图5:
-
根节点通过一个前馈神经网络(具有2个隐藏层,每层128个节点,损失函数为交叉熵损失函数)决定源代码是替换修复类还是其他修复类
-
内部节点各自通过线性的一对多分类器(同样采用交叉熵损失函数)进行分类
线性的一对多分类器(Linear One-vs-Rest Classifier)是一种用于多分类问题的机器学习方法。它通过将多分类问题分解为多个二分类问题来实现分类。具体来说,对于一个有n个类别的多分类问题,线性的一对多分类器会训练n个二分类器,每个二分类器用于区分某一个类别与其他所有类别。
-
-
针对稀有修复类别提出改进措施,将分类树(classification tree)扩展为排名树(ranking tree),对类别进行排序,而不仅是预测一个类别,并且引入重新排序步骤(reranking step),修改排名树给出的排名
修复类别排名
-
将分类树转换为概率排名树,为每个修复类别分配似然分数
对于某一类别 c ∈ [ 1016 ] c\in[1016] c∈[1016],似然分数
s c t r e e ( x ) : = P [ y = c ∣ x ] = P [ V l c = 1 ∣ x ] = ∏ t ∈ W ( l c ) P [ V t = 1 ∣ x , V P ( t ) = 1 ] s_c^{\mathtt{tree}}(\mathbf{x}):=\mathbb{P}\left[y=c\mid\mathbf{x}\right]=\mathbb{P}\left[V_{l_c}=1\mid\mathbf{x}\right]=\prod_{t\in W(l_c)}\mathbb{P}\left[V_t=1\mid\mathbf{x},V_{P(t)}=1\right] sctree(x):=P[y=c∣x]=P[Vlc=1∣x]=t∈W(lc)∏P[Vt=1∣x,VP(t)=1]
其中x表示输入的给定特征向量,随机变量 V t V_t Vt 表示访问节点t的概率, W ( l c ) W(l_c) W(lc)表示从根节点到叶节点 l c l_c lc的路径上经过所有节点的集合
修复类别重排名
目的:提高罕见修复类别的分类性能
工具:原型分类器(prototype classifiers)
原理:K-means算法
对于输入的源代码行特征向量表示x,分别计算其与每种修复类别c的分数,其计算过程如下:
s
c
p
r
o
t
(
x
)
:
=
max
k
∈
[
k
c
]
exp
(
−
1
2
∥
x
−
x
~
c
k
∥
2
2
)
s_c^{\mathrm{prot}}(\mathbf{x}):=\max_{k\in[k_c]}\exp\left(-\frac12\left\|\mathbf{x}-\tilde{\mathbf{x}}_c^k\right\|_2^2\right)
scprot(x):=k∈[kc]maxexp(−21
x−x~ck
22)
其中
k
c
k_c
kc为修复类别c的簇,每个簇的质心为
x
~
c
1
,
…
,
x
~
c
k
c
\tilde{\mathbf{x}}_c^1,\ldots,\tilde{\mathbf{x}}_c^{k_c}
x~c1,…,x~ckc被视为该修复类别的原型
该公式表示对于每个修复类别c,找到该类别中最接近的原型 x ~ k c \tilde{x}_k^c x~kc,并使用这个原型来生成一个分数。
MACER同时使用概率排序树分配的分数和原型分类器分配的分数加权获得组合分数:
s
c
(
x
)
=
0.8
⋅
s
c
t
r
e
e
(
x
)
+
0.2
⋅
s
c
p
r
o
t
(
x
)
s_{c}(\mathbf{x})=0.8\cdot s_{c}^{\mathbf{tree}}(\mathbf{x})+0.2\cdot s_{c}^{\mathbf{prot}}(\mathbf{x})
sc(x)=0.8⋅sctree(x)+0.2⋅scprot(x)
其中权值0.8和0.2是基于经验和先前研究的结果
表3展示了重排名如何显著提高MACER准确预测编译器错误errorID和修复类别的能力
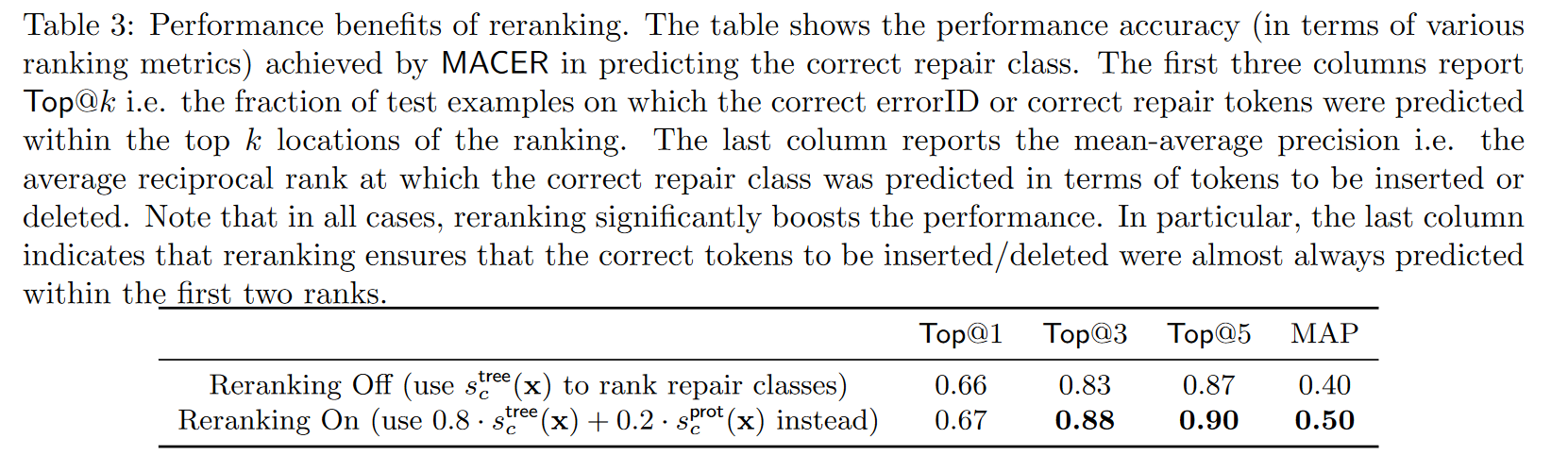
修复定位
预测出修复类别后,MACER需要继续定位源代码行中需要进行修复的区域,即源代码行中的哪些二元组需要进行编辑
本文将其转化为多标签学习问题:使用特征表示x和预测的修复类y作为输入,预测稀疏布尔修复配置向量r,如图所示。
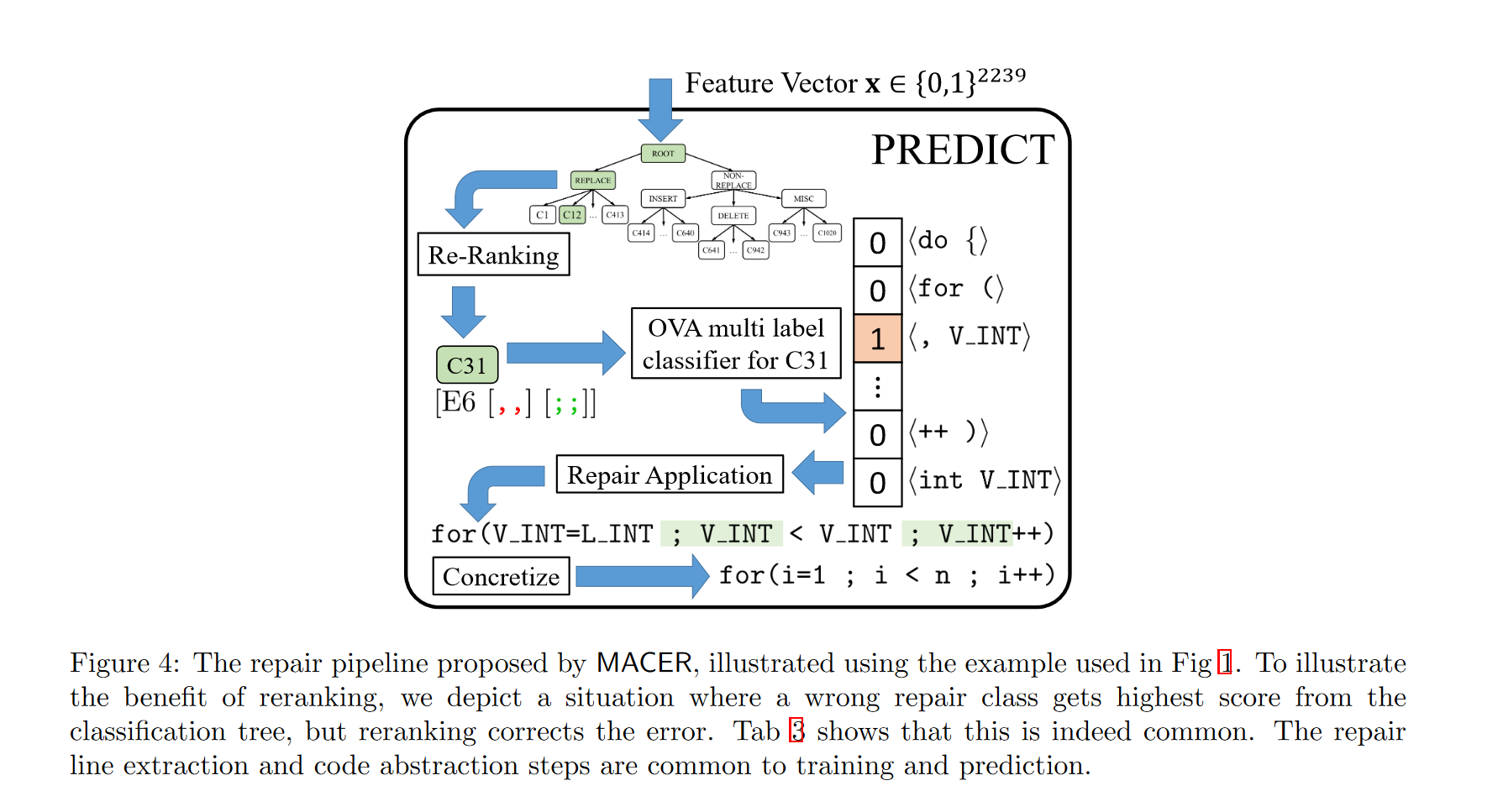
MACER采用one-vs-rest(OVR)方法
-
为每个修复类别单独训练一个OVR多标签分类器
-
训练1930个二元分类器,每个分类器预测该二元组是否需要被修复
OVR方法是将多标签分类问题转换为多个二分类问题。对于每一个类别,训练一个二分类器,用于区分该类别与其他所有类别。
修复应用
让 B \mathcal{B} B表示源代码行中所有需要被编辑的二元组(从左至右排序),针对不同修复类别采用不同的修复应用策略:
插入修复
在绝大多数情况下,需要插入的多个标记都插入在同一个位置
- 将所有需要插入的标记串联起来,形成一个插入集合
- 将这个插入集合尝试插入到集合
B
\mathcal{B}
B中的所有二元组里
- 对于每个二元组,尝试三次插入(二元组前面,中间,后面)
- 每次尝试插入后,具体化代码,尝试编译,如果编译成功则停止并认为修复成功,如果失败则尝试下一个插入位置或者二元组
删除修复
- 根据预测的修复类别,从右往左扫描,获得需要删除的标记列表
- 从右往左扫描
B
\mathcal{B}
B集合
- 对于每一个待删除的标记,找到第一个包含该标记的二元组并删除
- 从右往左扫描
B
\mathcal{B}
B集合
- 所有标记删除完后,将代码具体化并尝试编译
替换修复
假设该替换对为 (TOK−, TOK+),按照删除修复的步骤找到 B \mathcal{B} B中第一个包含TOK-的二元组,将其删除并在其位置插入TOK+,处理完后具体化代码并尝试编译
混合修复(杂项修复)
针对在代码中需要插入和删除不同数量的标记,并且编辑的位置也不一致(删除的位置不一定是插入的位置)的问题
- 首先忽略所有需要插入的标记,把它当成删除修复类型去处理
- 处理完后考虑插入标记,当作插入修复类型去处理
修复具体化
将抽象标记替换为具体的程序标记(逆向抽象的近似过程)
-
对于每个抽象标记,将其替换为同类型的最近使用的具体变量/变量值
如果修复建议插入一个特定类型的变量,但当前作用域中不存在该类型的变量,则无法替换
这种方法在数据集中能够成功替换90%以上的情况
方法总结
对于每个修复行定位器报告的候选修复行,MACER应用其预测的修复(包括具体化),然后尝试编译修复后的程序,如果编译错误数量减少,则接受该修复,并继续处理其他候选修复行。
实验
数据集
采用三个不同数据集,均来自 IIT-Kanpur 2015-2016 年秋季学期 CS-1 课程中400 多名学生尝试的40多项不同编程作业
评价指标
1)修复准确率 (repair-accuracy)
2)Pred@k
Pred@k是TRACER引入的指标,用来衡量测试程序中,前k个修复建议中至少有一个与学生自己的修复建议完全匹配的比例。
对比实验
表 4 和表 5 将 MACER 与其他方法进行比较
计算Pred@时,直接给出正确的修复行,因此不需要修复行定位
计算Rep@时,需要先定位错误行再修复

- 在单行测试数据集中(程序仅有一行需要修复),MACER和TRACETR性能相似
- 在多行测试数据集中,MACER相较于TRACER提高了14%的修复性能

- MACER 在DeepFix数据集上具有最高的修复精度,其次为TRACER
- 在测试时间和训练时间上MACER都显著优于其他方法
图6展示了MACER和TRACER在热门类别上的表现
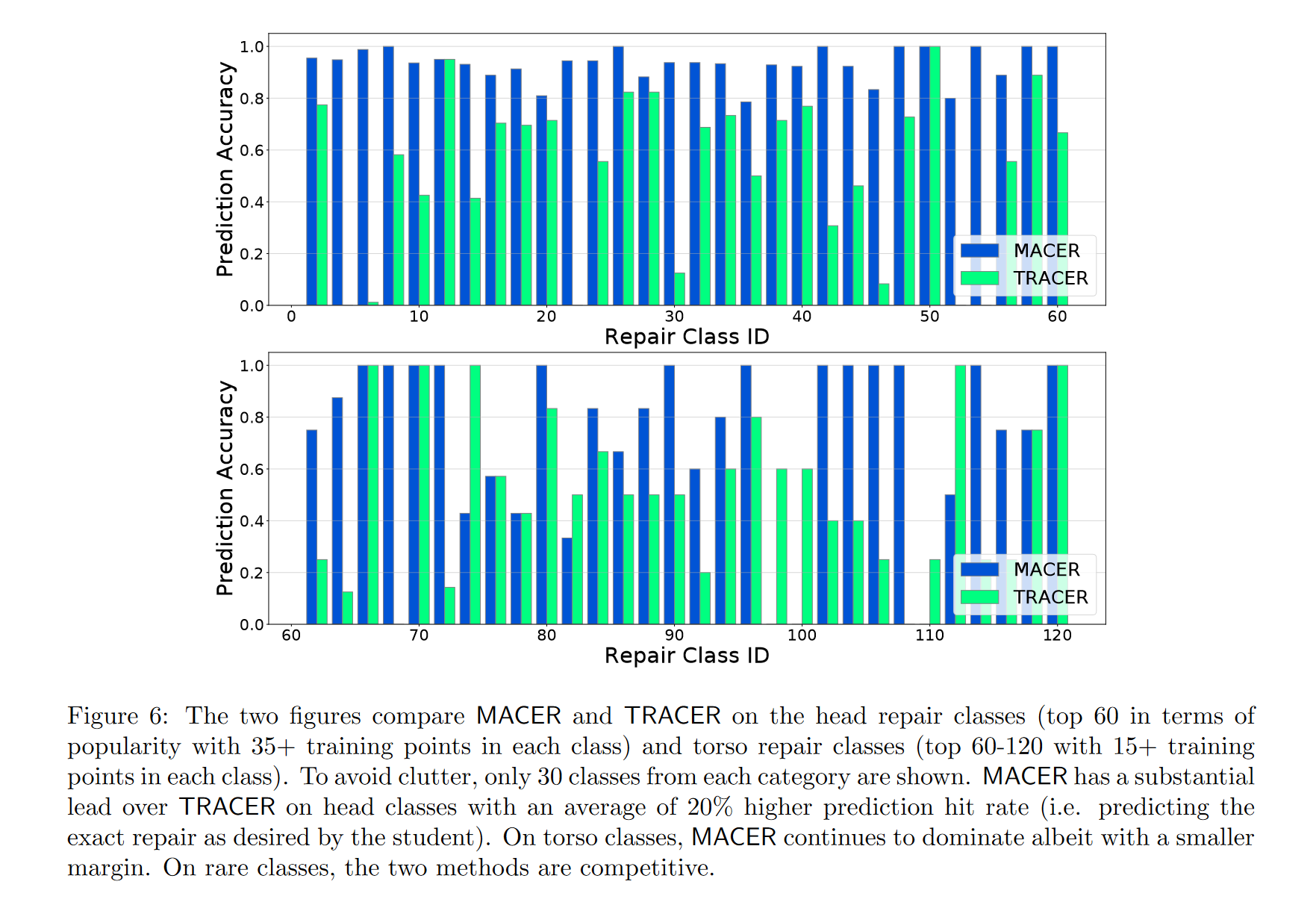
- 在头部修复类别(训练点个数大于35的前60个修复类别)上,MACER相较于TRACER具有明显优势,平均预测命中率高出20%
- 在躯干修复类别(训练点个数大于15的第60-120个修复类别)上,MACER依旧占主导地位,但优势相对较小
- 在稀有修复类别上,MACER和TRACER表现接近,竞争激烈
消融实验
图7展示对于前 120 个最受欢迎的修复类别,MACER的预测精确率和修复精确率
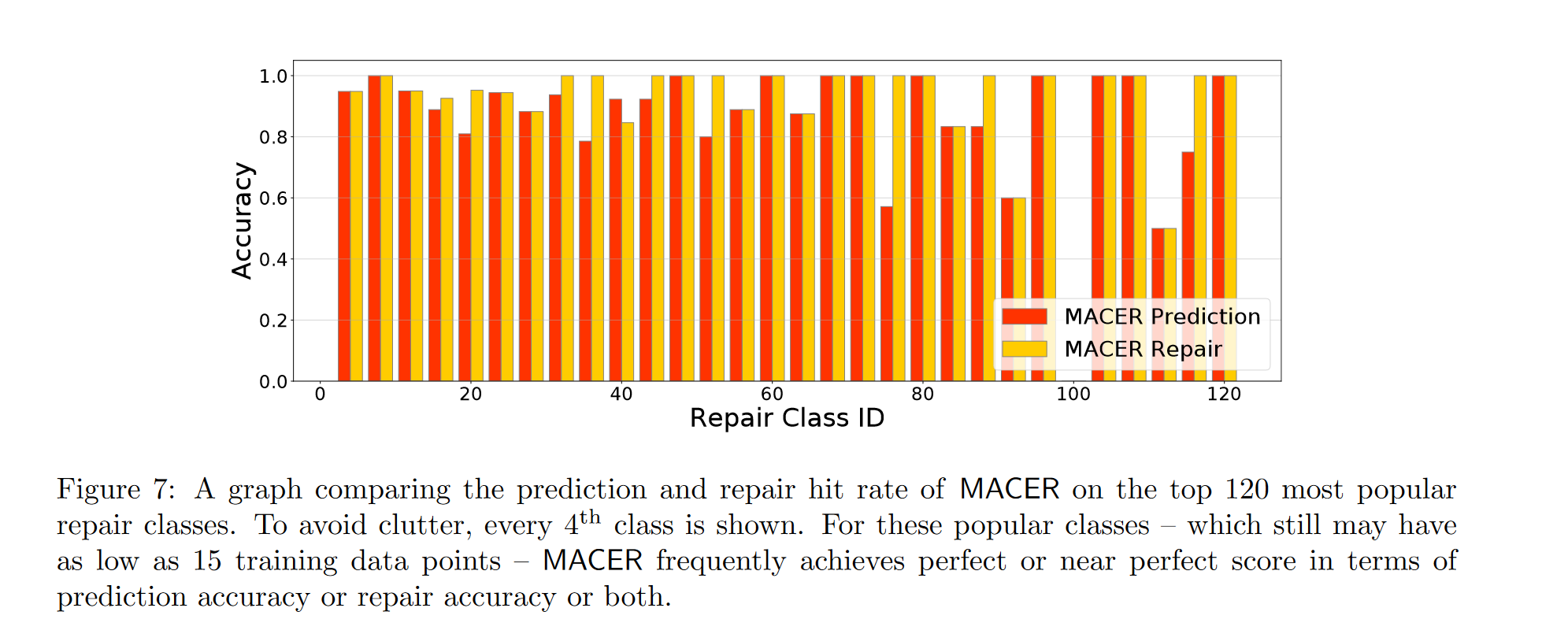
- 在前120个最受欢迎的修复类别中,MACER 在预测精度或修复精度上获得完美或接近完美的分数
图8和图9分别展示在少量训练数据方面的预测准确率和修复准确率
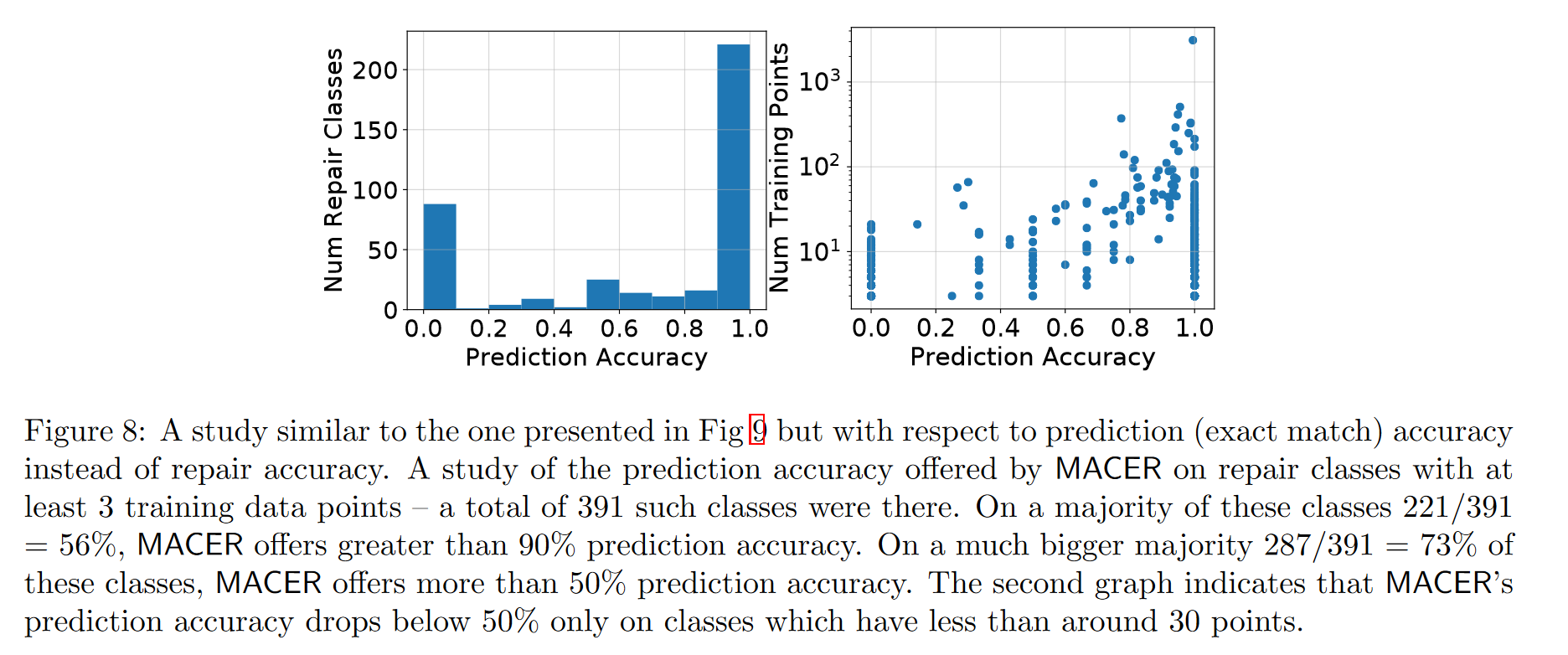
- 考虑具有至少3个训练数据点的修复类别(共391个)
- 221个(56%)类别MACER的预测准确率超过90%
- 287个(73%)类别MACER的预测准确率超过50%
- 仅当训练数据点个数小于约30个时准确率低于50%
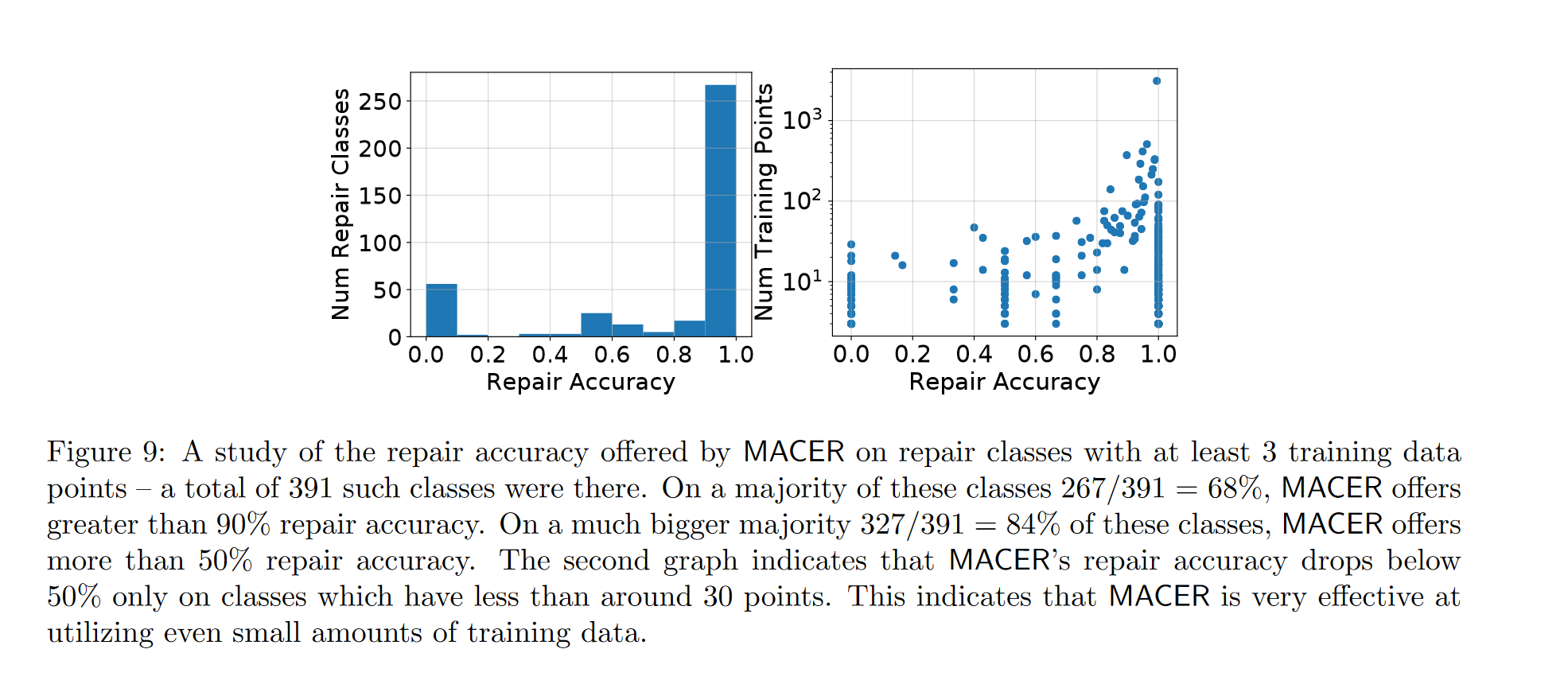
- 考虑具有至少3个训练数据点的修复类别(共391个)
- 267个(68%)类别MACER的修复准确率超过90%
- 327个(84%)类别MACER的修复准确率超过50%
- 仅当训练数据点个数小于约30个时准确率低于50%
表6展示MACER在实际修复中的表现

Pred?:如果 MACER 的首选建议与学生的抽象修复完全匹配,则记录为 Yes,否则记录为 No
Rep? :如果 MACER 的首选建议消除了所有编译错误,则记录为 Yes,否则记录为 No
ZS? :记录该示例是否为“零样本”测试示例,即 MACER 在训练数据中从未见过相应的修复类别
- 在零样本类别修复性能有待提高
表7展示MACER各个组件对单行需要修复的数据集的差异贡献
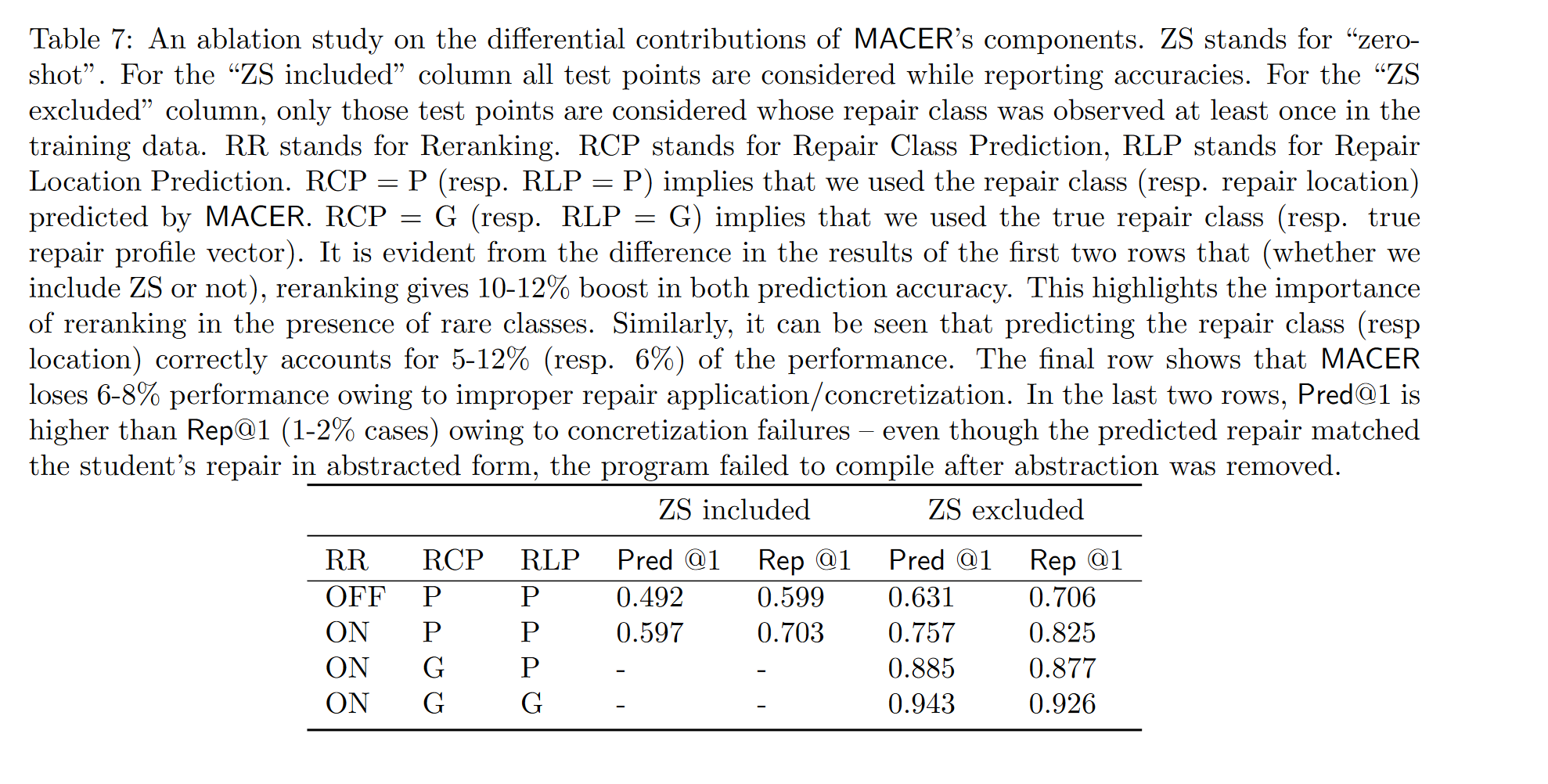
- 重排名使Pre@k和修复准确率提高10-12%(无论是否包含零样本测试样例)
- 正确预测修复类别占性能的5-12%
- 由于修复应用不当损失了6%左右的准确率
总结
与大多数倾向于使用单一而强大的现有技术对比,本文尝试将错误修复过程细分为排序和标记问题,在修复准确率及训练和预测速度上都有显著提升
不足
该方法在罕见错误类别及“零样本”情况性能较差,对此方面的改进是未来的重要研究方向
启发
传统机器学习算法在该领域的可行性















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









