







论文地址:
https://arxiv.org/abs/2206.01191 https://arxiv.org/abs/2206.01191
https://arxiv.org/abs/2206.01191
论文代码:
 https://github.com/snap-research/EfficientFormer
https://github.com/snap-research/EfficientFormer


延迟分析:
-
Observation 1 : Patch embedding with large kernel and stride is a speed bottleneck on mobile devices.
-
Observation 2 : Consistent feature dimension is important for the choice of token mixer. MHSA is not necessarily a speed bottleneck.
-
Observation 3 : CONV-BN is more latency-favorable than LN-Linear and the accuracy drawback is generally acceptable.
-
Observation 4 : The latency of nonlinearity is hardware and compiler dependent.
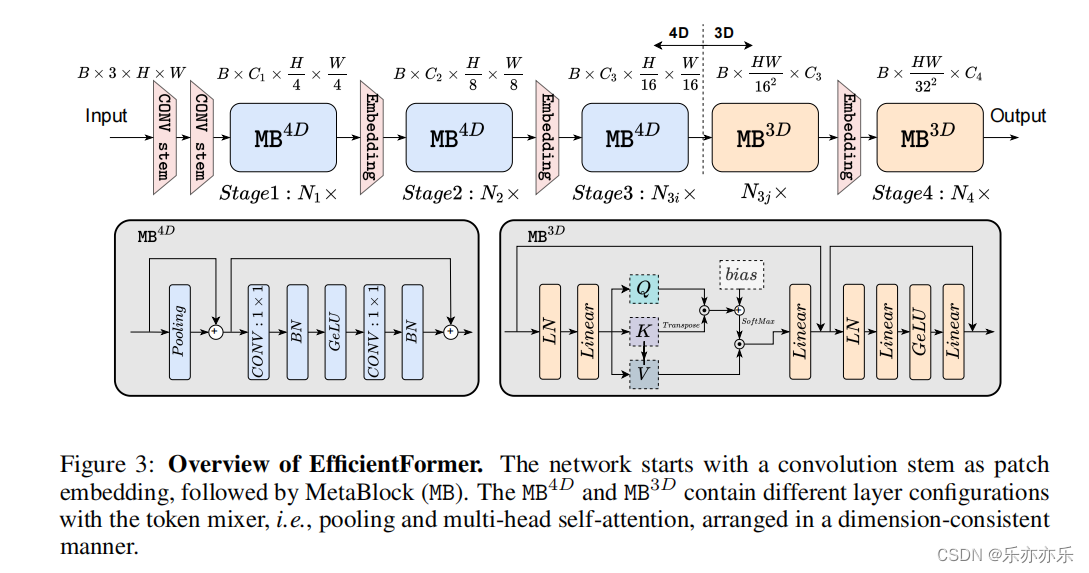
Conv Stem
def stem(in_chs, out_chs):
return nn.Sequential(
nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs // 2),
nn.ReLU(),
nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs),
nn.ReLU(), )Embedding
class Embedding(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2d):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return

class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size // 2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - xclass Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
self.norm1 = nn.BatchNorm2d(hidden_features)
self.norm2 = nn.BatchNorm2d(out_features)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.norm2(x)
x = self.drop(x)
return
class Meta4D(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.token_mixer = Pooling(pool_size=pool_size)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(x))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(x))
else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x))
return x
class Attention(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.qkv = nn.Linear(dim, h)
self.proj = nn.Linear(self.dh, dim)
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.reshape(B, N, self.num_heads, -1).split([self.key_dim, self.key_dim, self.d], dim=3)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return
class LinearMlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return class Meta3D(nn.Module):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Attention(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = LinearMlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(0).unsqueeze(0)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(0).unsqueeze(0)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











