







 本文介绍了强化学习中的值函数近似算法,如Sarsa、Q-learning和DQN,然后转向策略梯度算法,探讨了如何直接从状态输出策略,以及如何通过目标函数和梯度优化寻找最优策略。着重讲解了平均状态价值和平均奖励作为目标函数,以及REINFORCE和actor-critic方法的应用。
本文介绍了强化学习中的值函数近似算法,如Sarsa、Q-learning和DQN,然后转向策略梯度算法,探讨了如何直接从状态输出策略,以及如何通过目标函数和梯度优化寻找最优策略。着重讲解了平均状态价值和平均奖励作为目标函数,以及REINFORCE和actor-critic方法的应用。
引言
在强化学习的过程中,从 Sarsa 到 Q-learning 再到 DQN,本质上都是值函数近似算法。
值函数近似算法都是先学习动作价值函数,然后根据估计的动作价值函数选择动作。如果没有动作价值函数的估计,策略也就不会存在。 例如,DQN的神经网络结构可以表示为如下图所示:
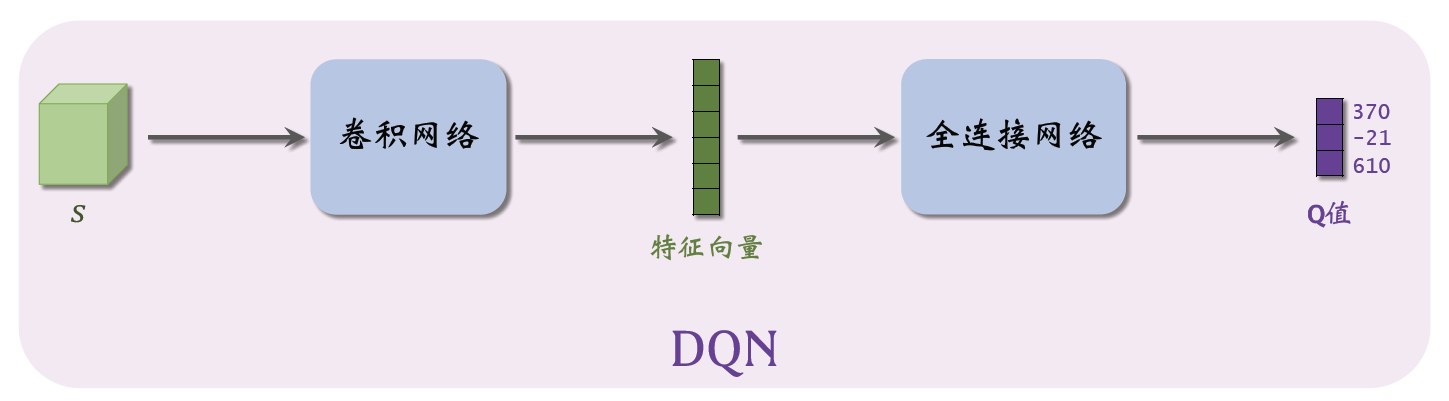
图中,输入是状态 s s s,输出是每个动作的 Q Q Q 值,即对每个动作的评分,分数越高意味着动作越好。通过对值函数的近似,我们可以知道回报最大的路径,从而指导智能体进行动作的选取。
但是,强化学习的目标,是学习最优策略。那么有没有一种可能,我们可以跳过动作价值的评估环节,直接从输入状态,到输出策略呢?
——策略梯度算法
在策略梯度算法中,策略函数的输入是状态 s s s 和动作 a a a,输出是一个0到1之间的概率值,当前最有效的方法是用神经网络近似策略函数。给出一个策略网络结构图:

如图,在策略网络结构中,输入是状态 s s s,输出是动作空间中每个动作的概率值。
两个关键
现在我们已经有了想法——直接从输入得到最优策略,那么随之而来
两个问题:
1、如何来衡量一个策略的好与坏?
2、如何搜索最优策略?
先来看看《强化学习》中关于策略梯度算法的定义:
策略梯度方法基于某种性能度量 J ( θ ) J(\theta) J(θ) 的梯度,这些梯度是标量 J ( θ ) J(\theta) J(θ) 对策略参数的梯度。这些方法的目标是最大化性能指标,所以它们的更新近似于 J J J 的梯度上升
梯度上升: θ t + 1 = θ t + α ∇ J ( θ t ) ^ \theta_{t+1}=\theta_t+\alpha\widehat{\nabla{J(\theta_t)}} θt+1=θt+α∇J(θt)
其中, ∇ J ( θ t ) ^
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6357
6357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









