







 本文详细阐述了强化学习中奖励与回报的区别,介绍了累积回报的概念,重点讲解了如何通过贝尔曼公式计算回报,以及其在策略评估中的作用。文章强调了策略函数、价值函数和动态模型在强化学习中的关键地位。
本文详细阐述了强化学习中奖励与回报的区别,介绍了累积回报的概念,重点讲解了如何通过贝尔曼公式计算回报,以及其在策略评估中的作用。文章强调了策略函数、价值函数和动态模型在强化学习中的关键地位。
奖励 & 回报
在对贝尔曼公式梳理之前,先搞明白一个前提,即,强化学习的目的——学习策略函数,或者最优动作价值函数。而在学习的过程中,判定函数好坏与否的一个很重要的衡量指标,就是奖励/回报。
说在前面,奖励和回报不是一个东西。
由《强化学习》中的一段定义:
在强化学习中,智能体的目标被形式化表征为一种特殊信号,称为收益,它通过环境传递给智能体。在每个时刻,收益都是一个单一标量数值。非正式的说,智能体的目标是最大化其收到的总收益。这意味着需要最大化的不是当前收益,而是长期的累积收益。
……
使用收益信号来形式化目标是强化学习最显著的特征之一。
通过上面的定义,可以将“收益”理解为智能体在与环境交互过程中产生的奖励,具有即时性。而“累积收益”则可以理解为回报。
即——回报 = 即时奖励 + 未来奖励 !
计算回报
在强化学习中,回报的计算对于评估策略的好坏是十分重要的。
在说明计算回报之前,先抛出一个概念——Bootstrapping(自举)
这里的自举,表明回报之间的计算是相互关联的,也即贝尔曼公式的核心——回报的计算,依赖于其他回报。
这里借用《强化学习的数学原理》中一图来阐明回报的依赖性。
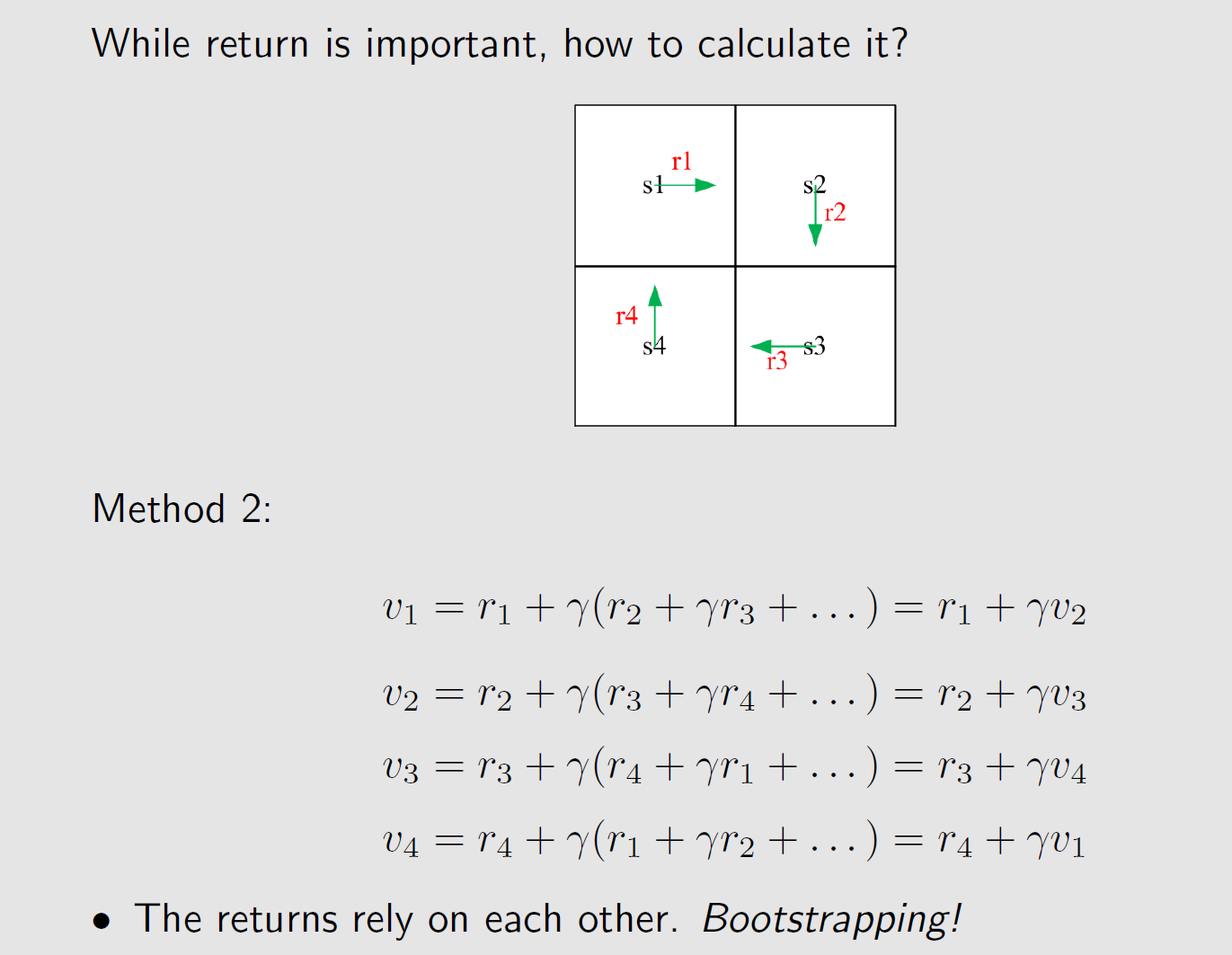
从上图可以看出,对于其中的任意一个状态的回报计算,都依赖于其他回报。
当然,在强化学习中,对于持续性的任务而言,如果单纯的将回报定义为奖励的和,则可能无穷大,因此引入折扣的概念。折扣率决定了未来奖励的现值。(同样的一百块钱,现在的购买力以及十年后的购买力~)
折扣回报 Gt —— 未来所有奖励的加权和
状态价值
回顾
使用收益信号来形式化目标是强化学习最显著的特征之一。
几乎所有的强化学习算法都涉及价值函数的计算。价值函数是状态(或状态与动作二元组)的函数,用来评估当前智能体在给定状态(或给定状态与动作)下有多好。这里的 “有多好” 的概念是用未来预期的收益来定义的,或者更准确的说,就是回报的期望值。当然,智能体期望未来能得到的收益取决于智能体所选择的动作。因此,价值函数是与特定的行为方式相关的,我们可以称为为策略。
状态价值定义为折扣回报的期望值,即有

这样理解:从状态
s
s
s 开始,智能体按照策略
π
\pi
π 进行决策所获得的回报的概率期望值。
可以看到,状态价值是关于
s
s
s 的函数,为条件期望,状态
s
s
s 不同则状态价值
v
π
(
s
)
v_\pi (s)
vπ(s) 不同。同样依赖于策略
π
\pi
π ,策略不同则
v
π
(
s
)
v_\pi (s)
vπ(s) 不同。
状态价值是所有可能回报的期望值。
理解:前文说到,状态价值依赖于状态和策略,在给定状态和策略之下,对动作进行期望,所有可能的回报求期望(均值),即为状态价值。那么易知,对于一个智能体,如果从某一个状态出发,其所有的一切都是确定性的(才某策略下,采用某动作的概率为1),那么其状态价值和回报是相等的。
贝尔曼公式
贝尔曼公式描述了不同状态之间状态价值的关系。
回顾——回报 = 即时奖励 + 未来奖励
公式表述:
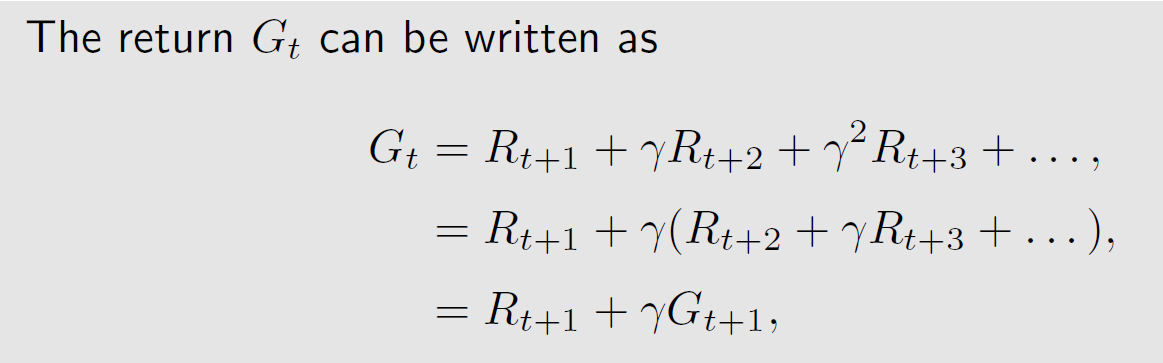
这里很好理解。 G t G_t Gt 为回报, R t + 1 R_{t+1} Rt+1 为下一时刻的即时奖励, G t + 1 G_{t+1} Gt+1 为未来预期奖励和,可以直观的解释为 t + 1 t+1 t+1 时刻的回报, γ \gamma γ 为前文说到的折扣。
将关于状态价值和回报的关系代入,得到公式

期望可拆分,拆分后也是很明晰的——回报 = 即时奖励 + 未来奖励。
下面分块进行计算
第一项

用到了全概率公式,在给定策略
π
\pi
π 下对于动作进行期望操作,以及在已知模型下使用概率
p
(
r
∣
s
,
a
)
p(r|s,a)
p(r∣s,a) 与
r
r
r 的积对奖励进行求和。
第二项

这个也比较好理解,值得注意的是,从第一行到第二行的转换,省略
S
t
=
s
S_t=s
St=s 这一项是基于马尔可夫过程的无记忆性。其余操作在此不赘述。
将两项加和,整理,可得最终的贝尔曼公式
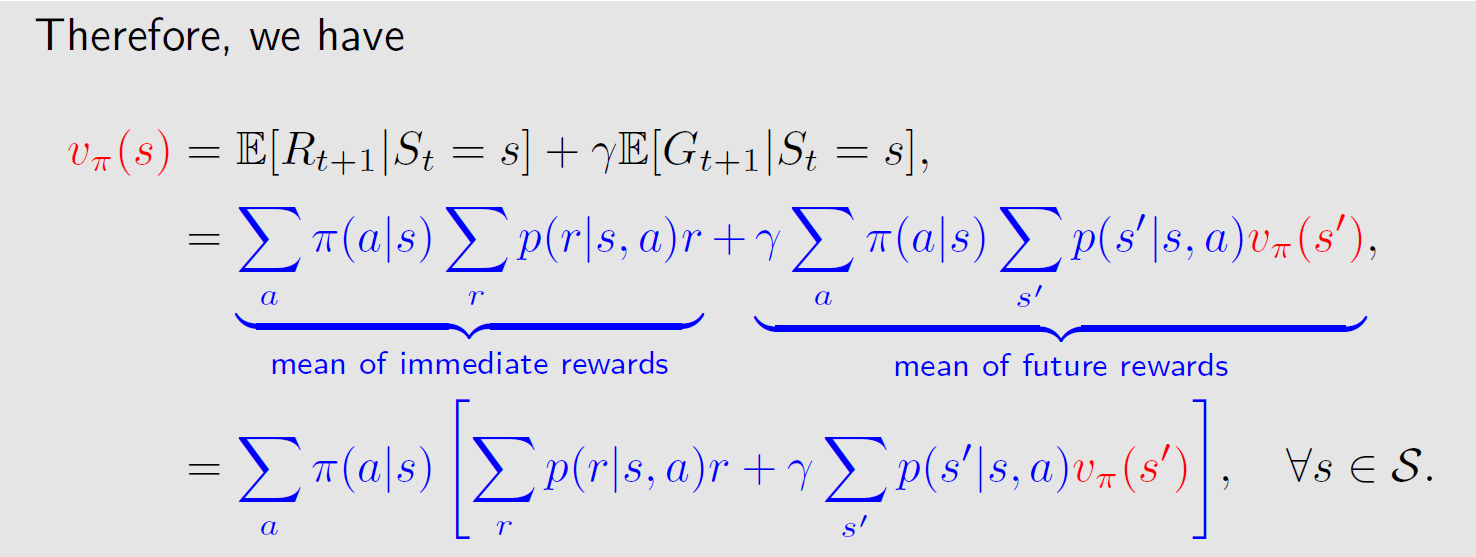
几个特点:
1、贝尔曼公式描述了不同状态的状态价值之间的关系,其中包含两部分——即时奖励和未来奖励;
2、求解贝尔曼公式依赖于策略函数,因此直观的理解,贝尔曼公式解决的问题为对于策略的评价;
3、公式中的
p
p
p,代表的是动态模型。根据
p
p
p是否已知,分为模型和无模型学习(典型的无模型学习为蒙特卡洛算法)。
至此,贝尔曼公式的求解结束。
那么我们再来回顾一下,强化学习的目的——学习策略函数,或者最优动作价值函数。
对于策略评价的过程可以总结为:
给定策略——> 列出贝尔曼公式——> 得到状态价值
以上。
本文参考资料
Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
Zhao, S… Mathematical Foundations of Reinforcement Learning. Springer Nature Press and Tsinghua University Press.
PS:关于赵世钰老师的课程很推荐,B站上有视频课程,在此放出PPT链接,希望大家一起进步。
强化学习的数学原理_赵世钰_课程PPT

















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









