






深度学习和OpenCV的对象检测
作者: Adrian Rosebrock 于 2017 年9月11日在 深度学习,对象检测,OpenCV

几周前,我们学会了如何使用深度学习 和OpenCV 3.3的深度神经网络( dnn )模块对图像进行分类。
虽然这种原始博客文章展示了我们如何分类的图像到ImageNet的1000个独立级标记之一,它不能告诉我们其中对象位于图像。
为了获得图像中对象的边界框(x,y) -坐标,我们需要改为应用对象检测。
对象检测不仅能告诉我们什么是图像,而且其中的对象是也。
在今天的博文中,我们将讨论如何使用深度学习和OpenCV应用对象检测。
寻找这篇文章的源代码?
跳到下载部分。
深度学习和OpenCV的对象检测
在今天关于使用深度学习的物体检测的文章的第一部分中,我们将讨论单次探测器和移动网络。
组合在一起时,这些方法可用于资源受限设备(包括Raspberry Pi,智能手机等)上的超快速实时对象检测
从那里我们将发现如何使用OpenCV的 dnn 模块来加载预先训练的对象检测网络。
这将使我们能够通过网络传递输入图像并获得输出边界框(x,y) -图像中每个对象的坐标。
最后,我们将看看将MobileNet单次检测器应用于示例输入图像的结果。
在未来的博客文章中,我们将扩展我们的脚本以使用实时视频流。
用于物体检测的单发探测器

图1:使用Liu等人的单发探测器(SSD)进行物体检测的示例。
当涉及基于深度学习的对象检测时,您可能会遇到三种主要的对象检测方法:
- 更快的R- CNN(Girshick等,2015)
- 你只看一次(YOLO)(Redmon和Farhadi,2015)
- 单发探测器(SSD)(Liu et al。,2015)
更快的R-CNN可能是使用深度学习进行物体检测的最“听说过”的方法; 然而,这种技术很难理解(特别是对于深度学习的初学者),难以实施,并且难以训练。
此外,即使使用“更快”的实现R-CNN(其中“R”代表“区域提议”),算法也可以非常慢,大约为7FPS。
如果我们正在寻找纯粹的速度,那么我们倾向于使用YOLO,因为这个算法要快得多,能够在Titan X GPU上处理40-90 FPS。YOLO的超快变体甚至可以达到155 FPS。
YOLO的问题在于它留下了很多精确度。
最初由谷歌开发的SSD是两者之间的平衡。该算法比更快的R-CNN更直接(我认为在原始开创性论文中有更好的解释)。
我们还可以享受比Girshick等人快得多的FPS吞吐量。在22-46 FPS取决于我们使用的网络变体。固态硬盘也比YOLO更准确。要了解有关SSD的更多信息,请参阅Liu等人。
MobileNets:高效(深层)神经网络

图2 :( 左)具有批量标准化和ReLU的标准卷积层。(右)深度可分的卷积与深度和点的层,然后是批量归一化和ReLU(刘等人的图和标题)。
在构建对象检测网络时,我们通常使用现有的网络架构,例如VGG或ResNet,然后在对象检测管道中使用它。问题是这些网络架构可能非常大,大约为200-500MB。
诸如这些的网络架构由于其庞大的规模和由此产生的计算数量而不适用于资源受限的设备。
相反,我们可以使用MobileNets(Howard et al。,2017),这是谷歌研究人员的另一篇论文。我们将这些网络称为“MobileNets”,因为它们专为资源受限的设备而设计,例如智能手机。MobileNets与传统CNN的区别在于使用深度可分离卷积(上图2)。
深度可分卷积背后的一般思想是将卷积分为两个阶段:
- 阿3×3深度方向的卷积。
- 接下来是1×1逐点卷积。
这使我们能够实际减少网络中的参数数量。
问题在于我们牺牲准确性 - MobileNets通常不像他们的大兄弟那样准确......
......但它们的资源效率更高。
有关MobileNets的更多详细信息,请参阅Howard等人。
结合MobileNets和Single Shot Detectors,实现快速,高效的基于深度学习的物体检测
如果我们将MobileNet架构和单镜头检测器(SSD)框架结合起来,我们就可以实现快速,高效的基于深度学习的对象检测方法。
我们将在这篇博客文章中使用的模型是Howard等人的原始TensorFlow实现的Caffe版本。并由chuanqi305训练(见GitHub)。
MobileNet SSD首先接受COCO数据集(上下文中的通用对象)的培训,然后在PASCAL VOC上进行微调,达到72.7%mAP(平均精度)。
因此,我们可以在图像中检测到20个对象(背景类为+1),包括飞机,自行车,鸟类,船,瓶,公共汽车,汽车,猫,椅子,奶牛,餐桌,狗,马,摩托车,人,盆栽植物,绵羊,沙发,火车和电视监视器。
使用OpenCV进行基于深度学习的对象检测
在本节中,我们将使用MobileNet SSD +深度神经网络( dnn OpenCV中)模块来构建我们的对象检测器。
我建议使用此博客文章底部的“下载”代码下载源代码+经过培训的网络+示例图像,以便您可以在计算机上测试它们。
让我们继续使用OpenCV开始构建我们的深度学习对象检测器。
打开一个新文件,将其命名为 deep_learning_object_detection .py ,然后插入以下代码:
Object detection with deep learning and OpenCV
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # import the necessary packages import numpy as np import argparse import cv2
# construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="path to input image") ap.add_argument("-p", "--prototxt", required=True, help="path to Caffe 'deploy' prototxt file") ap.add_argument("-m", "--model", required=True, help="path to Caffe pre-trained model") ap.add_argument("-c", "--confidence", type=float, default=0.2, help="minimum probability to filter weak detections") args = vars(ap.parse_args()) |
在第2-4行,我们导入了这个脚本所需的包 - dnn 模块也包含在 cv2中,再次假设您正在使用OpenCV 3.3。
然后,我们解析命令行参数(第7-16行):
- - image :输入图像的路径。
- - prototxt :Caffe原型文件的路径。
- - model :预训练模型的路径。
- - 置信度 :过滤弱检测的最小概率阈值。默认值为20%。
同样,前三个参数的示例文件包含在此博客文章的“下载”部分中。我劝你从那里开始,同时提供你自己的一些查询图像。
接下来,让我们初始化类标签和边框颜色:
Object detection with deep learning and OpenCV
Python
| 18 19 20 21 22 23 24 | # initialize the list of class labels MobileNet SSD was trained to # detect, then generate a set of bounding box colors for each class CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3)) |
第20-23行构建一个名为CLASSES的列表, 其中包含我们的标签。接下来是一个列表 COLORS ,其中包含边界框的相应随机颜色(第24行)。
现在我们需要加载我们的模型:
Object detection with deep learning and OpenCV
Python
| 26 27 28 | # load our serialized model from disk print("[INFO] loading model...") net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"]) |
以上几行不言自明,我们只需打印一条消息并加载我们的 模型 (第27和28行)。
接下来,我们将加载我们的查询图像并准备我们的 blob ,我们将通过网络前馈:
Object detection with deep learning and OpenCV
Python
| 30 31 32 33 34 35 36 37 | # load the input image and construct an input blob for the image # by resizing to a fixed 300x300 pixels and then normalizing it # (note: normalization is done via the authors of the MobileNet SSD # implementation) image = cv2.imread(args["image"]) (h, w) = image.shape[:2] blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5) |
注意到这个区块中的注释,我们加载 图像 (第34行),提取高度和宽度(第35行),并 从我们的图像计算一个300乘300像素的 斑点(第36行))。
现在我们已准备好进行繁重的工作 - 我们将通过神经网络传递这个blob:
Object detection with deep learning and OpenCV
Python
| 38 39 40 41 42 | # pass the blob through the network and obtain the detections and # predictions print("[INFO] computing object detections...") net.setInput(blob) detections = net.forward() |
在第41和42行,我们将输入设置为网络并计算输入的正向传递,将结果存储为 检测 。计算正向传递和相关检测可能需要一段时间,具体取决于您的模型和输入大小,但对于此示例,在大多数CPU上它将相对较快。
让我们遍历我们的 检测 和确定什么以及其中的对象是图像:
Object detection with deep learning and OpenCV
Python
| 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | # loop over the detections for i in np.arange(0, detections.shape[2]): # extract the confidence (i.e., probability) associated with the # prediction confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is # greater than the minimum confidence if confidence > args["confidence"]: # extract the index of the class label from the `detections`, # then compute the (x, y)-coordinates of the bounding box for # the object idx = int(detections[0, 0, i, 1]) box = detections[0, 0, i, 3:7] * np.array([w, h, w, h]) (startX, startY, endX, endY) = box.astype("int")
# display the prediction label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100) print("[INFO] {}".format(label)) cv2.rectangle(image, (startX, startY), (endX, endY), COLORS[idx], 2) y = startY - 15 if startY - 15 > 15 else startY + 15 cv2.putText(image, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2) |
我们首先循环检测我们的检测,记住可以在单个图像中检测到多个对象。我们还对每次检测的置信度(即概率)进行检查。如果置信度足够高(即高于阈值),那么我们将在终端中显示预测,并使用文本和彩色边界框在图像上绘制预测。让我们逐行分解:
通过我们的检测循环 ,首先我们提取 置信度 值(第48行)。
如果 置信 度高于我们的最小阈值(第52行),我们提取类标签索引(第56行)并计算检测到的对象周围的边界框(第57行))。
然后,我们提取框的(x,y) -坐标(第58行),我们将很快用它来绘制矩形并显示文本。
接下来,我们构建一个 包含 CLASS 名称和 置信度的文本 标签 (第61行)。
使用标签,我们将其打印到终端(第62行),然后使用我们先前提取的(x,y)坐标(第63和64行)在对象周围绘制彩色矩形。
通常,我们希望标签显示在矩形上方,但如果没有空间,我们将在矩形顶部下方显示它(第65行)。
最后,我们 使用我们刚刚计算的y值将彩色文本叠加到图像上 (第66和67行)。
剩下的唯一步骤是显示结果:
Object detection with deep learning and OpenCV
Python
| 69 70 71 | # show the output image cv2.imshow("Output", image) cv2.waitKey(0) |
我们将结果输出图像显示在屏幕上,直到按下一个键(第70和71行)。
OpenCV和深度学习对象检测结果
要下载代码+预先培训的网络+示例图像,请务必使用此博客文章底部的“下载”部分。
从那里,解压缩归档并执行以下命令:
Object detection with deep learning and OpenCV
Shell
| 1 2 3 4 5 6 7 8 9 | $ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_01.jpg [INFO] loading model... [INFO] computing object detections... [INFO] loading model... [INFO] computing object detections... [INFO] car: 99.78% [INFO] car: 99.25% |

图3:使用OpenCV,深度学习和物体检测,高速公路上的两个丰田车获得了近100%的信心。
我们的第一个结果显示汽车以近100%的信心得到识别和检测。
在这个例子中,我们使用基于深度学习的对象检测来检测飞机:
Object detection with deep learning and OpenCV
Shell
| 1 2 3 4 5 6 7 8 | $ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_02.jpg [INFO] loading model... [INFO] computing object detections... [INFO] loading model... [INFO] computing object detections... [INFO] aeroplane: 98.42% |
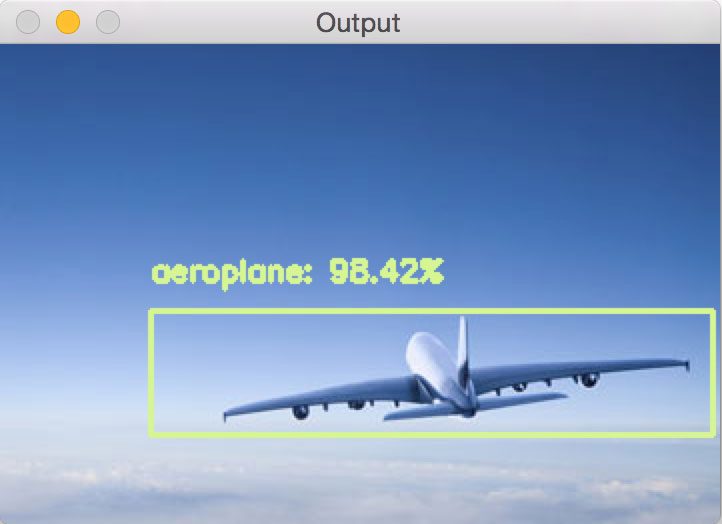
图4:通过Python,OpenCV和深度学习成功检测到飞机。
深度学习检测和定位模糊物体的能力如下图所示,我们看到一匹马(和它的骑手)跳过围绕着两个盆栽植物的篱笆:
Object detection with deep learning and OpenCV
Shell
| 1 2 3 4 5 6 7 8 9 | $ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_03.jpg [INFO] loading model... [INFO] computing object detections... [INFO] horse: 96.67% [INFO] person: 92.58% [INFO] pottedplant: 96.87% [INFO] pottedplant: 34.42% |

图5:通过基于深度学习的物体检测,尽管图像中存在大量物体,但成功识别出骑马和两个盆栽植物的人。
在这个例子中,我们可以看到一个令人印象深刻的100%信心的啤酒瓶:
Object detection with deep learning and OpenCV
Python
| 1 2 3 4 5 | $ python deep_learning_object_detection.py --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_04.jpg [INFO] loading model... [INFO] computing object detections... [INFO] bottle: 100.00% |

图6:深度学习+ OpenCV能够正确检测输入图像中的啤酒瓶。
其次是另一匹马图像,其中还包含一只狗,一辆汽车和一个人:
Object detection with deep learning and OpenCV
Shell
| 1 2 3 4 5 6 7 8 9 | $ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_05.jpg [INFO] loading model... [INFO] computing object detections... [INFO] car: 99.87% [INFO] dog: 94.88% [INFO] horse: 99.97% [INFO] person: 99.88% |

图7:此图像中的几个对象包括汽车,狗,马和人都被识别。
最后,我和家族小猎人杰玛的照片:
Object detection with deep learning and OpenCV
Shell
| 1 2 3 4 5 6 7 | $ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_06.jpg [INFO] loading model... [INFO] computing object detections... [INFO] dog: 95.88% [INFO] person: 99.95% |

图8:通过深度学习,对象检测和OpenCV,我和家庭比格犬被纠正为“人”和“狗”。电视监视器无法识别。
不幸的是,在这张图片中没有识别出电视监视器,这可能是由于(1)我阻挡它和(2)电视周围的对比度差。话虽这么说,我们已经使用OpenCV的dnn 模块展示了出色的物体检测结果。
摘要
在今天的博客文章中,我们学习了如何使用深度学习和OpenCV进行对象检测。
具体来说,我们使用MobileNets + Single Shot Detectors和OpenCV 3.3的全新(全面检修)dnn 模块来检测图像中的对象。
作为一个计算机视觉和深度学习社区,我们非常 感谢Aleksandr Rybnikov的贡献,这是dnn模块的主要贡献者, 可以从OpenCV库中进行深入学习。您可以在此处找到Aleksandr的原始OpenCV示例脚本 - 我已经为此博客文章修改了它。
在未来的博客文章中,我将演示如何修改今天的教程以使用实时视频流,从而使我们能够对视频执行基于深度学习的对象检测。我们一定会利用高效的帧I / O来增加整个流水线的FPS。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









