









一、原始数据集
数据集链接:https://mcrlab.net/research/mvsa-sentiment-analysis-on-multi-view-social-data/
数据集介绍:由两个独立的数据集组成,分别是MVSA-Single数据集和 MVSA-Multi数据集,前者的每条图文对只有一个标注,后者的每条图文对由三个标注者给出。官方声明MVSA-Single数据集包含 5,129 条图文对(实际只有4869条),MVSA-Multi 包含了 19,600 条图文对(实际19600条,)。
(1)MVSA-Single数据集
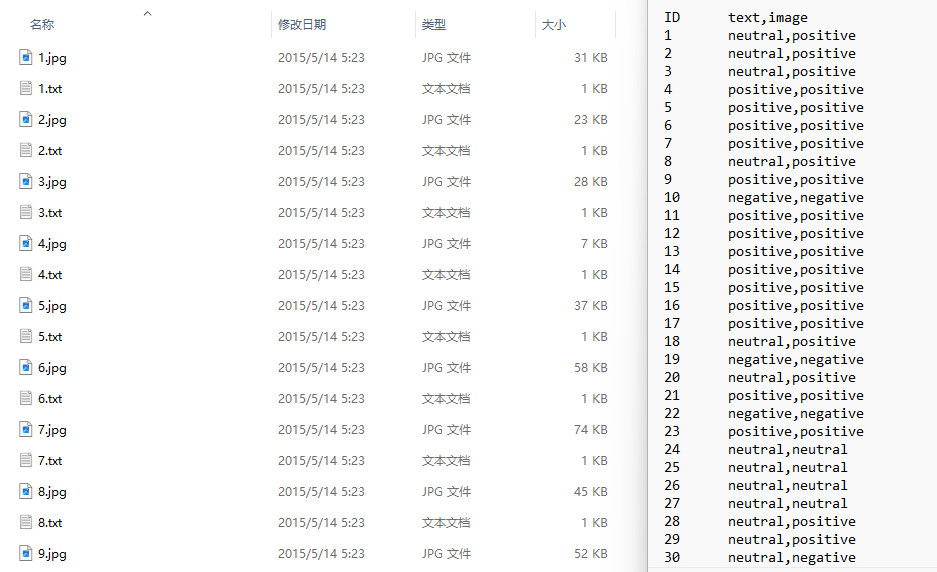
(2)MVSA-Multi数据集
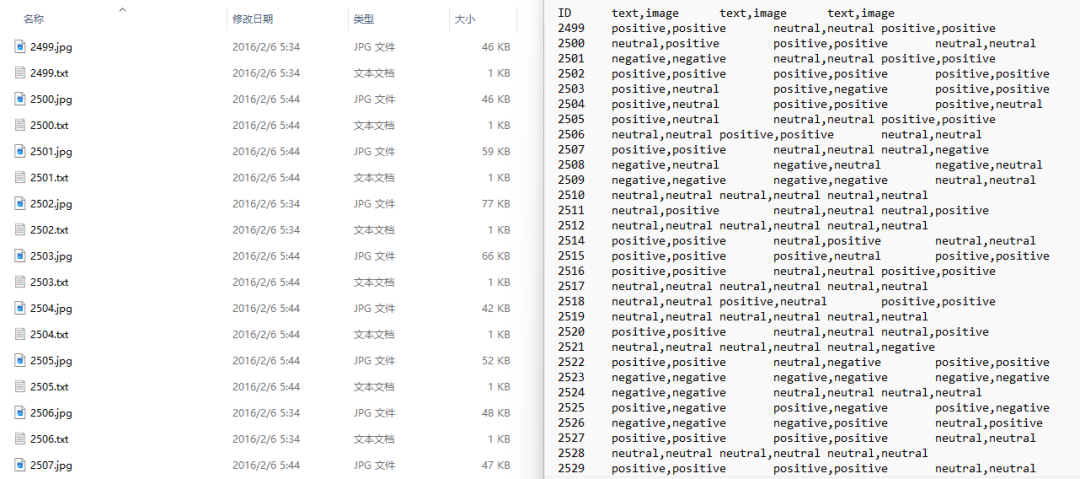
二、处理方法
(1)MVSA-Single数据集
删除 MVSA-Single 数据集中图片和文字标注情感的正负极性不同(存在positive和negative)的图文对,剩余的图文对中,如果图片或者文本的情感有一者为中性(neutral),则选择另一个积极或者消极的标签作为该图文对的情感标签,最终得到4511个图文对。
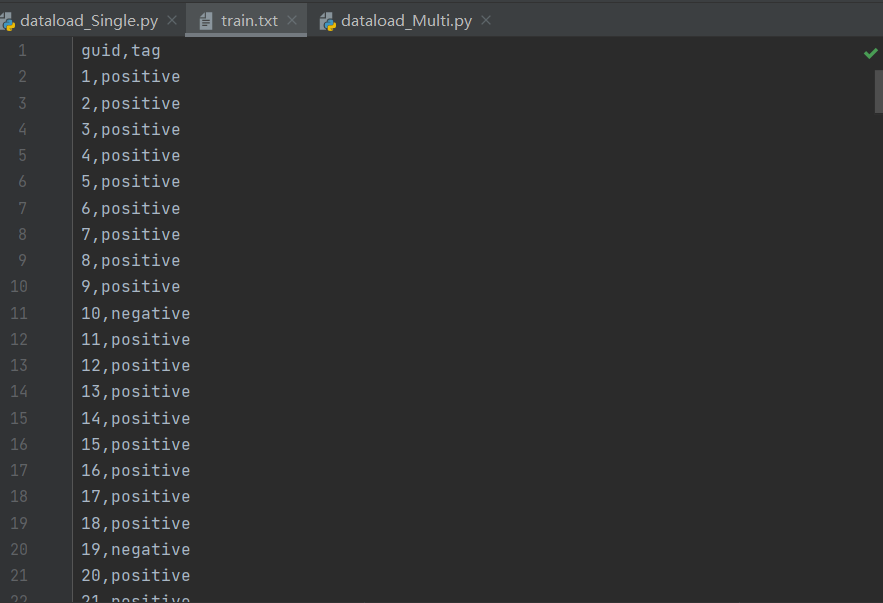
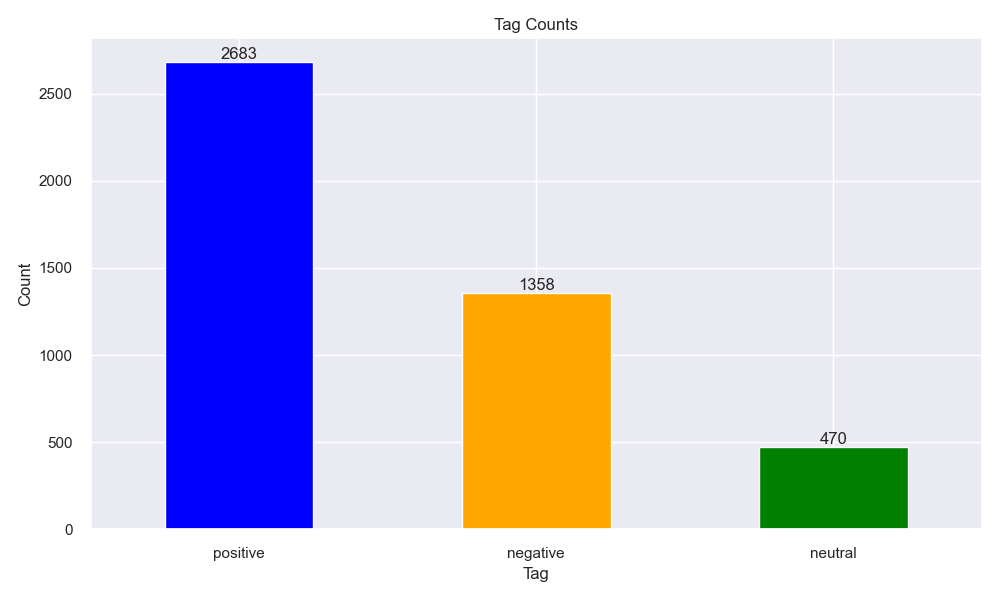
(2)MVSA-Multi数据集
采用投票机制,即有 2 个或 2 个以上的标注者给出的情感极性标注一致,则保留该条数据,否则删除。先基于MVSA-Single 的方法确定每个人的标签,然后根据三个人统计结果进行投票,最终得到17510个图文对。
注:由于数据集中存在损坏图片:3151.jpg、3910.jpg、5995.jpg,因此将其进行去除,最终实际得到17507个图文对。
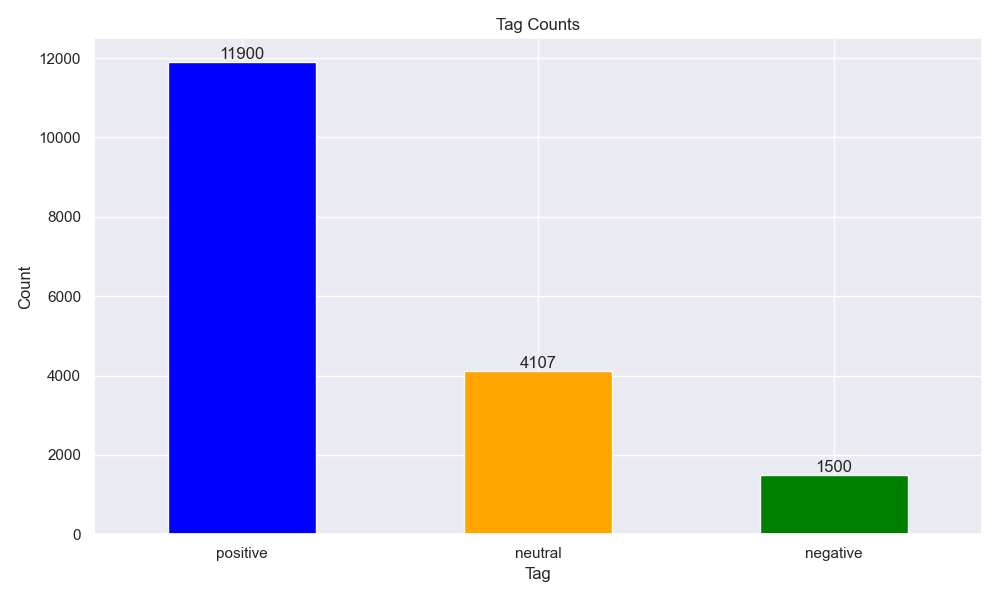
处理后的数据:多模态情感分析——MVSA数据集
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!



















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











