







1.背景
Dice 系数是常用的分割的评价标准之一 后面还会介绍其他的评价标准。
而且我发现大家的东西都是互相抄来抄去没有意思
2.Dice系数
- 原理及定义
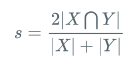 公式1
公式1
假设 X 是 Output【也就是我们输出结果】 维度为(3,3)
Y 为lable【标签】 维度为(3,3) - 单一分类
首先我们需要明白Dice系数使用判断两个图片(这里我就指的是X Y)的相似度的,但是在我们的分割任务当中我们通常将
0 代表背景
1 代表预测分割
现在我们假设
a=[
[1,0,1],
[0,0,0],
[0,1,0]
]
b=[
[0,0,0],
[0,0,0],
[0,1,0]
]
大家需要比较的肯定是1,也就是预测分割这部分和真实的label之间的相似度,计算方法如下:
- 计算出 相应位置都是1的个数 1个
- 分别计算出含有1的个数并相加 4个
- 带入公式计算 2*1/4 = 0.5 0.5
代码实现如下:(pytorch 实现)
import torch
import numpy as np
a_numpy = np.array([
[1,0,1],
[0,0,0],
[0,1,0]
])
b_numpy = np.array([
[0,0,0],
[0,0,0],
[0,1,0]
])
a = torch.from_numpy(a_numpy)
b = torch.from_numpy(b_numpy)
# a * b 代表对应位置相乘 不懂的可以看一下 torch文档,norm为1范数
res = 2*(a.float()*b.float()).norm(1)/(a.float().norm(1)+b.float().norm(1))
print(res)
输出结果为0.5
为什么使用上述的计算方法了? 因为有时候我们输出的label可能为百分比的时候
a=[
[0.7, 0 , 0.8],
[0.1 , 0.2 , 0.3],
[0.4 , 0.9 , 0.2]
]
b=[
[0,0,0],
[0,0,0],
[0,1,0]
]
我们使用了相同的代码进行计算得出结果为0.3913
如果我们对a进行修改从0.7 升到 1 dice值降到0.3673
可能是我个人的见识比较浅薄,我觉得大家如果使用可能性计算Dice的话可能会对极大概率的影响不够充分,也就是A与B的交际部分,虽然我们乘上了一个2 但是在绝大数512512 图片中 假设物体分辨率为 3030,261244*(小概率)加到分母中,我个人认为这是不太合理的,希望大家可以批评指正。
·························································································································
同时为了避免出现X Y 全部都是0 导致公式1 出现分母为0的情况,我们通常会对其进行一个平滑调整 也就是加上一个smooth
smooth = 1.
a = torch.from_numpy(a_numpy)
b = torch.from_numpy(b_numpy)
res = (2*(a.float()*b.float()).norm(1) +smooth) / ((a.float().norm(1)+b.float().norm(1))+smooth)
print(res)
这里我又不带明白了 这里的smooth 应该是越小对原始的影响应该越小,大家好像都设置为1了 可能是一种约定俗称吧
最后就是变种时间 正对 |X| + |Y|
有的人会使用我上面说的1范数,但是我发现好像大家也有采用取元素平方求和的做法:
我去 居然有人认为这是更加通用性的代码,这明明是用来处理Dice_loss时候的代码,大家注意观察不要被骗了 害我想来半天
def dice_coeff(pred, target):
smooth = 1.
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + smooth) / (m1.sum() + m2.sum() + smooth)
补充:下面给出一个比较通用的代码 在我训练医学图像的过程中,发现其一般都是不使用使用Background层参与计算的,Mutil-task/ Mutil-label的任务通常使用分层计算然后求均值的方式来实现。
代码如下 代码是在monai 一个非常出名的医疗图像使用库中扒下来的
import warnings
from typing import Callable, List, Optional, Sequence, Union
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.loss import _Loss
from monai.losses.focal_loss import FocalLoss
# from monai.losses.spatial_mask import MaskedLoss
from monai.networks import one_hot
from monai.utils import LossReduction, Weight
class Dice(_Loss):
"""
Compute average Dice loss between two tensors. It can support both multi-classes and multi-labels tasks.
Input logits `input` (BNHW[D] where N is number of classes) is compared with ground truth `target` (BNHW[D]).
Axis N of `input` is expected to have logit predictions for each class rather than being image channels,
while the same axis of `target` can be 1 or N (one-hot format). The `smooth_nr` and `smooth_dr` parameters are
values added to the intersection and union components of the inter-over-union calculation to smooth results
respectively, these values should be small. The `include_background` class attribute can be set to False for
an instance of DiceLoss to exclude the first category (channel index 0) which is by convention assumed to be
background. If the non-background segmentations are small compared to the total image size they can get
overwhelmed by the signal from the background so excluding it in such cases helps convergence.
Milletari, F. et. al. (2016) V-Net: Fully Convolutional Neural Networks forVolumetric Medical Image Segmentation, 3DV, 2016.
"""
def __init__(
self,
include_background: bool = True,
to_onehot_y: bool = False,
sigmoid: bool = False,
softmax: bool = False,
other_act: Optional[Callable] = None,
squared_pred: bool = False,
jaccard: bool = False,
reduction: Union[LossReduction, str] = LossReduction.MEAN,
smooth_nr: float = 1e-5,
smooth_dr: float = 1e-5,
batch: bool = False,
) -> None:
"""
Args:
include_background: if False, channel index 0 (background category) is excluded from the calculation.
to_onehot_y: whether to convert `y` into the one-hot format. Defaults to False.
sigmoid: if True, apply a sigmoid function to the prediction.
softmax: if True, apply a softmax function to the prediction.
other_act: if don't want to use `sigmoid` or `softmax`, use other callable function to execute
other activation layers, Defaults to ``None``. for example:
`other_act = torch.tanh`.
squared_pred: use squared versions of targets and predictions in the denominator or not.
jaccard: compute Jaccard Index (soft IoU) instead of dice or not.
reduction: {``"none"``, ``"mean"``, ``"sum"``}
Specifies the reduction to apply to the output. Defaults to ``"mean"``.
- ``"none"``: no reduction will be applied.
- ``"mean"``: the sum of the output will be divided by the number of elements in the output.
- ``"sum"``: the output will be summed.
smooth_nr: a small constant added to the numerator to avoid zero.
smooth_dr: a small constant added to the denominator to avoid nan.
batch: whether to sum the intersection and union areas over the batch dimension before the dividing.
Defaults to False, a Dice loss value is computed independently from each item in the batch
before any `reduction`.
Raises:
TypeError: When ``other_act`` is not an ``Optional[Callable]``.
ValueError: When more than 1 of [``sigmoid=True``, ``softmax=True``, ``other_act is not None``].
Incompatible values.
"""
super().__init__(reduction=LossReduction(reduction).value)
if other_act is not None and not callable(other_act):
raise TypeError(f"other_act must be None or callable but is {type(other_act).__name__}.")
if int(sigmoid) + int(softmax) + int(other_act is not None) > 1:
raise ValueError("Incompatible values: more than 1 of [sigmoid=True, softmax=True, other_act is not None].")
self.include_background = include_background
self.to_onehot_y = to_onehot_y
self.sigmoid = sigmoid
self.softmax = softmax
self.other_act = other_act
self.squared_pred = squared_pred
self.jaccard = jaccard
self.smooth_nr = float(smooth_nr)
self.smooth_dr = float(smooth_dr)
self.batch = batch
def forward(self, input: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
"""
Args:
input: the shape should be BNH[WD], where N is the number of classes.
target: the shape should be BNH[WD] or B1H[WD], where N is the number of classes.
Raises:
AssertionError: When input and target (after one hot transform if set)
have different shapes.
ValueError: When ``self.reduction`` is not one of ["mean", "sum", "none"].
"""
if self.sigmoid:
input = torch.sigmoid(input)
n_pred_ch = input.shape[1]
if self.softmax:
if n_pred_ch == 1:
warnings.warn("single channel prediction, `softmax=True` ignored.")
else:
input = torch.softmax(input, 1)
if self.other_act is not None:
input = self.other_act(input)
if self.to_onehot_y:
if n_pred_ch == 1:
warnings.warn("single channel prediction, `to_onehot_y=True` ignored.")
else:
target = one_hot(target, num_classes=n_pred_ch)
if not self.include_background:
if n_pred_ch == 1:
warnings.warn("single channel prediction, `include_background=False` ignored.")
else:
# if skipping background, removing first channel
target = target[:, 1:]
input = input[:, 1:]
if target.shape != input.shape:
raise AssertionError(f"ground truth has different shape ({target.shape}) from input ({input.shape})")
# reducing only spatial dimensions (not batch nor channels)
reduce_axis: List[int] = torch.arange(2, len(input.shape)).tolist()
if self.batch:
# reducing spatial dimensions and batch
reduce_axis = [0] + reduce_axis
intersection = torch.sum(target * input, dim=reduce_axis)
if self.squared_pred:
target = torch.pow(target, 2)
input = torch.pow(input, 2)
ground_o = torch.sum(target, dim=reduce_axis)
pred_o = torch.sum(input, dim=reduce_axis)
denominator = ground_o + pred_o
if self.jaccard:
denominator = 2.0 * (denominator - intersection)
f: torch.Tensor = 1.0 - (2.0 * intersection + self.smooth_nr) / (denominator + self.smooth_dr)
if self.reduction == LossReduction.MEAN.value:
f = torch.mean(f) # the batch and channel average
elif self.reduction == LossReduction.SUM.value:
f = torch.sum(f) # sum over the batch and channel dims
elif self.reduction != LossReduction.NONE.value:
raise ValueError(f'Unsupported reduction: {self.reduction}, available options are ["mean", "sum", "none"].')
return f
通过我介绍大家可以知道使用的时候
in_data = torch.randint(low=0,high=2,size=(1,3,50,50))
label = torch.randint(low=0,high=2,size=(1,3,50,50))
dice_loss = DiceLoss(include_background=False, to_onehot_y=False, softmax=False, reduction="mean")
print(in_data.shape)
print(dice_loss(in_data,label))















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









