







 本文解析了光流法的基本原理,探讨了displacementfield、deformationfield和opticalflow之间的关系,并通过代码展示了如何用PyTorch实现图像的光流变形。重点在于讲解如何使用grid_sample进行坐标变换和位移计算。
本文解析了光流法的基本原理,探讨了displacementfield、deformationfield和opticalflow之间的关系,并通过代码展示了如何用PyTorch实现图像的光流变形。重点在于讲解如何使用grid_sample进行坐标变换和位移计算。
总是被导师怼 唉
-
一些定义是什么?
光流(optical flow)法是运动图像分析的重要方法,它的概念是由 James J. Gibson于20世纪40年代首先提出的,是指时变图像中模式运动速度。因为当物体在运动时,它在图像上对应点的亮度模式也在运动。
简单来说,光流只得应该是速度。但是速度是有方向的,所以我们一张256X256(后面相同)的图片采用256X256X2(分别表示水平和竖直方向上的速度)的方式来表示。
通常情况下,为了简化我们将其直接作为位移,也就是默认其时间为1(等同于displacement)displacement field:就是u = X-x 其实就是代表位移
一张图片的坐标假设为 X ,当前的坐标为x
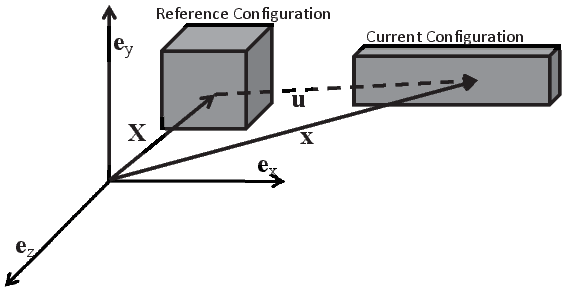
deformation field(形变场):是指的坐标! 就是x
下面是一些推到,帮助理解他们之间的关系
deformation field = displacement field + X
我们通常认为 displacement field 和 光流是可以替代的,而X通常是代表所有前一张图的坐标
deformation field = optical flow + X -
结合代码
代码中,grid 为 X ,flow为 displacement field (optical flow),vgrid 为 deformation field
在实现过程中因为.grid_sample函数要求输入是-1到1 所以坐标看起来很奇怪。
def warp(x,flow):
"""
warp an image/tensor (im2) back to im1, according to the optical flow
x: [B, C, H, W] (im2)
flo: [B, 2, H, W] flow
"""
B, C, H, W = x.size()
xx = torch.arange(0, W).view(1, -1).repeat(H, 1)
yy = torch.arange(0, H).view(-1, 1).repeat(1, W)
xx = xx.view(1, 1, H, W).repeat(B, 1, 1, 1)
yy = yy.view(1, 1, H, W).repeat(B, 1, 1, 1)
grid = torch.cat((xx, yy), 1).float()
x = x.cuda()
grid = grid.cuda()
# 图二的每个像素坐标加上它的光流即为该像素点对应在图一的坐标
vgrid = Variable(grid) + flow
vgrid[:, 0, :, :] = 2.0 * vgrid[:, 0, :, :].clone() / max(W - 1, 1) - 1.0
# 取出光流v这个维度,原来范围是0~W-1,再除以W-1,范围是0~1,再乘以2,范围是0~2,再-1,范围是-1~1
vgrid[:, 1, :, :] = 2.0 * vgrid[:, 1, :, :].clone() / max(H - 1, 1) - 1.0 # 取出光流u这个维度,同上
vgrid = vgrid.permute(0, 2, 3, 1) # from B,2,H,W -> B,H,W,2,为什么要这么变呢?是因为要配合grid_sample这个函数的使用
output = nn.functional.grid_sample(x, vgrid, align_corners=True)
mask = torch.autograd.Variable(torch.ones(x.size())).cuda()
mask = nn.functional.grid_sample(mask, vgrid, align_corners=True)
##2019 author
mask[mask < 0.9999] = 0
mask[mask > 0] = 1
# scale grid to [-1,1]

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









