







model
Listen,Attend,and Spell(LAS)[Chorowski.et al,NLPS
'2015]
it is the typical seq2seq with attention.
上半部encoder
Listen——encoder:acoustic features——>high-level representations
1.Extract content information.
2.Remove speaker variance,remove noise。
Common的做法,1-D CNN再接RNN
其中CNN(Filters in higher layer can consider longer sequence)
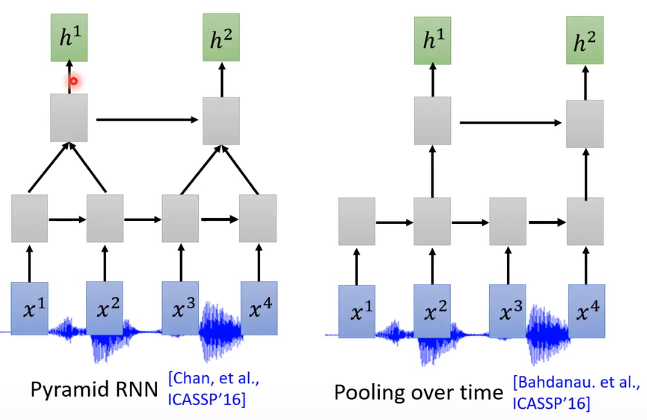
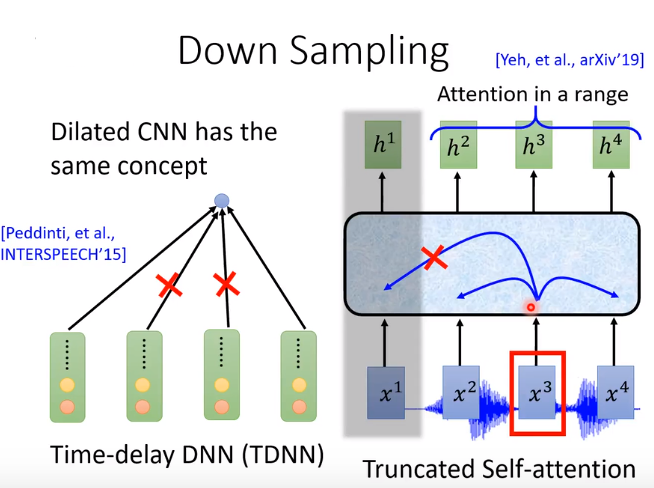
Listen——Down Sampling
Pyramid RNN [Chan,et al. ICASSP,2016]
Pooling over time [Bahdanau,et al. ICASSP,2016]
中部Attend
Attention
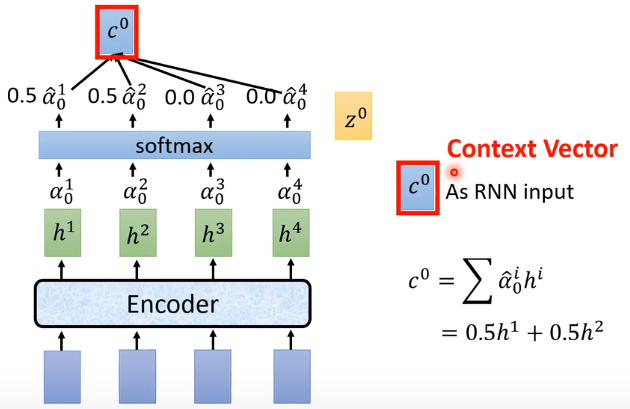
- vector z 0 z^0 z0与Encoder输出 h 1 h^1 h1作为match函数的输入,输出一个scaler α 0 1 α^{1}_{0} α01 标量。
- z 0 z^0 z0会与Encoder每个time step的output计算Attention得到 α 0 1 α^{1}_{0} α01, α 0 2 α^{2}_{0} α02 , α 0 3 α^{3}_{0} α03, α 0 4 α^{4}_{0} α04 。
- 对 α 0 1 : 4 α^{1:4}_{0} α01:4 进行softmax(加起来和为1),作为权值对 h 1 : 4 h_{1:4} h1:4进行加权求和,得到 C 0 C^0 C0。C:Context Vector.
- C 0 C^0 C0作为Decoder RNN部分的输入
match Function种类
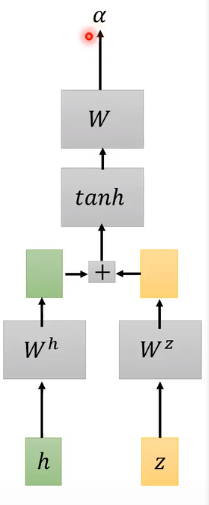
- Dot-product Attention[Chan,et al.ICASSP,2016],计算h与z的相似度。h,z经过矩阵
W
h
W^h
Wh、
W
z
W^z
Wz进行变换(linear transform)。

- Additive Attention [Chorowski,et al.NIPS,2015]
下半部decoder
Spell——decoder,输出distribution
C
0
C^0
C0有不同的用法,其中一种就是作为decoder的输入。
token取决于上一节所说的类型,字母or单词

- 输入 c 0 c^0 c0,隐藏层由 z 0 z^0 z0更新为 z 1 z^1 z1,隐藏层输出通过transform(矩阵变换)得到预测向量output。
- 拿 z 1 z^1 z1作Attention,得到 α 1 1 α^{1}_{1} α11, α 1 2 α^{2}_{1} α12 , α 1 3 α^{3}_{1} α13, α 1 4 α^{4}_{1} α14。通过softmax得到 c 1 c^1 c1,作为Decoder的第二次输入。
- 每个time step得到的预测向量output会作为下一个time step时Decoder的输入。
- 最后输入 c 3 c^3 c3输出<EOS>代表句子的结束。

Beam Search
assume there are only two tokens,V=2
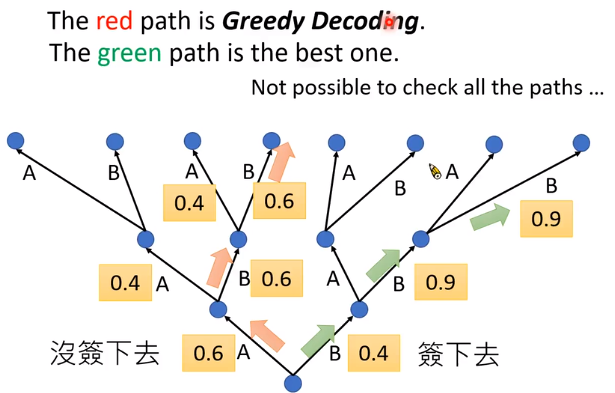 使用Beam Search
使用Beam Search
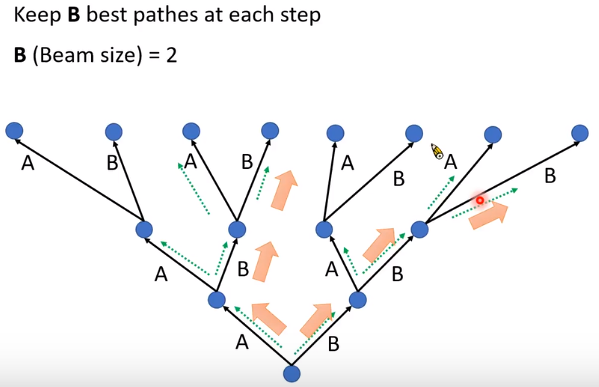
我们需要做的是:调参(beam size)
Training
与inference不同,which decoder的输出(预测值)作为下一个time step时decoder的输入。
Training,使用decoder的真实值(ground truth,one-hot)作为下一步decoder的输入。
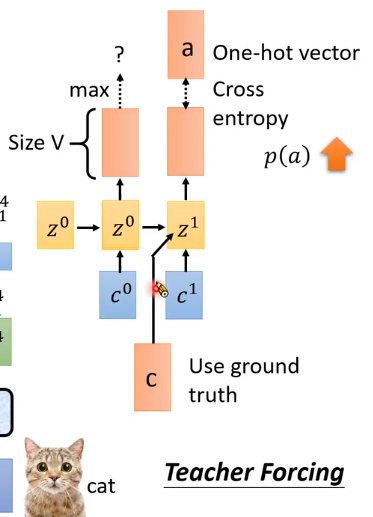
上一步预测的好坏,对下一步的输入没影响。
Teacher Forcing
比如spell CAT,模型一开始学习能力差。假设第一步预测的是字母b,那模型第二步就会学习到如果见到b,就会输出a。后面模型变好,第一步输出c,模型第二步就会学习到如果见到c,就输出a。那么前面的训练就没有意义了。
Attention种类

左边为上述介绍,
z
t
z^t
zt与encoder作attention得到
c
t
c^t
ct作用于time step
t
+
1
t+1
t+1。
右边的
c
t
c^t
ct作用于time step
t
t
t。注意黄色部分
Z
t
Z^t
Zt为hidden layer,不是输入。
Attention
Attention作用
-
在翻译任务中,输入原文句子中的第一个词,翻译时可能出现在翻译句子中的最后一个词。所以要attention机制。让decoder关注(weights, α 0 1 : 4 α^{1:4}_{0} α01:4)原文句子中的哪一个词。
-
但是对于语音辨识,我们是根据语音的顺序spell出句子,即decoder关注(weights, α 0 1 : 4 α^{1:4}_{0} α01:4)语音的位置应该是按时间从左往右移。

-
attention机制使模型过于灵活,相当于语音辨识任务来说太过强大,难以训练。我们希望attention只涉及随时间移动的某一段语音区域。
Location-aware attention

现在我们要计算time step t=1时对Encoder h 2 h^2 h2的权值(attention), α 1 2 α^{2}_{1} α12。
Location-aware
- 使用前一个time step t=0时Encoder产生的 α 0 1 α^{1}_{0} α01, α 0 2 α^{2}_{0} α02 , α 0 3 α^{3}_{0} α03, α 0 4 α^{4}_{0} α04。(经过softmax)
- process history的输入体现了location,即只考虑 h 2 h^2 h2附近的α。process history为transform,输出一个向量,作为time step t=1时attention的输入。
- 此时attention机制考虑了位置关系,随着语音位置往右移。
结束
视频到这还没结束,还结束了LAS(end-to-end)的性能。在数据集少的时候,没有以往的模型(也使用deep learning)好。
2000hr的语料库

LAS的优势

LAS无法解决一边听一边辨识。
















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









