







0.Abstract
0.1逐句翻译
While supervised learning has enabled great progress in many applications, unsupervised learning has not seen such widespread adoption, and remains an important and challenging endeavor for artificial intelligence.
尽管监督学习在许多应用中取得了巨大进展,但无监督学习尚未得到如此广泛的采用,仍然是人工智能的重要和具有挑战性的努力。
In this work, we propose a universal unsupervised learning approach to extract useful representations from high-dimensional data, which we call Contrastive Predictive Coding.
在这项工作中,我们提出了一种通用的无监督学习方法来从高维数据中提取有用的表示,我们称之为对比预测编码。
The key insight of our model is to learn such representations by predicting the future in latent space by using powerful autoregressive models.
我们模型的关键观点是通过使用强大的自回归模型预测潜在空间中的 the future来学习这种表示。
感觉这个future应该是有特殊含义的,但是现在还不理解
We use a probabilistic contrastive loss which induces the latent space to capture information that is maximally useful to predict future samples.
我们使用一个概率对比损失,诱导潜在空间捕捉信息,这是最有用的预测未来的样本。
It also makes the model tractable by using negative sampling.
同时利用负采样使模型易于被管理。
(大约就是用负例让整个模型变得更容易控制)
While most prior work has focused on evaluating representations for a particular modality, we demonstrate that our approach is able to learn useful representations achieving strong performance on four distinct domains: speech, images, text and reinforcement learning in 3D environments.
虽然之前的大部分工作都集中在评估特定形态的表示,但我们证明了我们的方法能够学习有用的表示,在四个不同的领域实现强大的性能:语音、图像、文本和3D环境中的强化学习。
(大约就是说之前的模型都是在特定的环境下才能取得较好的效果,但是本文的提出的方法在各种方面都得到了有效的验证)
0.2总结
- 1.这个东西是进行无监督表示学习方面内容研究的
- 2.这个东西关注一种叫做future的东西
- 3.这个东西是有负例的,所以便于控制模型进行work
- 4.这个东西经过测试可以在各种领域有效地work
1.Introduction
第一段(肯定有监督特征提取的发展,并指出不足)
Learning high-level representations from labeled data with layered differentiable models in an end-to-end fashion is one of the biggest successes in artificial intelligence so far.
以端到端的方式,用分层可微模型从标记数据中学习高级表示是人工智能领域迄今为止最大的成功之一。(这里是肯定有监督学习在学习特征方面工作的效果)
These techniques made manually specified features largely redundant and have greatly improved state-of-the-art in several real-world applications [1, 2, 3].
这些技术使得手工指定的特性在很大程度上是冗余的,并在几个实际应用程序中大大改进了技术水平。
(就是说自动特征提取在较多应用上已经可以取代手工的特征提取了)
However, many challenges remain, such as data efficiency, robustness or generalization.
然而,仍然存在许多挑战,如数据效率、健壮性或泛化。
第二段(无监督因为没有对特征进行领域特异化,所以鲁棒性可能更好)
Improving representation learning requires features that are less specialized towards solving a single supervised task.
改进表示学习需要的特性不是专门针对解决单个监督任务。
(表征学习的改进)
For example, when pre-training a model to do image classification, the induced features transfer reasonably well to other image classification domains, but also lack certain information such as color or the ability to count that are irrelevant for classification but relevant for e.g. image captioning [4].
例如,当预先训练一个模型进行图像分类时,诱导特征可以很好地转移到其他图像分类领域,但也缺乏某些信息,如颜色或计数能力,这些信息与分类无关,但与图像字幕[4]相关。
(这里存在一个问题,我们只是训练一个特定分类网络,那么我们这个网络虽然也有上采样和下采样过程,但是我们提取的特征其实是不全面的,我们只是提取了我们当前分类任务的特征,很多在其他领域有效果的特征其实就被我们丢弃了。)
Similarly, features that are useful to transcribe human speech may be less suited for speaker identification, or music genre prediction.
类似地,那些对人类语言转录有用的特征可能不太适合于说话者识别或音乐类型预测。
(就是我们使用某种方法提取出来的特征可能领域迁移能力很弱)
Thus, unsupervised learning is an important stepping stone towards robust and generic representation learning.
因此,无监督学习是实现鲁棒性和泛型表征学习的重要跳板。
(就是说鲁棒性的不好的原因是我们在提取特征的过程中,我们无意识的丢弃了一些特征,而无监督能避免这个问题,所以使用无监督能解决这个问题)
第三段(但是现在没有很好的无监督学习方法,也没有办法评估)
Despite its importance, unsupervised learning is yet to see a breakthrough similar to supervised learning: modeling high-level representations from raw observations remains elusive.
尽管它的重要性,非监督学习还没有看到类似于监督学习的突破:从原始观察建模高级表示仍然是难以捉摸的。
(尽管无监督从上面的分析当中可以看出是非常重要的,但是我们还没有有效地从原始观测获得无监督表示特征的方法。)
Further, it is not always clear what the ideal representation is and if it is possible that one can learn such a representation without additional supervision or specialization to a particular data modality.
此外,人们并不总是清楚理想的表示是什么,以及是否有可能在没有额外监督或专门针对特定数据形态的情况下学习这种表示。
第四段(介绍本文提出的方法)
One of the most common strategies for unsupervised learning has been to predict future, missing or contextual information.
最常见的非监督学习策略之一是预测未来、缺失或上下文信息。
This idea of predictive coding [5, 6] is one of the oldest techniques in signal processing for data compression.
这种预测编码的思想[5,6]是信号处理中最古老的数据压缩技术之一。
In neuroscience, predictive coding theories suggest that the brain predicts observations at various levels of abstraction [7, 8].
在神经科学中,预测编码理论认为,大脑在不同的抽象层次上预测观察结果[7,8]。
Recent work in unsupervised learning has successfully used these ideas to learn word representations by predicting neighboring words [9].
最近在无监督学习方面的工作已经成功地使用这些想法通过预测相邻单词[9]来学习单词表示。
For images, predicting color from grey-scale or the relative position of image patches has also beenshown useful [10, 11].
对于图像,从灰度或图像斑块的相对位置预测颜色也被证明是有用的[10,11]。
We hypothesize that these approaches are fruitful partly because the context from which we predict related values are often conditionally dependent on the same shared high-level latent information.
我们假设这些方法是卓有成效的,部分原因是我们预测相关价值的背景往往有条件地依赖于相同的共享的高级潜在信息。
And by casting this as a prediction problem, we automatically infer these features of interest to representation learning.
通过将其作为一个预测问题,我们自动地推断出这些对表征学习感兴趣的特征。
第五段(介绍本文提出的CPC)
In this paper we propose the following: first, we compress high dimensional data into a much more compact latent embedding space in which conditional predictions are easier to model.
本文提出以下建议:
首先,我们将高维数据压缩到一个更紧凑的潜在嵌入空间,在这个空间中条件预测更容易建模。
Secondly, we use powerful autoregressive models in this latent space to make predictions many steps in the future.
之后,我们在这一潜在空间中使用强大的自回归模型对未来的许多步骤进行预测。
Finally, we rely on Noise-Contrastive Estimation [12] for the loss function in similar ways that have been used for learning word embeddings in natural language models, allowing for the whole model to be trained end-to-end.
最后,我们使用与自然语言模型中用于学习单词嵌入的方法类似的方法,依靠噪声对比估计[12]来计算损失函数,从而允许对整个模型进行端到端训练。
We apply the resulting model, Contrastive Predictive Coding (CPC) to
widely different data modalities, images, speech, natural language and reinforcement learning, and show that the same mechanism learns interesting high-level information on each of these domains, outperforming other approaches.
我们将得到的模型,对比预测编码(CPC)应用于不同的数据模式、图像、语音、自然语言和强化学习,表明相同的机制可以在每个领域学习有趣的高级信息,表现优于其他方法。
1.2总结
大约的逻辑是:
- 1.有监督的特征提取已经取得了较好的效果,但是这些特征的鲁棒性或是可泛化能力还有一定的不足。
- 2.作者认为这种不足的原因可能是,我们在特异性标签训练的时候。我们可能只是提取了当前标签领域相关的信息,而丢弃了其他领域的特恒。
- 3.无监督因为没有特定的标签,也就没有特定的领域信息也就更不会产生针对某一个特定领域的迁移的情况,所以避免了这种问题。所以作者提出了使用无监督的方式可以获得更加鲁邦的标签。
- 4.但是现在无监督没有成熟的方法,也没有成熟的评价方式。(这个文章写的时候可能确实是这样的,这个和simCLR、MOCO同时期的,但时这俩都顺利中了,这个文章却被反复拒稿,所以后来在投递的时候,其实对比学习的各种都已经成熟了。)
通过上述的陈述本文作者提出了自己的方法:
- 1.首先,从古老的预测编码技术(压缩当中通过一个位置获得前后的信息)取得灵感,可以通过预测前后的内容获得有效地训练。
- 2.所以作者提出了前后预测的方法。
作者仔细叙述了自己的方法为:
- 1.首先将这些所有的数据压缩在较为紧凑的环境当做,我理解这里可能在一定程度上提升训练效率。
- 2.使用这些得到的信息,预测前后的内容(作者应该是认为,这些前后内容其实有一些)
2 Contrastive Predicting Coding
We start this section by motivating and giving intuitions behind our approach.
我们通过介绍给我们动力和背后只觉得的内容开始本节介绍
Next, we introduce thearchitecture of Contrastive Predictive Coding (CPC).
接下来,我们介绍了对比预测编码(CPC)的体系结构。
After that we explain the loss function that is based on Noise-Contrastive Estimation.
然后,我们解释了基于噪声对比估计的损失函数。
Lastly, we discuss related work to CPC.
最后,对CPC工作进行了探讨。
2.1 Motivation and Intuitions
2.1.1逐句翻译
第一段(这种跨越维度的特征,可能更能反映全局信息,并且很少受到干扰)
The main intuition behind our model is to learn the representations that encode the underlying shared information between different parts of the (high-dimensional) signal.
我们模型背后的主要直觉是学习编码(高维)信号的不同部分之间的底层共享信息的表示。
(就是高维度的信号在底层是有很多共享信息的)
At the same time it discards low-level information and noise that is more local.
同时,它摒弃了低层次的信息和噪音,这是更局部的。
In time series and high-dimensional modeling, approaches that use next step prediction exploit the local smoothness of the signal. When predicting further in the future, the amount of shared information becomes much lower, and the model needs to infer more global structure.
在时间序列和高维建模中,使用下一步预测的方法利用了信号的局部平滑性。在未来进一步预测时,共享的信息量会大大减少,模型需要推断出更多的全局结构。
(因为信号具有局部的平滑性,但是我们在推断出临近的信息可能比较简单,但是如果我们想要推算更加远的信息,就需要掌握更多的全局信息才能完成)
These ’slow features’ [13] that span many time steps are often more interesting (e.g., phonemes and intonation in speech, objects in images, or the story line in books.).
这些跨越多个时间步骤的“慢特征”[13]通常更有趣(例如,语音中的音素和语调,图像中的物体,或书中的故事线)。
(就是这些跨越很长的时间维度的信息往往更加对全局有表现能力)
第二段
One of the challenges of predicting high-dimensional data is that unimodal losses such as meansquared error and cross-entropy are not very useful, and powerful conditional generative models which need to reconstruct every detail in the data are usually required.
预测高维数据的挑战之一是unimodal losses (如均方误差和交叉熵)不是很有用,通常需要重建数据中的每个细节。
But these models are computationally intense, and waste capacity at modeling the complex relationships in the data x, often ignoring the context c.
但这些模型的计算量很大,在建模数据x中的复杂关系时浪费了能力,往往忽略了上下文c。
For example, images may contain thousands of bits of information while the high-level latent variables such as the class label contain much less information (10 bits for 1,024 categories).
例如,图像可能包含数千位信息,而高级潜在变量(如类标签)包含的信息要少得多(10bit他最多包含1024的特征)。
This suggests that modeling p(x|c) directly may not be optimal for the purpose of extracting shared information between x and c.
这表明直接建模p(x|c)对于提取x和c之间的共享信息的目的可能不是最优的。
When predicting future information we instead encode the target x (future) and context c (present) into a compact distributed vector representations (via non-linear learned mappings) in a way that maximally preserves the mutual information of the original signals x and c defined as
当预测未来信息时,我们将目标x(未来)和上下文c(现在)编码成一个紧凑的分布式向量表示(通过非线性学习映射),以最大限度地保留原始信号x和c的相互信息定义为
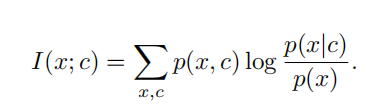
By maximizing the mutual information between the encoded representations (which is bounded by the MI between the input signals), we extract the underlying latent variables the inputs have in commmon.
通过最大限度地提高编码表示之间的相互信息(它以输入信号之间的MI为界),我们提取了输入之间共有的潜在变量。
2.1.2总结
大约就是说夸时间之间是可以提取一些平滑的信息出来的,就是识别一些全局的特征。
2.2 Contrastive Predictive Coding

Figure 1 shows the architecture of Contrastive Predictive Coding models.
图1显示了对比预测编码模型的架构。
第一段(主要是说明当前网络的情况)
First, a non-linear encoder genc maps the input sequence of observations xt to a sequence of latent representations zt = genc(xt), potentially with a lower temporal resolution.
首先,非线性编码器genc将观测数据的输入序列xt映射到潜在表示序列zt = genc(xt),可能具有较低的时间分辨率。
Next, an autoregressive model gar summarizes all z≤t in the latent space and produces a context latent representation ct = gar(z≤t).
然后,一个自回归模型gar总结了所有的z≤t在潜行空间,并产生了上下文潜行表示ct = gar(z≤t)。
3.Experiments
第一段(主要是介绍这些实验都是怎么设计和进行的)
We present benchmarks on four different application domains: speech, images, natural language and reinforcement learning.
我们提出了四个不同应用领域的基准:语音、图像、自然语言和强化学习。
For every domain we train CPC models and probe what the representations contain with either a linear classification task or qualitative evaluations, and in reinforcement learning we measure how the auxiliary CPC loss speeds up learning of the agent.
对于每一个领域,我们训练CPC模型,并通过线性分类任务或定性评估来探索其包含的表示,在强化学习中,我们测量辅助CPC损失如何加速agent的学习。
3.1 Audio(针对音频的测试)
3.1.1 逐句翻译
For audio, we use a 100-hour subset of the publicly available LibriSpeech dataset [30].
对于音频,我们使用公开可用的librisspeech数据集[30]的100小时子集。
Although the dataset does not provide labels other than the raw text, we obtained force-aligned phone sequences
















 4363
4363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











