







文章目录
课堂提问
- Q1: 为什么学习ResNet中学习残差比学习直接映射要好?
- A1: 具体请阅读原论文,但是从直觉上来说,我们直接学习映射,然后网络层堆的越来越多,最后可能太复杂了,但是如果学习残差,则我们加深网络的同时只是学习的残差 F ( X ) = H ( X ) − X F(X)=H(X)-X F(X)=H(X)−X,如果学的过于复杂了,网络只需要学习残差F(X)=0,就可以将其挤掉,即一个恒等映射。
1. LeNet-5
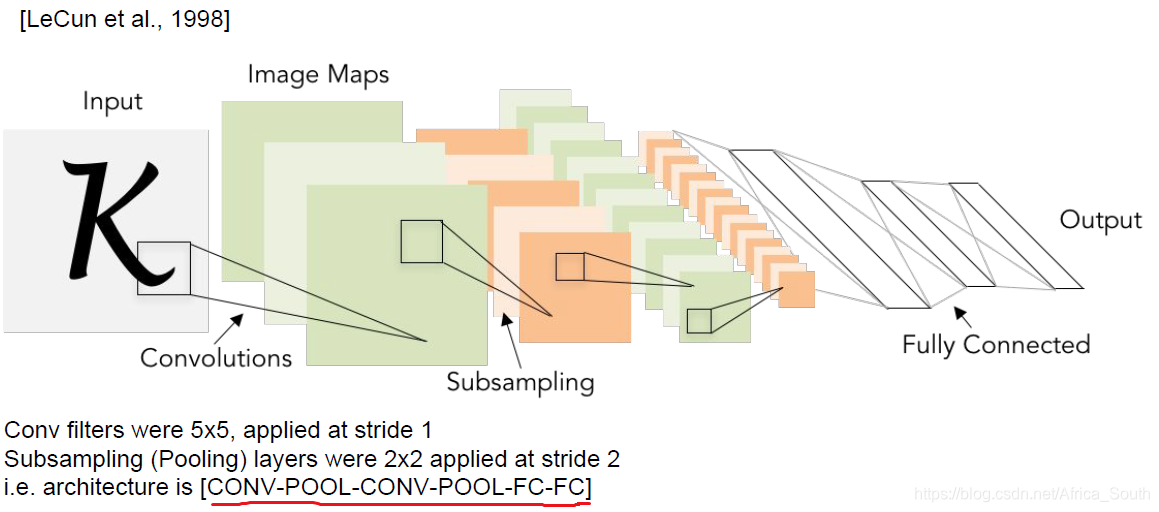
第一次用CNN来做手写体识别,网络比较浅,只有5层。
2. AlexNet

- 其在LeNet上做了一些改进,同时由于当时GPU容量不足,其特征图的前向计算和梯度的反向传播是在两张GPU上并行进行的。
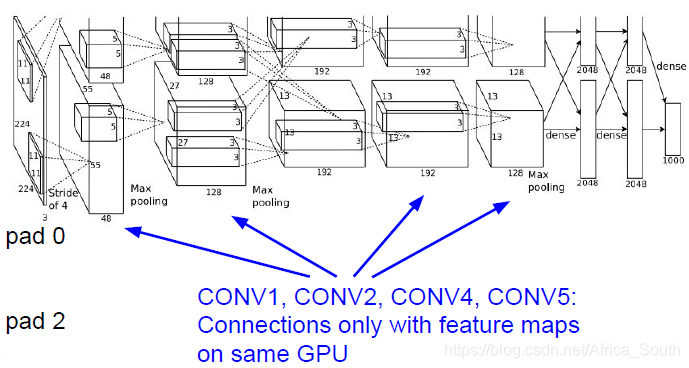
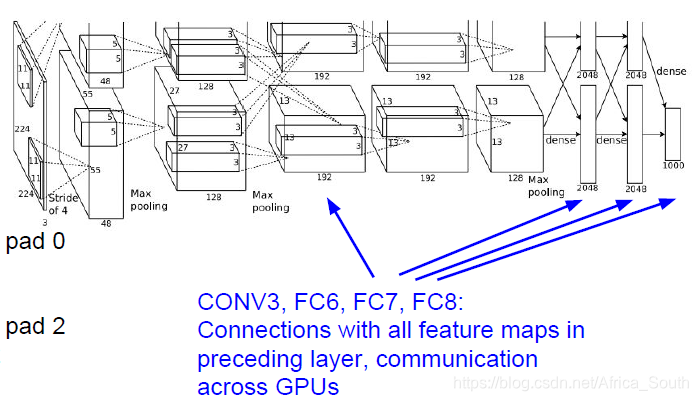
- 其获得了2012年的ImageNet的冠军
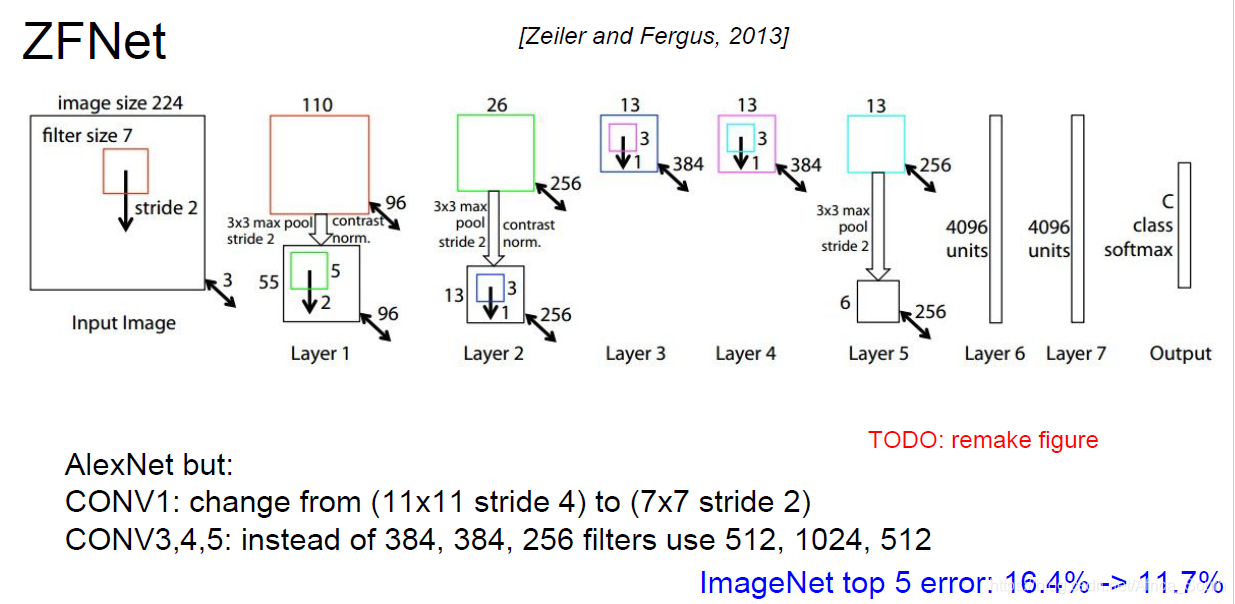
3. ZFNet
- 其在AlexNet上做了一些超参数的优化,但是主要结构还是类似的,获得了2013年的ImageNet的冠军。
4. VGGNet

- 其的关键特点是固定使用 3 ∗ 3 3*3 3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









