







本文提出了三种原型网络的变体,表现超过了原来的原型网络。
变体1: Prototypical networks with soft k-means
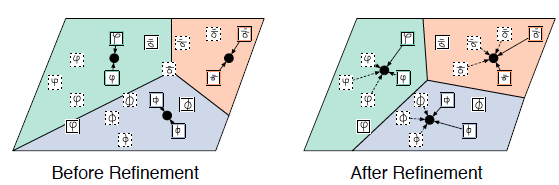
我们不仅有 support set、query set,而且还有一个 unlabeled set。先用 support set 初始化每个类的原型(中心),然后再给 unlabeled set 打上软标签,再重新计算每个类的原型。
类似 k-means 一样,多步迭代,直到中心位置不变。
变体2:Prototypical networks with soft k-means with a distractor cluster
变体1会出现一个现实问题:我们想加一个 unlabeled set,但是去网上下载的图片不可能全是我们想要的这些类别,会出现一些错误样本,对模型造成很大影响。
一个简单的方法就是增加一个错误簇,将这些有问题的样本全部放到这个簇里面,防止它们污染好的分类。
有点像 O 类别,O 类别同样噪音很多,但是通常研究者不会计算 O 的原型。
原型初始化:
p
c
=
{
∑
i
h
(
x
i
)
z
i
,
c
∑
i
z
i
,
c
for
c
=
1
…
N
0
for
c
=
N
+
1
p_{c}= \begin{cases}\frac{\sum_{i} h\left(\boldsymbol{x}_{i}\right) z_{i, c}}{\sum_{i} z_{i, c}} & \text { for } c=1 \ldots N \\ 0 & \text { for } c=N+1\end{cases}
pc={∑izi,c∑ih(xi)zi,c0 for c=1…N for c=N+1
在相似性度量的时候,再加一个距离尺度变量
r
c
r_c
rc,其他簇的距离尺度设置为1,错误簇的距离尺度用来学习:
z
~
j
,
c
=
exp
(
−
1
r
c
2
∥
x
~
j
−
p
c
∥
2
2
−
A
(
r
c
)
)
∑
c
′
exp
(
−
1
r
c
2
∥
x
~
j
−
p
c
′
∥
2
2
−
A
(
r
c
′
)
)
,
where
A
(
r
)
=
1
2
log
(
2
π
)
+
log
(
r
)
\tilde{z}_{j, c}=\frac{\exp \left(-\frac{1}{r_{c}^{2}}\left\|\tilde{x}_{j}-p_{c}\right\|_{2}^{2}-A\left(r_{c}\right)\right)}{\sum_{c^{\prime}} \exp \left(-\frac{1}{r_{c}^{2}}\left\|\tilde{x}_{j}-p_{c^{\prime}}\right\|_{2}^{2}-A\left(r_{c^{\prime}}\right)\right)}, \text { where } A(r)=\frac{1}{2} \log (2 \pi)+\log (r)
z~j,c=∑c′exp(−rc21∥x~j−pc′∥22−A(rc′))exp(−rc21∥x~j−pc∥22−A(rc)), where A(r)=21log(2π)+log(r)
变体3:Prototypical networks with soft k-means and masking
变体2想法过于简单,错误簇可能包含的错误样本并可能不是同一个类别,将它们放到一起并不合适。那么这个变体将错误簇去掉了,用另一种方式,选择性的将 unlabeled sample 加入到簇中。
首先还是一样,用 support set 计算每个类的原型
p
c
p_c
pc。对于一个 unlabeled sample,计算 sample 到每个原型的距离
d
~
j
,
c
\tilde d_{j,c}
d~j,c:
d
~
j
,
c
=
d
j
,
c
1
M
∑
j
d
j
,
c
,
where
d
j
,
c
=
∥
h
(
x
~
j
)
−
p
c
∥
2
2
\tilde{d}_{j, c}=\frac{d_{j, c}}{\frac{1}{M} \sum_{j} d_{j, c}}, \text { where } d_{j, c}=\left\|h\left(\tilde{x}_{j}\right)-p_{c}\right\|_{2}^{2}
d~j,c=M1∑jdj,cdj,c, where dj,c=∥h(x~j)−pc∥22
然后将
d
~
j
,
c
\tilde d_{j,c}
d~j,c 放入到一个MLP(masked language model)中,计算make的阈值
β
c
β_c
βc 和斜率
γ
c
γ_c
γc:
[
β
c
,
γ
c
]
=
MLP
(
[
min
j
(
d
~
j
,
c
)
,
max
j
(
d
~
j
,
c
)
,
var
j
(
d
~
j
,
c
)
,
skew
j
(
d
~
j
,
c
)
,
kurt
j
(
d
~
j
,
c
)
]
)
\left[\beta_{c}, \gamma_{c}\right]=\operatorname{MLP}\left(\left[\min _{j}\left(\tilde{d}_{j, c}\right), \max _{j}\left(\tilde{d}_{j, c}\right), \operatorname{var}_{j}\left(\tilde{d}_{j, c}\right), \operatorname{skew}_{j}\left(\tilde{d}_{j, c}\right), \operatorname{kurt}_{j}\left(\tilde{d}_{j, c}\right)\right]\right)
[βc,γc]=MLP([jmin(d~j,c),jmax(d~j,c),varj(d~j,c),skewj(d~j,c),kurtj(d~j,c)])
最后根据阈值和斜率,计算 mask 概率,然后重新更新原型,
σ
(
)
σ()
σ()是 sigmoid 函数。
p
~
c
=
∑
i
h
(
x
i
)
z
i
,
c
+
∑
j
h
(
x
~
j
)
z
~
j
,
c
m
j
,
c
∑
i
z
i
,
c
+
∑
j
z
~
j
,
c
m
j
,
c
,
where
m
j
,
c
=
σ
(
−
γ
c
(
d
~
j
,
c
−
β
c
)
)
\tilde{p}_{c}=\frac{\sum_{i} h\left(\boldsymbol{x}_{i}\right) z_{i, c}+\sum_{j} h\left(\tilde{\boldsymbol{x}}_{j}\right) \tilde{z}_{j, c} m_{j, c}}{\sum_{i} z_{i, c}+\sum_{j} \tilde{z}_{j, c} m_{j, c}}, \text { where } m_{j, c}=\sigma\left(-\gamma_{c}\left(\tilde{d}_{j, c}-\beta_{c}\right)\right)
p~c=∑izi,c+∑jz~j,cmj,c∑ih(xi)zi,c+∑jh(x~j)z~j,cmj,c, where mj,c=σ(−γc(d~j,c−βc))
结果
- Supervised:原始的原型网络
- Semi-Supervised Inference:带有 soft k-means的原型网络,但是只迭代一次计算中心

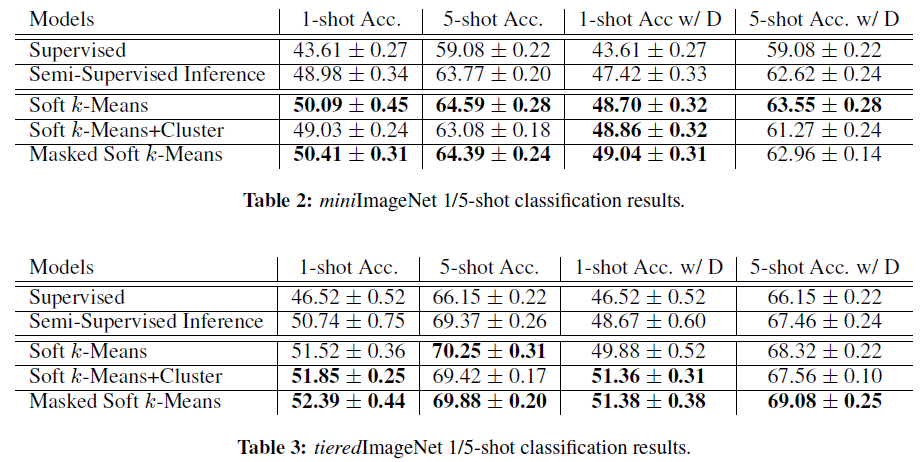
实验结果可以看到,效果都超出原来的原型网络。















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









