






一、ollama
1.1 docker 方式
1.1.1 ollama启动
(1)拉取镜像
docker pull ollama/ollama
(2)启动
docker run -d --restart=always --gpus=all -v /home/docker/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# -v 是存储挂载,之后你使用ollama下载的模型权重都会保存早本地/home/docker/ollama路径下
(3)启动完成后,您可以通过访问 http://<您的IP地址>:11434/api/tags 来查看当前已下载的大模型列表。同时,通过访问 http://<您的IP地址>:11434/api/version 可以获取当前安装的 Ollama 版本信息。
请注意:
- 在上述 URL 中,请将 <您的IP地址> 替换为您实际的服务器 IP 地址或域名。
- 对于 Ollama 0.3.0 及以上版本,用户能够配置更多的高级选项,如多并发处理能力和模型后台运行的最大时长等。这些功能可以通过执行特定的命令来实现。
curl http://ip:11434/api/generate -d '{"model":"qwen2:7b","keep_alive": -1}'
# 将qwen2:7b模型一直保持在后台
1.1.2 Open WebUI
(1)拉取 Open WebUI 镜像
docker pull openwebui/open-webui
(2)运行 Open WebUI 服务
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
(3)访问 Open WebUI
打开浏览器,访问 http://ip:8080就能打开以上页面了。
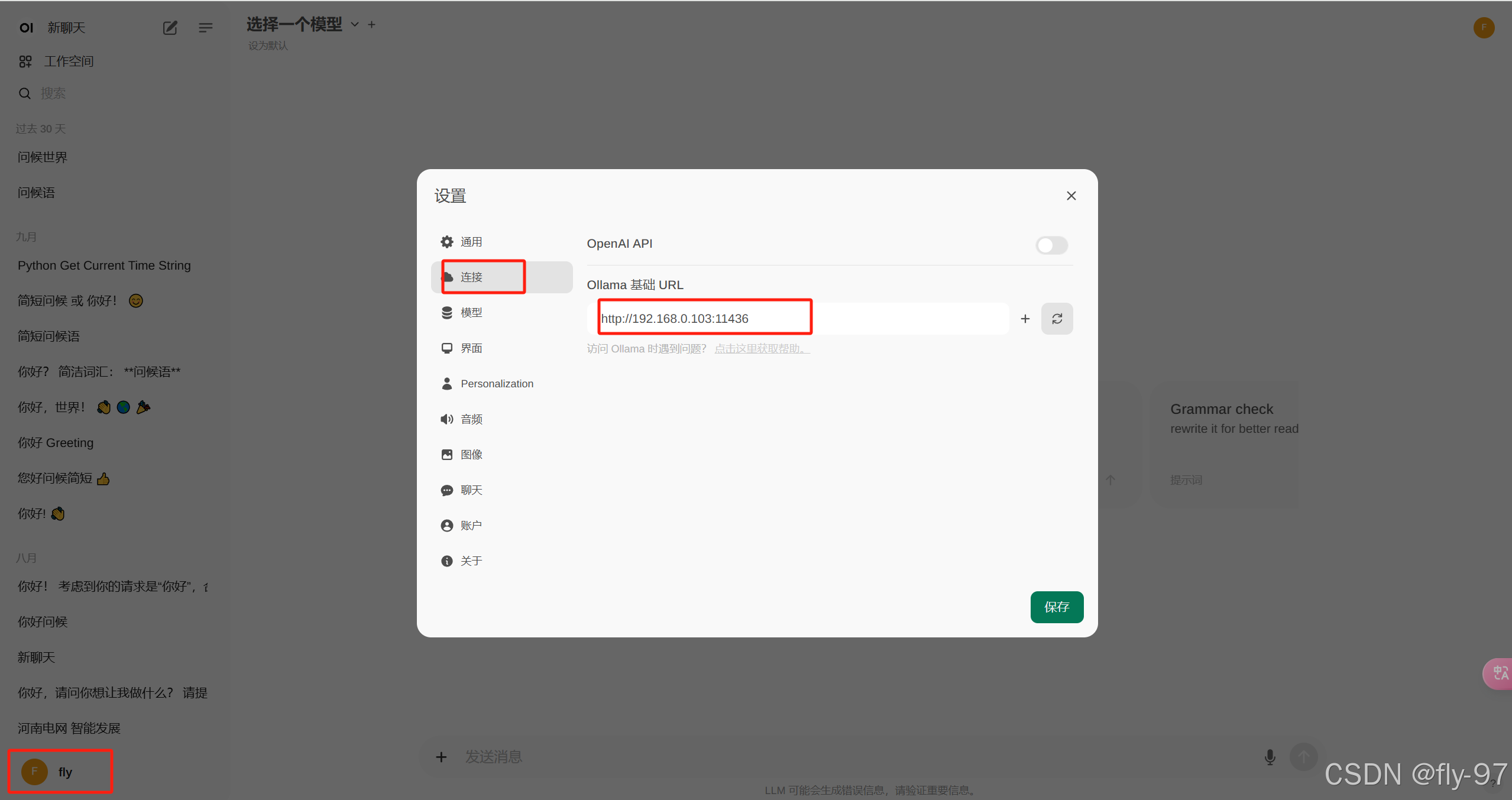
这个是配置刚刚ollama的服务,保存之后就可以在下面的模型模块看到已有的模型
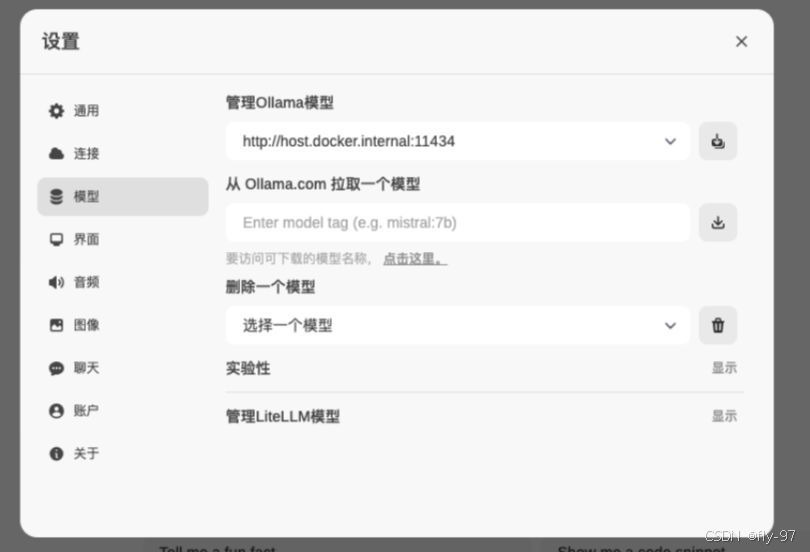
在模型管理模块中,您可以下载所需的模型(请注意,模型名称必须准确无误)。为了方便查找和选择合适的模型,您可以访问 Ollama 模型库。
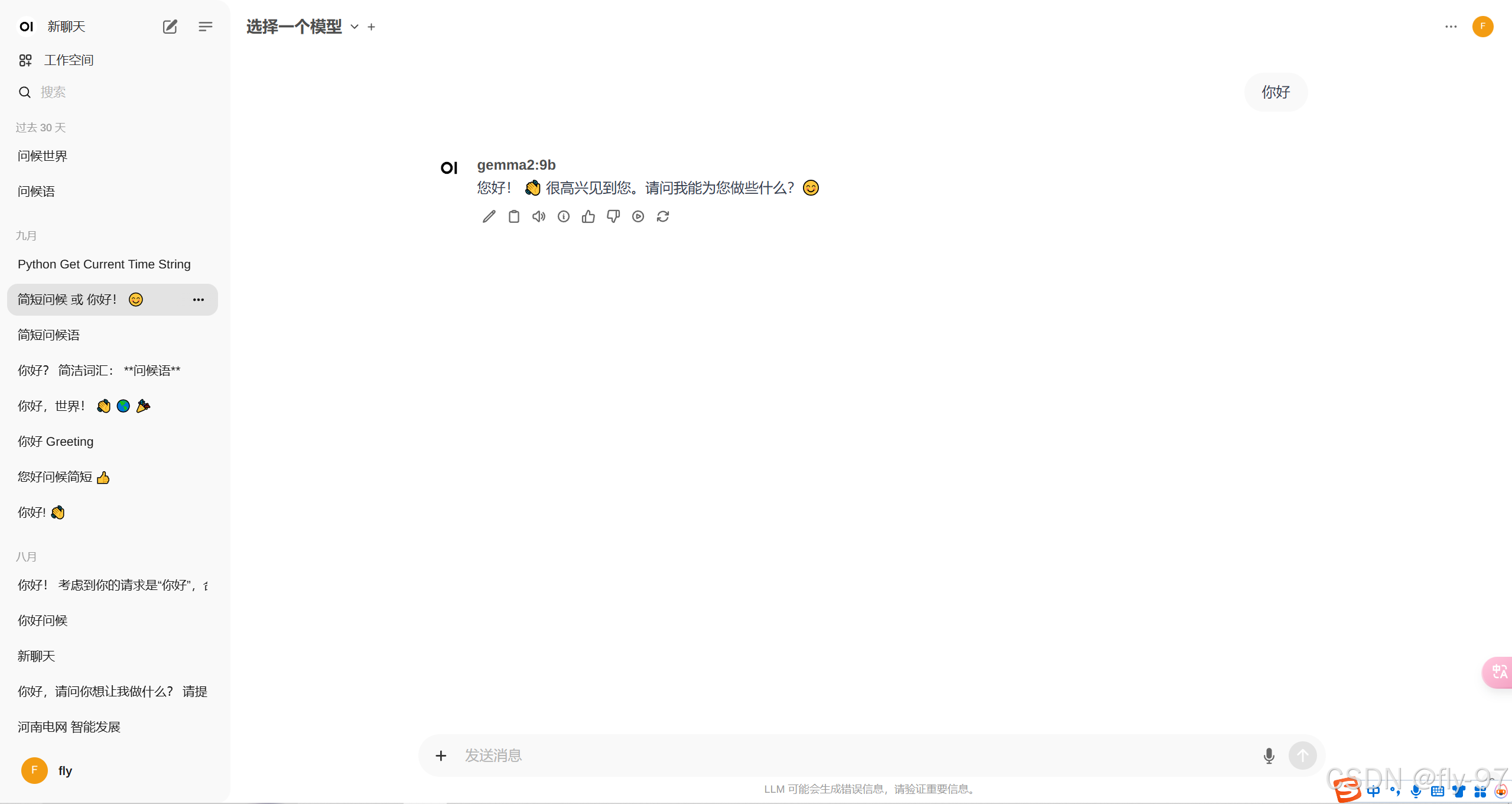
完成模型下载后,您就可以开始与模型进行对话了。如果您想探索更多功能,建议搜索有关 Open WebUI 的使用教程,那里有详细的指南和技巧可以帮助您更好地利用这一工具。
二、huggingface、modelscope
2.1 huggingface方式
Hugging Face 是一个非常流行的开源平台,提供了大量的预训练模型和工具,使得开发者和研究人员可以轻松地使用和微调各种深度学习模型。本文将介绍如何在 Hugging Face 上运行大模型,并提供一些实用的技巧和注意事项。
前提条件:
(1)Python:建议使用 Python 3.7 或更高版本。
(2)Transformers 库:这是 Hugging Face 提供的核心库,包含了大量预训练模型。
(3)Torch 或 TensorFlow:根据您的需求选择其中一个深度学习框架。
由于官网需要科学上网的方式才能访问,所以推荐使用国内的镜像 https://hf-mirror.com
对应的每个大模型下都会有如何调用的方法:

代码默认的是使用官网下载大模型,我们可以直接使用以上的镜像网址在网页上进行下载
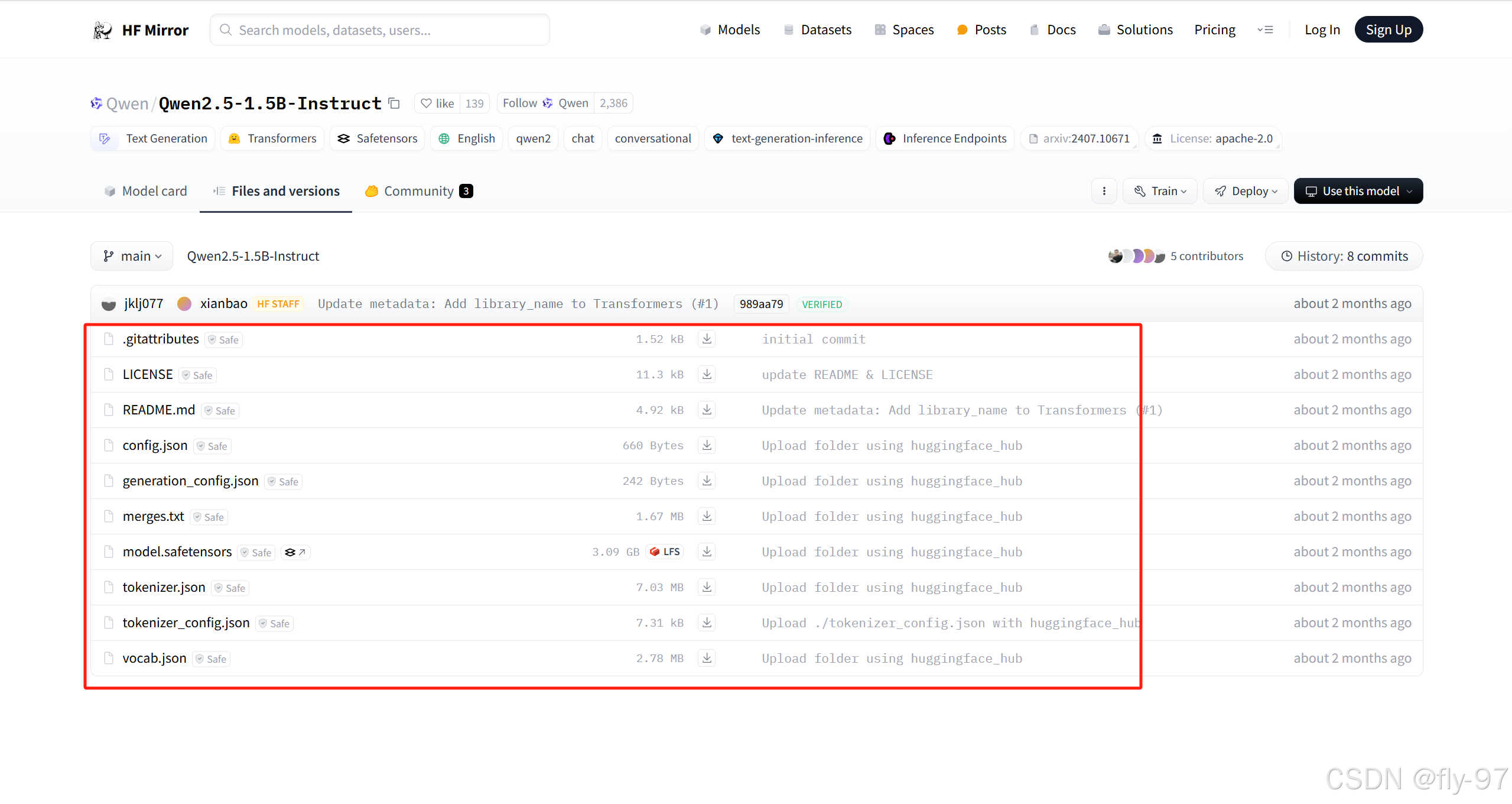
还有一种方式,直接使用命令的形式下载,配置方法如下
pip install -U huggingface_hub
pip install huggingface-cli
export HF_ENDPOINT=https://hf-mirror.com # 配置加速镜像
huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B-Instruct --local-dir /home/models/Qwen2.5-1.5B-Instruct
2.2 modelscope方式
modelscope也是一个模型库,和huggingface的区别就是,modelscope是国内开发的,模型没有huggingface全面,但是大模型都会有。
使用方法一致,官网提供了调用方法
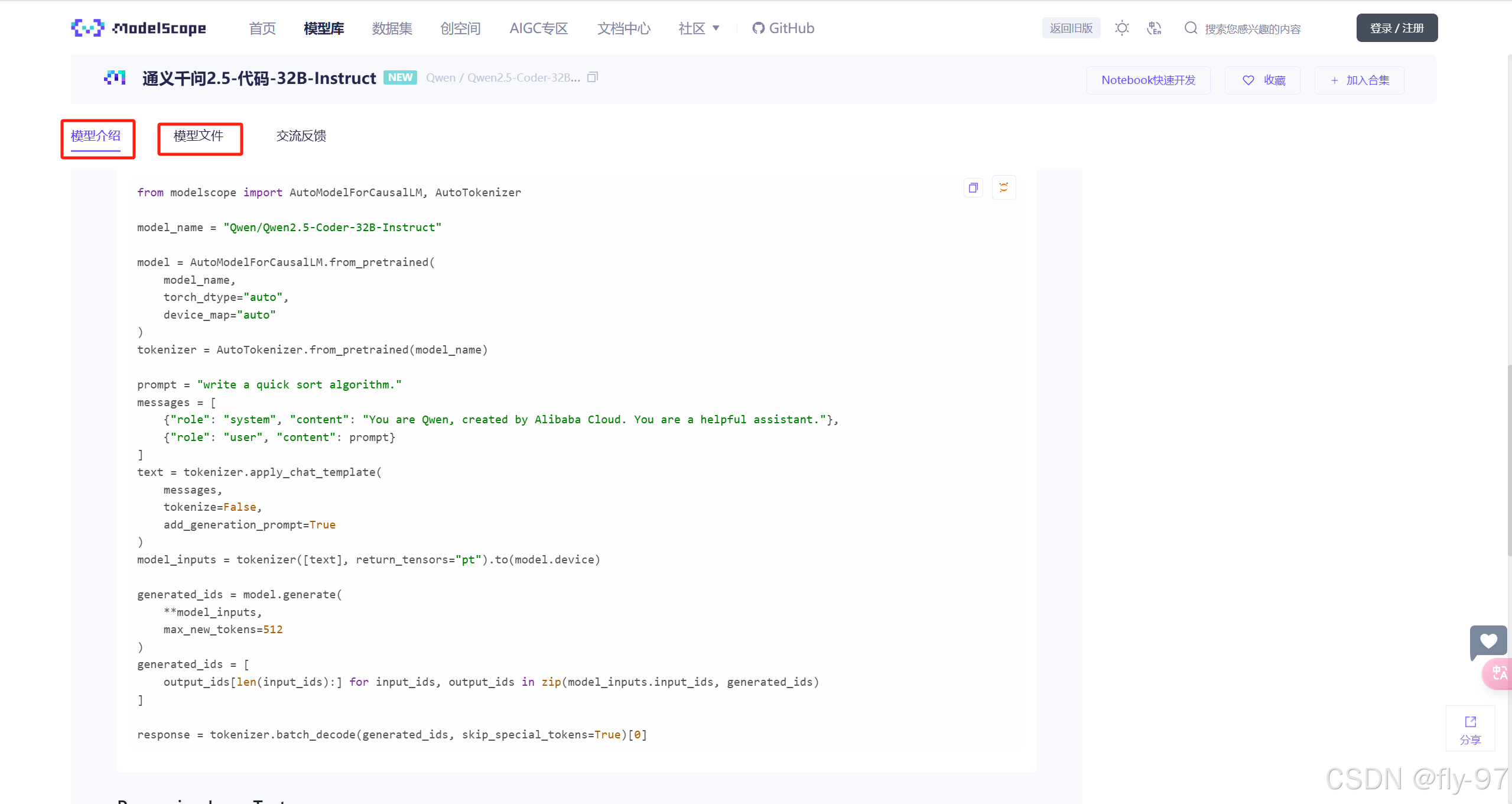
三、vllm
vllm 是一个用于高效运行和微调大型语言模型的框架。它提供了强大的功能和灵活的接口,使得开发者和研究人员可以轻松地管理和使用各种大模型。本文将详细介绍如何使用 VLLM 运行大模型,并提供一些实用的技巧和注意事项。
(1)配置环境
vllm对环境要求比较高,需要高版本的cuda(12以上),以下是我之前文章的片段:

(2)模型下载
使用 2.1 的方式下载想要运行的模型。
(3)运行
- 使用命令的形式运行启动大模型服务
vllm serve Qwen/Qwen2.5-1.5B-Instruct --trust-remote-code
python -m vllm.entrypoints.api_server --model <model_name_or_path>
python -m vllm.entrypoints.api_server --model gpt2 --host 0.0.0.0 --port 8080 --tensor-parallel-size 2
出现显卡精度与模型不对应时可以使用 --dtype half 来支撑
调用
import requests
import json
# Endpoint URL
url = "http://localhost:8000/v1/chat/completions"
# Headers
headers = {
"Content-Type": "application/json",
}
# Payload
payload = {
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell about Bitcoin."},
],
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"stream": False,
"max_tokens": 2048,
"stop": None,
"frequency_penalty": 0,
"presence_penalty": 0,
"temperature": 0.6,
"top_p": 0.90
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
result = response.json()
content = result['choices'][0]['message']['content']
print(content)
- 使用代码的形式运行
from vllm import LLM, SamplingParams
def generate_text(model_path, prompts):
"""
使用 vllm 从指定模型生成文本
:param model_path: 模型的路径或名称
:param prompts: 用于生成文本的提示列表
:return: 生成的文本结果
"""
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.8, # 控制生成文本的随机性,值越大越随机
top_p=0.95, # 采样时考虑的概率阈值
max_tokens=256 # 生成的最大 token 数量
)
try:
# 创建 LLM 对象,指定模型路径、数据类型、GPU 内存利用率和最大模型长度
llm = LLM(
model=model_path,
dtype='half', # 使用 float16 数据类型,避免 Bfloat16 不支持的问题
gpu_memory_utilization=0.9, # 提高 GPU 内存利用率
max_model_len=51424 # 限制最大模型长度以适应 KV 缓存
)
# 调用生成方法
outputs = llm.generate(prompts, sampling_params)
# 处理生成的结果
results = []
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
result = {
"prompt": prompt,
"generated_text": generated_text
}
results.append(result)
return results
except Exception as e:
print(f"生成文本时出现错误: {e}")
return []
if __name__ == "__main__":
# 示例提示列表
sample_prompts = [
"介绍一下人工智能的发展历程",
"推荐几部经典的科幻电影",
"简述中国古代四大发明的意义"
]
# 替换为你实际的模型路径或名称
model_path = "/home/ws/store/zhx/pre_model/DeepSeek-R1-Distill-Qwen-1.5B"
# 调用生成函数
generated_results = generate_text(model_path, sample_prompts)
# 打印生成的结果
for result in generated_results:
print(f"提示: {result['prompt']}")
print(f"生成的文本: {result['generated_text']}")
print("-" * 50)
- 代码启动服务
from vllm.entrypoints.api_server import app
import uvicorn
if __name__ == "__main__":
model_name = "gpt2"
# 配置参数
config = {
"model": model_name,
"host": "0.0.0.0",
"port": 8080,
"tensor_parallel_size": 2
}
uvicorn.run(app, **config)

















 5095
5095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









