






模 型 融 合 概 述 模型融合概述 模型融合概述
模型融合有几大缺点:
1.预测时间长
2.工程上实现麻烦
3.准确率提高不大,时间却过长
在工程上进行模型融合,需要考虑:
1.稳定
2.预测时间
3.部署

推荐系统版(模型融合):

集成学习:

对方差和偏差的理解很重要



Error = Bias + Variance
Error:反映的是整个模型的准确度,
Bias:反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,
Variance:反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
bias: 描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单
讲,就是在样本上拟合的好不好。要想在bias. 上表现好,low bias,就得复杂化模型,增加模型
的参数,但这样容易过拟合(overfiting),过拟合对应上图是high variance,点很分散。low
bias对应就是点都打在靶心附近,所以瞄的是准的,但手不一定稳。
varience: 描述的是样本上训练出来的模型在测试集_上的表现,要想在variance.上表现好,
low varience,就要简化模型,减少模型的参数,但这样容易欠拟合(unfitting),欠拟合对应上
图是high bias,点偏离中心。low variance对应就是点都打的很集中,但不一定是靶心附近,手
很稳,但是瞄的不准。
方差在图中显示的就是聚集程度
偏差在图中显示的就是离目标的偏离程度
1.Bagging


Bootstrap


Bagging主要就是用来降低方差的,所以一般要选择偏差小的模型,因为Bagging不怎么降低bias
(所以还有Boosting的模型融合,这个就主要可以降低bias)
随机森林:在里面的每棵树中,抽取的数据集和选择的特征量都会不同,所以很降低variance
Boosting

残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 我们可以将残差看作误差的观测值。

难样本再学习
经典案例:focus__loss
Bleeding

预测值如果加上原始值,会使模型更加稳定
Stacking

5折交叉验证:即把数据集分成5份,4份作为训练,1份作为验证(预测)
转载于(推荐阅读):
https://zhuanlan.zhihu.com/p/61705517
https://blog.csdn.net/u011630575/article/details/81302994
https://www.zhihu.com/question/27068705
偏差(Bias)和方差(Variance)——机器学习中的模型选择
融合模型是提升机器学习的有效办法,无论是学习、竞赛、工作无处不在,应是算法学习者必会的知识技能。
常见的集成学习&模型融合方法包括:
Voting/Averaging(分别对于分类和回归问题)
Stacking
Boosting
Bagging
Linear Blending
Voting/Averaging
在不改变模型的情况下,直接对各个不同的模型预测的结果,进行投票或者平均,这是一种简单却行之有效的融合方式。
比如对于分类问题,假设有三个相互独立的模型,每个正确率都是70%,采用少数服从多数的方式进行投票。那么最终的正确率将是:
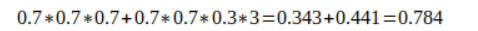
即结果经过简单的投票,使得正确率提升了8%。这是一个简单的概率学问题——如果进行投票的模型越多,那么显然其结果将会更好。但是其前提条件是模型之间相互独立,结果之间没有相关性。越相近的模型进行融合,融合效果也会越差。
可见模型之间差异越大,融合所得的结果将会更好。//这种特性不会受融合方式的影响。
对于回归问题,对各种模型的预测结果进行平均,所得到的结果通过能够减少过拟合,并使得边界更加平滑,单个模型的边界可能很粗糙。这是很直观的性质,如下图。

在上述融合方法的基础上,一个进行改良的方式是对各个投票者/平均者分配不同的权重以改变其对最终结果影响的大小。对于正确率低的模型给予更低的权重,而正确率更高的模型给予更高的权重。这也是可以直观理解的——想要推翻专家模型(高正确率模型)的唯一方式,就是臭皮匠模型(低正确率模型)同时投出相同选项的反对票。具体的对于权重的赋值,可以用正确率排名的正则化等。
这种方法看似简单,但是却是各种“高级”方法的基础。















 3668
3668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









