






模 型 融 合 实 例 简 介 模型融合实例简介 模型融合实例简介
数据集:链接:https://pan.baidu.com/s/1KVRkkRp-E-W0tS4Q9qU7Ag 提取码:a9wl
1.导入数据包
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
2.读取数据
df_data = pd.read_csv('./heart.csv')
3.查看数据
df_data

4.简单统计
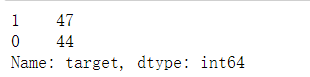
df_data.target.value_counts()

5.缺失值填充
df_data = df_data.fillna(0) # 补全为0 的影响不会很大,除了类似于线性回归的迭代类型模型
6.切分数据集
features_name = [columns_name for columns_name in df_data.columns if columns_name not in ['target']]
7.数据预处理
7.1 独热化
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.get_dummies.html
# pd.get_dummies(df)
7.2 标准化
标准化的流程简单来说可以表达为:将数据按其属性(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split # 数据划分
stdScaler = StandardScaler()
X = stdScaler.fit_transform(df_data[features_name])
X_train_scaler,X_test_scaler,y_train_scaler,y_test_scaler = train_test_split(X,df_data['target'],test_size=0.3, random_state=0)
7.3非标准化
X_train,X_test,y_train,y_test = train_test_split(df_data[features_name],df_data['target'],test_size=0.3, random_state=0)
y_test_scaler.value_counts()
X_train_scaler.shape
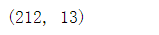
8.训练模型
8.1 LR模型
from sklearn.linear_model import LogisticRegression
# 标准化
clf = LogisticRegression().fit(X_train_scaler, y_train_scaler)
clf.score(X_test_scaler, y_test_scaler)
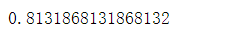
# 非标准化
clf = LogisticRegression().fit(X_train, y_train)
clf.score(X_test, y_test)
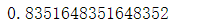
8.2 KNN 模型
from sklearn.neighbors import KNeighborsClassifier
# 标准化
clf = KNeighborsClassifier(n_neighbors=3).fit(X_train_scaler, y_train_scaler)
clf.score(X_test_scaler, y_test_scaler)
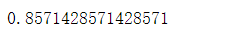
8.3 GaussianNB 模型
from sklearn.naive_bayes import GaussianNB
# 标准化
clf = GaussianNB().fit(X_train, y_train)
clf.score(X_test, y_test)
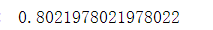
8.4Tree树模型
from sklearn.tree import DecisionTreeClassifier
# 标准化
clf = DecisionTreeClassifier().fit(X_train, y_train)
clf.score(X_test, y_test)

8.5 bagging模型
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
# 标准化
clf = BaggingClassifier(KNeighborsClassifier(), max_samples=0.5, max_features=0.5).fit(X_train, y_train)
clf.score(X_test, y_test)
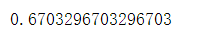
8.6 随机森林
from sklearn.ensemble import RandomForestClassifier
# 标准化
clf = RandomForestClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0).fit(X_train, y_train)
clf.score(X_test, y_test)
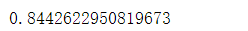
8.7 ExTree模型
from sklearn.ensemble import ExtraTreesClassifier
# 标准化
clf = ExtraTreesClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0).fit(X_train, y_train)
clf.score(X_test, y_test)
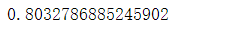
8.8 AdaBoost模型
from sklearn.ensemble import AdaBoostClassifier
# 标准化
clf = AdaBoostClassifier(n_estimators=100).fit(X_train, y_train)
clf.score(X_test, y_test)
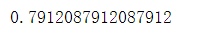
8.9 GBDT模型
from sklearn.ensemble import GradientBoostingClassifier
# 标准化
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0).fit(X_train, y_train)
clf.score(X_test, y_test)
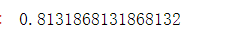
9 模型融合
9.1 模型投票
投票的模型融合需要去除 单模型效果不好的,因为投票模型融合改善的是variance ,对偏差降的低,所以单模型差的会拉低融合模型
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(df_data[features_name])
y = df_data['target']
clf1 = GaussianNB()
clf2 = DecisionTreeClassifier()
clf3 = KNeighborsClassifier(n_neighbors=3)
eclf = VotingClassifier(estimators=[('lr', clf1), ('tree', clf2), ('knn', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['GaussianNB', 'DecisionTreeClassifier', 'KNeighborsClassifier', 'Ensemble']):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %0.5f (+/- %0.5f) [%s]" % (scores.mean(), scores.std(), label))

lgb 模型
import lightgbm
X_train, X_test, y_train, y_test = train_test_split(df_data[features_name], df_data['target'], test_size=0.4, random_state=0)
X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5, random_state=0)
clf = lightgbm
train_matrix = clf.Dataset(X_train, label=y_train)
test_matrix = clf.Dataset(X_test, label=y_test)
params = {
# 这些参数需要学习
'boosting_type': 'gbdt',
#'boosting_type': 'dart',
'objective': 'multiclass',
'metric': 'multi_logloss', # 评测函数,这个比较重要
'min_child_weight': 1.5,
'num_leaves': 2**5,
'lambda_l2': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'tree_method': 'exact',
'seed': 2020,
'learning_rate': 0.01, # 学习率 重要
'num_class': 2, # 重要
'silent': True,
}
num_round = 400 # 训练的轮数
early_stopping_rounds = 10
model = clf.train(params,
train_matrix,
num_round,
valid_sets=test_matrix,
early_stopping_rounds=early_stopping_rounds)
pre= model.predict(X_valid,num_iteration=model.best_iteration)

print('score : ', np.mean((pre[:,1]>0.5)==y_valid))
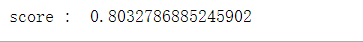
xgb 模型
import xgboost
X_train, X_test, y_train, y_test = train_test_split(df_data[features_name], df_data['target'], test_size=0.4, random_state=0)
X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5, random_state=0)
clf = xgboost
train_matrix = clf.DMatrix(X_train, label=y_train, missing=-1)
test_matrix = clf.DMatrix(X_test, label=y_test, missing=-1)
z = clf.DMatrix(X_valid, label=y_valid, missing=-1)
params = {'booster': 'gbtree',
'objective': 'multi:softprob',
'eval_metric': 'mlogloss',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.3,
'tree_method': 'exact',
'seed': 2017,
"num_class": 2
}
num_round = 200 # 重要
# 通过设置参数 early_stopping_rounds 来解决因为迭代次数过多而过拟合的状态
# 设置early_stopping_rounds=10,当验证loss在10轮迭代之内,都没有提升的话,就stop
early_stopping_rounds = 10 # 重要
watchlist = [(train_matrix, 'train'),
(test_matrix, 'eval')
]
model = clf.train(params,
train_matrix,
num_boost_round=num_round,
evals=watchlist,
early_stopping_rounds=early_stopping_rounds
)
pre = model.predict(z,ntree_limit=model.best_ntree_limit)
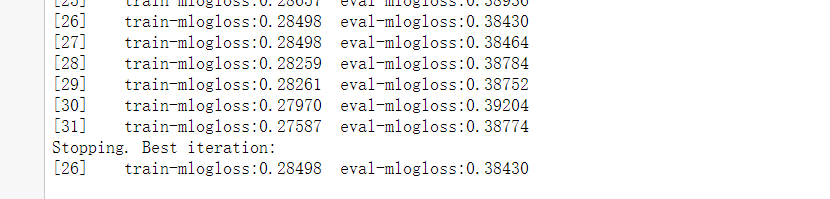
print('score : ', np.mean((pre[:,1]>0.5)==y_valid))
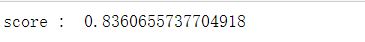
Stacking,Bootstrap,Bagging技术实践
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
class SBBTree():
"""
SBBTree
Stacking,Bootstap,Bagging
"""
def __init__(
self,
params,
stacking_num,
bagging_num,
bagging_test_size,
num_boost_round,
early_stopping_rounds
):
"""
Initializes the SBBTree.
Args:
params : lgb params.
stacking_num : k_flod stacking.
bagging_num : bootstrap num.
bagging_test_size : bootstrap sample rate.
num_boost_round : boost num.
early_stopping_rounds : early_stopping_rounds.
"""
self.params = params
self.stacking_num = stacking_num
self.bagging_num = bagging_num
self.bagging_test_size = bagging_test_size
self.num_boost_round = num_boost_round
self.early_stopping_rounds = early_stopping_rounds
self.model = lgb
self.stacking_model = []
self.bagging_model = []
def fit(self, X, y):
""" fit model. """
if self.stacking_num > 1:
layer_train = np.zeros((X.shape[0], 2))
self.SK = StratifiedKFold(n_splits=self.stacking_num, shuffle=True, random_state=1)
for k,(train_index, test_index) in enumerate(self.SK.split(X, y)):
X_train = X[train_index]
y_train = y[train_index]
X_test = X[test_index]
y_test = y[test_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(self.params,
lgb_train,
num_boost_round=self.num_boost_round,
valid_sets=lgb_eval,
early_stopping_rounds=self.early_stopping_rounds)
self.stacking_model.append(gbm)
pred_y = gbm.predict(X_test, num_iteration=gbm.best_iteration)
layer_train[test_index, 1] = pred_y
X = np.hstack((X, layer_train[:,1].reshape((-1,1))))
else:
pass
for bn in range(self.bagging_num):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=self.bagging_test_size, random_state=bn)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(self.params,
lgb_train,
num_boost_round=self.num_boost_round,
valid_sets=lgb_eval,
early_stopping_rounds=self.early_stopping_rounds)
self.bagging_model.append(gbm)
def predict(self, X_pred):
""" predict test data. """
if self.stacking_num > 1:
test_pred = np.zeros((X_pred.shape[0], self.stacking_num))
for sn,gbm in enumerate(self.stacking_model):
pred = gbm.predict(X_pred, num_iteration=gbm.best_iteration)
test_pred[:, sn] = pred
X_pred = np.hstack((X_pred, test_pred.mean(axis=1).reshape((-1,1))))
else:
pass
for bn,gbm in enumerate(self.bagging_model):
pred = gbm.predict(X_pred, num_iteration=gbm.best_iteration)
if bn == 0:
pred_out=pred
else:
pred_out+=pred
return pred_out/self.bagging_num
"""
TEST CODE
"""
from sklearn.datasets import make_classification
from sklearn.datasets import load_breast_cancer
from sklearn.datasets import make_gaussian_quantiles
from sklearn import metrics
from sklearn.metrics import f1_score
# X, y = make_classification(n_samples=1000, n_features=25, n_clusters_per_class=1, n_informative=15, random_state=1)
X, y = make_gaussian_quantiles(mean=None, cov=1.0, n_samples=1000, n_features=50, n_classes=2, shuffle=True, random_state=2)
# data = load_breast_cancer()
# X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 9,
'learning_rate': 0.03,
'feature_fraction_seed': 2,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'min_data': 20,
'min_hessian': 1,
'verbose': -1,
'silent': 0
}
# test 1
model = SBBTree(params=params, stacking_num=5, bagging_num=1, bagging_test_size=0.33, num_boost_round=300, early_stopping_rounds=10)
model.fit(X,y)
X_pred = X[0].reshape((1,-1))
pred=model.predict(X_pred)
print('pred')
print(pred)
print('TEST 1 ok')
# test 1
model = SBBTree(params, stacking_num=5, bagging_num=1, bagging_test_size=0.33, num_boost_round=300, early_stopping_rounds=10)
model.fit(X_train,y_train)
pred1=model.predict(X_test)
# test 2
model = SBBTree(params, stacking_num=5, bagging_num=3, bagging_test_size=0.33, num_boost_round=300, early_stopping_rounds=10)
model.fit(X_train,y_train)
pred2=model.predict(X_test)
# test 3
model = SBBTree(params, stacking_num=5, bagging_num=1, bagging_test_size=0.33, num_boost_round=300, early_stopping_rounds=10)
model.fit(X_train,y_train)
pred3=model.predict(X_test)
# test 4
model = SBBTree(params, stacking_num=5, bagging_num=3, bagging_test_size=0.33, num_boost_round=300, early_stopping_rounds=10)
model.fit(X_train,y_train)
pred4=model.predict(X_test)
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred1, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred2, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred3, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred4, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))

实战
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 9,
'learning_rate': 0.33, # 0.3 、 0.01
'feature_fraction_seed': 2,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'min_data': 20,
'min_hessian': 1,
'verbose': -1,
'silent': 0
}
model = SBBTree(params=params,
stacking_num=5,
bagging_num=3,
bagging_test_size=0.33,
num_boost_round=200,
early_stopping_rounds=20)
X_train, X_test, y_train, y_test = train_test_split(df_data[features_name], df_data['target'], test_size=0.4, random_state=0)
model.fit(X_train.values, y_train.values)
pred = model.predict(X_test.values)

print('score : ', np.mean((pred>0.5)==y_test))















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









