






深度分割模型比赛训练技巧示例
main.py
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model
from major_optimizer import fetch_scheduler
from major_TrainAndVal import run_trainingAndvaliding
from major_loss import criterion
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
CFG.train_groups = ["kidney_1_dense", "kidney_3_dense"]
CFG.valid_groups = [ "kidney_2"]
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# 判断是否是Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs*5]
train_msk_paths = train_msk_paths[:CFG.train_bs*5]
valid_img_paths = valid_img_paths[:CFG.valid_bs*3]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs*3]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
'''
三 构建模型
'''
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load("best_epoch.bin"))
'''
四 损失函数
'''
criterion = criterion
'''
五 评估函数
'''
# from major_eval import dice_coef,iou_coef
#
# dice_coef = dice_coef
# iou_coef = iou_coef
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 训练和验证
model, history = run_trainingAndvaliding(model=model,
optimizer=optimizer,
train_loader=train_loader,
valid_loader=valid_loader,
scheduler=scheduler,
criterion=criterion,
device=CFG.device,
num_epochs=CFG.epochs)
# 提交
major_config.py
import torch
import albumentations as A
import cv2
class CFG:
seed = 42
debug = False # set debug=False for Full Training
exp_name = 'baseline'
comment = 'unet-efficientnet_b1-512x512'
output_dir = './'
model_name = 'Unet'
backbone = 'timm-efficinet-b5' # se_resnext50_32x4d
train_bs = 10
valid_bs = 16
img_size = [1024, 1024]
epochs = 20
n_accumulate = max(1, 64 // train_bs)
lr = 2e-3
scheduler = 'CosineAnnealingLR'
min_lr = 1e-6
T_max = int(2279 / (train_bs * n_accumulate) * epochs) + 50
T_0 = 25
warmup_epochs = 0
wd = 1e-6
n_fold = 5
num_classes = 1
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
gt_df = "./gt.csv"
data_root = r"D:\Kaggle_3DSeg"
train_groups = ["kidney_1_dense","kidney_1_voi","kidney_2","kidney_3_dense","kidney_3_sparse"]
valid_groups = ["kidney_1_dense","kidney_1_voi","kidney_2","kidney_3_dense","kidney_3_sparse"]
loss_func = "DiceLoss"
# 前处理
data_transforms = {
"train": A.Compose([
A.Resize(*img_size, interpolation=cv2.INTER_NEAREST),
A.HorizontalFlip(p=0.5),
], p=1.0),
"valid": A.Compose([
A.Resize(*img_size, interpolation=cv2.INTER_NEAREST),
], p=1.0)
}
major_BuildModel.py
import segmentation_models_pytorch as smp
from major_config import CFG
def build_model(backbone, num_classes, device):
print("encoder Name: ", backbone)
model = smp.Unet(
encoder_name=backbone, # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization
in_channels=3, # model input channels (1 for gray-scale images, 3 for RGB, etc.)
classes=num_classes, # model output channels (number of classes in your dataset)
activation=None,
)
model.to(device)
return model
def build_model_vit(backbone, num_classes, device):
print("encoder Name: ",backbone)
model = smp.Unet(
encoder_name=backbone, # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization
in_channels=3, # model input channels (1 for gray-scale images, 3 for RGB, etc.)
classes=num_classes, # model output channels (number of classes in your dataset)
activation=None,
)
model.to(device)
return model
if __name__ == '__main__':
CFG.backbone = "mit_b2"
model = build_model_vit(CFG.backbone, CFG.num_classes, CFG.device)
major_dataset.py
import torch
from major_utils import load_img,load_msk
import numpy as np
class BuildDataset(torch.utils.data.Dataset):
def __init__(self, img_paths, msk_paths=[], transforms=None):
self.img_paths = img_paths
self.msk_paths = msk_paths
self.transforms = transforms
def __len__(self):
return len(self.img_paths)
def __getitem__(self, index):
img_path = self.img_paths[index]
img = load_img(img_path)
if len(self.msk_paths) > 0:
msk_path = self.msk_paths[index]
msk = load_msk(msk_path)
if self.transforms:
data = self.transforms(image=img, mask=msk)
img = data['image']
msk = data['mask']
img = np.transpose(img, (2, 0, 1))
return torch.tensor(img), torch.tensor(msk)
else:
orig_size = img.shape
if self.transforms:
data = self.transforms(image=img)
img = data['image']
img = np.transpose(img, (2, 0, 1))
return torch.tensor(img), torch.tensor(np.array([orig_size[0], orig_size[1]]))
major_eval.py
import torch
def dice_coef(y_true, y_pred, thr=0.5, dim=(2,3), epsilon=0.001):
y_true = y_true.unsqueeze(1).to(torch.float32)
y_pred = (y_pred>thr).to(torch.float32)
inter = (y_true*y_pred).sum(dim=dim)
den = y_true.sum(dim=dim) + y_pred.sum(dim=dim)
dice = ((2*inter+epsilon)/(den+epsilon)).mean(dim=(1,0))
return dice
def iou_coef(y_true, y_pred, thr=0.5, dim=(2,3), epsilon=0.001):
y_true = y_true.unsqueeze(1).to(torch.float32)
y_pred = (y_pred>thr).to(torch.float32)
inter = (y_true*y_pred).sum(dim=dim)
union = (y_true + y_pred - y_true*y_pred).sum(dim=dim)
iou = ((inter+epsilon)/(union+epsilon)).mean(dim=(1,0))
return iou
major_loss.py
from major_config import CFG
import segmentation_models_pytorch as smp
DiceLoss = smp.losses.DiceLoss(mode='binary')
BCELoss = smp.losses.SoftBCEWithLogitsLoss()
def criterion(y_pred, y_true):
if CFG.loss_func == "DiceLoss":
return DiceLoss(y_pred, y_true)
elif CFG.loss_func == "BCELoss":
y_true = y_true.unsqueeze(1)
return BCELoss(y_pred, y_true)
major_optimizer.py
from major_config import CFG
from torch.optim import lr_scheduler
def fetch_scheduler(optimizer):
if CFG.scheduler == 'CosineAnnealingLR':
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=CFG.T_max,
eta_min=CFG.min_lr)
elif CFG.scheduler == 'CosineAnnealingWarmRestarts':
scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=CFG.T_0,
eta_min=CFG.min_lr)
elif CFG.scheduler == 'ReduceLROnPlateau':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer,
mode='min',
factor=0.1,
patience=7,
threshold=0.0001,
min_lr=CFG.min_lr, )
elif CFG.scheduer == 'ExponentialLR':
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.85)
elif CFG.scheduler == None:
return None
return scheduler
major_postProcess.py
在这里插入代码片
major_predict.py
import cv2
import pandas as pd
from torch.utils.data import DataLoader
from tqdm import tqdm
import torch
from major_config import CFG
from major_utils import rle_encode
from major_dataset import BuildDataset
import numpy as np
import torch.nn as nn
from major_BuildModel import build_model
import os
from glob import glob
from tqdm import tqdm
import matplotlib.pyplot as plt
from PIL import Image
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# valid_img_paths =[]
# for root, dirs, files in os.walk(r"D:\Kaggle_3DSeg\blood-vessel-segmentation\test"):
# for idx, file in enumerate(tqdm(files)):
# valid_img_paths.append(os.path.join(root,file).replace('\\','/'))
test_dataset = BuildDataset(valid_img_paths, [], transforms=CFG.data_transforms['valid'])
test_loader = DataLoader(test_dataset, batch_size=1, num_workers=0, shuffle=True, pin_memory=True)
pbar = tqdm(enumerate(test_loader), total=len(test_loader), desc='Inference ')
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load("best_epoch.bin"))
for step, (images, shapes) in pbar:
shapes = shapes.numpy()
images = images.to(CFG.device, dtype=torch.float)
with torch.no_grad():
preds = model(images)
preds = (nn.Sigmoid()(preds)>0.5).double()
preds = preds.cpu().numpy().astype(np.uint8)
pre = preds[0][0]*255
img = Image.fromarray(pre)
img.show()
major_prepocess.py
major_submit.py
import cv2
import pandas as pd
from torch.utils.data import DataLoader
from tqdm import tqdm
import torch
from major_config import CFG
from major_utils import rle_encode
from major_dataset import BuildDataset
import numpy as np
import torch.nn as nn
from major_BuildModel import build_model
import os
from glob import glob
from tqdm import tqdm
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
valid_img_paths =[]
for root, dirs, files in os.walk(r"D:\Kaggle_3DSeg\blood-vessel-segmentation\test"):
for idx, file in enumerate(tqdm(files)):
valid_img_paths.append(os.path.join(root,file).replace('\\','/'))
#
# submission = pd.DataFrame.from_dict({
# "id": "ids",
# "rle": "rles"
# })
# submission.head()
test_dataset = BuildDataset(valid_img_paths, [], transforms=CFG.data_transforms['valid'])
test_loader = DataLoader(test_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
### Inference
rles = []
pbar = tqdm(enumerate(test_loader), total=len(test_loader), desc='Inference ')
CFG.backbone = "efficientnet-b1"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
# model.load_state_dict(torch.load("best_epoch.bin"))
#
rles = []
for step, (images, shapes) in pbar:
shapes = shapes.numpy()
images = images.to(CFG.device, dtype=torch.float)
with torch.no_grad():
preds = model(images)
preds = (nn.Sigmoid()(preds)>0.5).double()
preds = preds.cpu().numpy().astype(np.uint8)
for pred, shape in zip(preds, shapes):
pred = cv2.resize(pred[0], (shape[1], shape[0]), cv2.INTER_NEAREST)
rle = rle_encode(pred)
rles.append(rle)
ids =[f'{p.split("/")[-3]}_{os.path.basename(p).split(".")[0]}' for p in valid_img_paths]
submission = pd.DataFrame.from_dict({
"id": ids,
"rle": rles
})
submission.head()
submission.to_csv('submission.csv', index=False)
major_TrainAndVal.py
from tqdm import tqdm
import torch
from major_config import CFG
import time
from torch.cuda import amp
import torch.nn as nn
import gc
import numpy as np
import copy
from collections import defaultdict
from major_eval import dice_coef,iou_coef
from colorama import Fore, Back, Style
from torch.cuda.amp import autocast
c_ = Fore.GREEN
sr_ = Style.RESET_ALL
def train_one_epoch(model, criterion,optimizer, scheduler, dataloader, device, epoch):
model.train()
scaler = amp.GradScaler()
dataset_size = 0
running_loss = 0.0
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Train ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
y_pred = model(images)
loss = criterion(y_pred, masks)
loss = loss / CFG.n_accumulate
scaler.scale(loss).backward()
if (step + 1) % CFG.n_accumulate == 0:
scaler.step(optimizer)
scaler.update()
# zero the parameter gradients
optimizer.zero_grad()
if scheduler is not None:
scheduler.step()
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(epoch=f'{epoch}',
train_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_mem=f'{mem:0.2f} GB')
torch.cuda.empty_cache()
gc.collect()
return epoch_loss
@torch.no_grad()
def valid_one_epoch(model, dataloader,criterion, optimizer,device, epoch):
model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
y_pred = model(images)
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
@torch.no_grad()
def valid_one_epoch_MultiModel(model_list, dataloader,criterion, optimizer,device, epoch):
# model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
# y_pred = model(images)
preds_1 = model_list[0](images)
preds_2 = model_list[1](images)
y_pred = 0.7*preds_1 + 0.3*preds_2
# preds = (preds>0.3).double()
#
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
@torch.no_grad()
def valid_one_epoch_MultiModel2(model_list, dataloader,criterion, optimizer,device, epoch):
# model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
preds_1 = model_list[0](images)
preds_2 = model_list[1](images)
preds_3 = model_list[2](images)
preds_4 = model_list[3](images)
preds_5 = model_list[4](images)
y_pred = preds_1+preds_2+preds_3+preds_4+preds_5
# y_pred = model(images)
# preds_1 = model_list[0](images)
# preds_2 = model_list[1](images)
# y_pred = 0.7*preds_1 + 0.3*preds_2
# preds = (preds>0.3).double()
#
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
def run_trainingAndvaliding(model, optimizer,train_loader, valid_loader,scheduler, criterion, device, num_epochs):
if torch.cuda.is_available():
print("cuda: {}\n".format(torch.cuda.get_device_name()))
start = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = np.inf
best_epoch = -1
history = defaultdict(list)
for epoch in range(1, num_epochs + 1):
gc.collect()
print(f'Epoch {epoch}/{num_epochs}', end='')
# 训练
train_loss = train_one_epoch(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
dataloader=train_loader,
device=CFG.device,
epoch=epoch)
# 验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=epoch)
val_dice, val_jaccard = val_scores
history['Train Loss'].append(train_loss)
history['Valid Loss'].append(val_loss)
history['Valid Dice'].append(val_dice)
history['Valid Jaccard'].append(val_jaccard)
print(f'Valid Dice: {val_dice:0.4f} | Valid Jaccard: {val_jaccard:0.4f}')
print(f'Valid Loss: {val_loss}')
# deep copy the model
if val_loss <= best_loss:
print(f"{c_}Valid loss Improved ({best_loss} ---> {val_loss})")
best_dice = val_dice
best_jaccard = val_jaccard
best_loss = val_loss
best_epoch = epoch
best_model_wts = copy.deepcopy(model.state_dict())
PATH = "best_epoch.bin"
# 保存模型的完整训练信息
torch.save(model.module.state_dict(),
f"./{CFG.backbone}_{best_epoch}_loss{best_loss:.2f}_score{best_dice:.2f}_val_loss{best_loss:.2f}_val_score{best_dice:.2f}.pt")
torch.save(model.state_dict(), PATH)
print(f"Model Saved{sr_}")
last_model_wts = copy.deepcopy(model.state_dict())
PATH = "last_epoch.bin"
torch.save(model.state_dict(), PATH)
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}h {:.0f}m {:.0f}s'.format(
time_elapsed // 3600, (time_elapsed % 3600) // 60, (time_elapsed % 3600) % 60))
print("Best Loss: {:.4f}".format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model, history
def run_trainingAndvaliding_KFold(model, optimizer, train_loader, valid_loader, scheduler, criterion, device, num_epochs,K_Fold=0):
if torch.cuda.is_available():
print("cuda: {}\n".format(torch.cuda.get_device_name()))
start = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = np.inf
best_epoch = -1
history = defaultdict(list)
for epoch in range(1, num_epochs + 1):
gc.collect()
print(f'Epoch {epoch}/{num_epochs}', end='')
# 训练
train_loss = train_one_epoch(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
dataloader=train_loader,
device=CFG.device,
epoch=epoch)
# 验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=epoch)
val_dice, val_jaccard = val_scores
history['Train Loss'].append(train_loss)
history['Valid Loss'].append(val_loss)
history['Valid Dice'].append(val_dice)
history['Valid Jaccard'].append(val_jaccard)
print(f'Valid Dice: {val_dice:0.4f} | Valid Jaccard: {val_jaccard:0.4f}')
print(f'Valid Loss: {val_loss}')
# deep copy the model
if val_loss <= best_loss:
print(f"{c_}Valid loss Improved ({best_loss} ---> {val_loss})")
best_dice = val_dice
best_jaccard = val_jaccard
best_loss = val_loss
best_epoch = epoch
best_model_wts = copy.deepcopy(model.state_dict())
PATH = f"{CFG.backbone}_best_epoch.bin"
# 保存模型的完整训练信息
torch.save(model.state_dict(),
f"./{CFG.backbone}_{best_epoch}_loss{best_loss:.2f}_score{best_dice:.2f}_val_loss{best_loss:.2f}_val_score{best_dice:.2f}_{K_Fold}_Fold.pt")
torch.save(model.state_dict(), PATH)
print(f"Model Saved{sr_}")
last_model_wts = copy.deepcopy(model.state_dict())
PATH = f"{CFG.backbone}_last_epoch.bin"
torch.save(model.state_dict(), PATH)
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}h {:.0f}m {:.0f}s'.format(
time_elapsed // 3600, (time_elapsed % 3600) // 60, (time_elapsed % 3600) % 60))
print("Best Loss: {:.4f}".format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model, history
major_utils.py
import numpy as np
import torch
import os
import random
import cv2
import matplotlib.pyplot as plt
from major_config import CFG
def set_seed(seed = 42):
'''Sets the seed of the entire notebook so results are the same every time we run.
This is for REPRODUCIBILITY.'''
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
# When running on the CuDNN backend, two further options must be set
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# Set a fixed value for the hash seed
os.environ['PYTHONHASHSEED'] = str(seed)
def load_img(path):
img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
#print(path)
img = np.tile(img[...,None], [1, 1, 3]) # gray to rgb
img = img.astype('float32') # original is uint16
mx = np.max(img)
if mx:
img/=mx # scale image to [0, 1]
return img
def load_msk(path):
msk = cv2.imread(path, cv2.IMREAD_UNCHANGED)
msk = msk.astype('float32')
msk/=255.0
return msk
def rle_encode(img):
'''
img: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels = img.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
rle = ' '.join(str(x) for x in runs)
if rle=='':
rle = '1 0'
return rle
# def rle_encode(mask):
# pixel = mask.flatten()
# pixel = np.concatenate([[0], pixel, [0]])
# run = np.where(pixel[1:] != pixel[:-1])[0] + 1
# run[1::2] -= run[::2]
# rle = ' '.join(str(r) for r in run)
# if rle == '':
# rle = '1 0'
# return rle
def showData(train_img_paths,train_df,train_dataset):
sample_ids = [random.randint(0, len(train_img_paths)) for _ in range(5)]
for sample_id in sample_ids:
data_name = train_df.loc[sample_id]["id"]
img, msk = train_dataset[sample_id]
img = img.permute((1, 2, 0)).numpy() * 255.0
img = img.astype('uint8')
msk = (msk * 255).numpy().astype('uint8')
plt.figure(figsize=(9, 4))
print(data_name)
plt.axis('off')
plt.subplot(1, 3, 1)
plt.imshow(img)
plt.subplot(1, 3, 2)
plt.imshow(msk)
plt.subplot(1, 3, 3)
plt.imshow(img, cmap='bone')
plt.imshow(msk, alpha=0.5)
plt.show()
def showLR(train_loader,_optimizer,_scheduler):
lr_list = []
for e in range(CFG.epochs):
for step in range(len(train_loader)):
lr_list.append(_optimizer.param_groups[0]['lr'])
if (step + 1) % CFG.n_accumulate == 0:
_optimizer.step()
_scheduler.step()
plt.plot(np.array(range(len(lr_list))), np.array(lr_list))
plt.show()
major_valid.py
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model,build_model_vit
from major_optimizer import fetch_scheduler
from major_TrainAndVal import valid_one_epoch,valid_one_epoch_MultiModel2,valid_one_epoch_MultiModel
from major_loss import criterion
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = True
CFG.train_groups = ["kidney_1_dense", "kidney_3_dense"]
CFG.valid_groups = [ "kidney_2"]
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# 判断是否是Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs*50]
train_msk_paths = train_msk_paths[:CFG.train_bs*50]
valid_img_paths = valid_img_paths[:CFG.valid_bs*30]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs*30]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
model_list = []
'''
三 构建模型
'''
model_1_path = "se_resnext50_32x4d_20_loss0.13_score0.87_val_loss0.13_val_score0.87_4_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
'''
四 损失函数
'''
criterion = criterion
'''
五 评估函数
'''
# from major_eval import dice_coef,iou_coef
#
# dice_coef = dice_coef
# iou_coef = iou_coef
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 训练和验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
# 提交
model_1_path = "se_resnext50_32x4d_19_loss0.11_score0.89_val_loss0.11_val_score0.89_3_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
model_1_path = "se_resnext50_32x4d_16_loss0.12_score0.88_val_loss0.12_val_score0.88_2_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
model_1_path = "se_resnext50_32x4d_19_loss0.08_score0.92_val_loss0.08_val_score0.92_1_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
model_1_path = "se_resnext50_32x4d_15_loss0.26_score0.64_val_loss0.26_val_score0.64_0_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
# model_1_path = "se_resnext50_32x4d_6_loss0.15_score0.80_val_loss0.15_val_score0.80_0_Fold.pt"
# CFG.backbone = "se_resnext50_32x4d"
#
# model_1 = build_model(CFG.backbone, CFG.num_classes, CFG.device)
# model_1 = DataParallel(model_1)
# model_1.load_state_dict(torch.load(model_1_path))
#
#
# model_2_path = "mit_b1_6_loss0.24_score0.70_val_loss0.24_val_score0.70_0_Fold.pt"
# CFG.backbone = "mit_b1"
# model_2 = build_model_vit(CFG.backbone, CFG.num_classes, CFG.device)
# model_2 = DataParallel(model_2)
# model_2.load_state_dict(torch.load(model_2_path))
#
# model_list= [model_1,model_2]
val_loss, val_scores = valid_one_epoch_MultiModel2(model_list=model_list,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
计算数据集的均值和方差
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from major_config import CFG
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
import numpy as np
import torch
from tqdm import tqdm
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
calculate_mead_std_imgPath = gt_df["img_path"].values.tolist()
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
calculate_mead_std_maskPath = gt_df["msk_path"].values.tolist()
if CFG.debug:
calculate_mead_std_imgPath = calculate_mead_std_imgPath[:100]
calculate_mead_std_maskPath = calculate_mead_std_maskPath[:100]
# 验证集
# 图像预处理
valid_dataset = BuildDataset(calculate_mead_std_imgPath, calculate_mead_std_maskPath, transforms=CFG.data_transforms['valid'])
valid_loader = DataLoader(valid_dataset, batch_size=1000, num_workers=0, shuffle=False, pin_memory=True)
pbar = tqdm(enumerate(valid_loader), total=len(valid_loader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(CFG.device, dtype=torch.float)
train_mean = np.mean(images.cpu().numpy(), axis=(0, 2, 3))
train_std = np.std(images.cpu().numpy(), axis=(0, 2, 3))
print("train_mean:",train_mean)
print("train_std:",train_std)
# train_mean: [0.5785608 0.5785608 0.5785608]
# train_std: [0.12644446 0.12644446 0.12644446]
# train_mean: [0.56037647 0.56037647 0.56037647]
# train_std: [0.12725429 0.12725429 0.12725429]
ResNext模型训练.py
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model
from major_optimizer import fetch_scheduler
from major_TrainAndVal import run_trainingAndvaliding_KFold
from major_loss import criterion
from sklearn.model_selection import StratifiedKFold
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
'''
StratifiedKFold函数是从sklearn模块中导出的函数,
StratifiedKFold函数采用分层划分的方法(分层随机抽样思想),验证集中不同类别占比与原始样本的比例保持一致,
故StratifiedKFold在做划分的时候需要传入标签特征。
'''
kf = StratifiedKFold(n_splits=5)
fold_idx = 0
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = True
CFG.train_bs = 12
CFG.valid_bs = 12
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
for train_idx, val_idx in kf.split(gt_df["img_path"], gt_df["group"]):
train_df = gt_df.iloc[train_idx]
valid_df = gt_df.iloc[val_idx]
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs * 50]
train_msk_paths = train_msk_paths[:CFG.train_bs * 50]
valid_img_paths = valid_img_paths[:CFG.valid_bs * 25]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs * 25]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
'''
三 构建模型
'''
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load("se_resnext50_32x4d_6_loss0.15_score0.80_val_loss0.15_val_score0.80_0_Fold.pt"))
'''
四 损失函数
'''
criterion = criterion
'''
五 评估函数
'''
# from major_eval import dice_coef,iou_coef
#
# dice_coef = dice_coef
# iou_coef = iou_coef
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 训练和验证
model, history = run_trainingAndvaliding_KFold(model=model,
optimizer=optimizer,
train_loader=train_loader,
valid_loader=valid_loader,
scheduler=scheduler,
criterion=criterion,
device=CFG.device,
num_epochs=CFG.epochs,
K_Fold= fold_idx)
fold_idx=fold_idx+1
# 提交
VIT模型训练.py
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model_vit
from major_optimizer import fetch_scheduler
from major_TrainAndVal import run_trainingAndvaliding_KFold
from major_loss import criterion
from sklearn.model_selection import StratifiedKFold
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
'''
StratifiedKFold函数是从sklearn模块中导出的函数,
StratifiedKFold函数采用分层划分的方法(分层随机抽样思想),验证集中不同类别占比与原始样本的比例保持一致,
故StratifiedKFold在做划分的时候需要传入标签特征。
'''
kf = StratifiedKFold(n_splits=5)
fold_idx = 0
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
CFG.train_bs = 8
CFG.valid_bs = 24
CFG.epochs = 30
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
for train_idx, val_idx in kf.split(gt_df["img_path"], gt_df["group"]):
train_df = gt_df.iloc[train_idx]
valid_df = gt_df.iloc[val_idx]
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs * 5]
train_msk_paths = train_msk_paths[:CFG.train_bs * 5]
valid_img_paths = valid_img_paths[:CFG.valid_bs * 3]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs * 3]
train_img_paths = train_img_paths[:CFG.train_bs * 5]
train_msk_paths = train_msk_paths[:CFG.train_bs * 5]
valid_img_paths = train_img_paths[:CFG.train_bs * 5]
valid_msk_paths = train_msk_paths[:CFG.train_bs * 5]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
'''
三 构建模型
'''
CFG.backbone = "mit_b1"
model = build_model_vit(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load("mit_b1_6_loss0.24_score0.70_val_loss0.24_val_score0.70_0_Fold.pt"))
'''
四 损失函数
'''
criterion = criterion
'''
五 评估函数
'''
# from major_eval import dice_coef,iou_coef
#
# dice_coef = dice_coef
# iou_coef = iou_coef
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 训练和验证
model, history = run_trainingAndvaliding_KFold(model=model,
optimizer=optimizer,
train_loader=train_loader,
valid_loader=valid_loader,
scheduler=scheduler,
criterion=criterion,
device=CFG.device,
num_epochs=CFG.epochs,
K_Fold= fold_idx)
fold_idx=fold_idx+1
# 提交
VIT2模型训练.py
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model,build_model_vit
from major_optimizer import fetch_scheduler
from major_TrainAndVal import run_trainingAndvaliding
from major_loss import criterion
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
CFG.train_groups = ["kidney_1_dense", "kidney_3_dense","kidney_1_voi","kidney_2","kidney_3_sparse"]
CFG.valid_groups = ["kidney_1_dense", "kidney_3_dense","kidney_1_voi","kidney_2","kidney_3_sparse"]
CFG.train_bs = 10
CFG.valid_bs = 16
CFG.img_size = [1024, 1024]
CFG.epochs = 200
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# 判断是否是Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs*5]
train_msk_paths = train_msk_paths[:CFG.train_bs*5]
valid_img_paths = valid_img_paths[:CFG.valid_bs*3]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs*3]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
'''
三 构建模型
'''
CFG.backbone = "mit_b1"
model = build_model_vit(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load("mit_b1_11_loss0.12_score0.86_val_loss0.12_val_score0.86.pt"))
model = DataParallel(model)
'''
四 损失函数
'''
criterion = criterion
'''
五 评估函数
'''
# from major_eval import dice_coef,iou_coef
#
# dice_coef = dice_coef
# iou_coef = iou_coef
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 训练和验证
model, history = run_trainingAndvaliding(model=model,
optimizer=optimizer,
train_loader=train_loader,
valid_loader=valid_loader,
scheduler=scheduler,
criterion=criterion,
device=CFG.device,
num_epochs=CFG.epochs)
# 提交
单模型五折训练.py
from tqdm import tqdm
import torch
from major_config import CFG
import time
from torch.cuda import amp
import torch.nn as nn
import gc
import numpy as np
import copy
from collections import defaultdict
from major_eval import dice_coef,iou_coef
from colorama import Fore, Back, Style
from sklearn.model_selection import StratifiedKFold
'''
StratifiedKFold函数是从sklearn模块中导出的函数,
StratifiedKFold函数采用分层划分的方法(分层随机抽样思想),验证集中不同类别占比与原始样本的比例保持一致,
故StratifiedKFold在做划分的时候需要传入标签特征。
'''
kf = StratifiedKFold(n_splits=5)
fold_idx = 0
c_ = Fore.GREEN
sr_ = Style.RESET_ALL
def run_trainingAndvaliding_5Fold(model, optimizer,train_loader, valid_loader,scheduler, criterion, device, num_epochs):
if torch.cuda.is_available():
print("cuda: {}\n".format(torch.cuda.get_device_name()))
start = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = np.inf
best_epoch = -1
history = defaultdict(list)
for epoch in range(1, num_epochs + 1):
gc.collect()
print(f'Epoch {epoch}/{num_epochs}', end='')
# 训练
train_loss = train_one_epoch(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
dataloader=train_loader,
device=CFG.device,
epoch=epoch)
# 验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=epoch)
val_dice, val_jaccard = val_scores
history['Train Loss'].append(train_loss)
history['Valid Loss'].append(val_loss)
history['Valid Dice'].append(val_dice)
history['Valid Jaccard'].append(val_jaccard)
print(f'Valid Dice: {val_dice:0.4f} | Valid Jaccard: {val_jaccard:0.4f}')
print(f'Valid Loss: {val_loss}')
# deep copy the model
if val_loss <= best_loss:
print(f"{c_}Valid loss Improved ({best_loss} ---> {val_loss})")
best_dice = val_dice
best_jaccard = val_jaccard
best_loss = val_loss
best_epoch = epoch
best_model_wts = copy.deepcopy(model.state_dict())
PATH = "best_epoch.bin"
torch.save(model.state_dict(), PATH)
print(f"Model Saved{sr_}")
last_model_wts = copy.deepcopy(model.state_dict())
PATH = "last_epoch.bin"
torch.save(model.state_dict(), PATH)
print();
print()
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}h {:.0f}m {:.0f}s'.format(
time_elapsed // 3600, (time_elapsed % 3600) // 60, (time_elapsed % 3600) % 60))
print("Best Loss: {:.4f}".format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model, history
def train_one_epoch(model, criterion,optimizer, scheduler, dataloader, device, epoch):
model.train()
scaler = amp.GradScaler()
dataset_size = 0
running_loss = 0.0
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Train ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with amp.autocast(enabled=True):
y_pred = model(images)
loss = criterion(y_pred, masks)
loss = loss / CFG.n_accumulate
scaler.scale(loss).backward()
if (step + 1) % CFG.n_accumulate == 0:
scaler.step(optimizer)
scaler.update()
# zero the parameter gradients
optimizer.zero_grad()
if scheduler is not None:
scheduler.step()
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(epoch=f'{epoch}',
train_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_mem=f'{mem:0.2f} GB')
torch.cuda.empty_cache()
gc.collect()
return epoch_loss
@torch.no_grad()
def valid_one_epoch(model, dataloader,criterion, optimizer,device, epoch):
model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
y_pred = model(images)
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
def run_trainingAndvaliding(model, optimizer,train_loader, valid_loader,scheduler, criterion, device, num_epochs):
if torch.cuda.is_available():
print("cuda: {}\n".format(torch.cuda.get_device_name()))
start = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = np.inf
best_epoch = -1
history = defaultdict(list)
for epoch in range(1, num_epochs + 1):
gc.collect()
print(f'Epoch {epoch}/{num_epochs}', end='')
# 训练
train_loss = train_one_epoch(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
dataloader=train_loader,
device=CFG.device,
epoch=epoch)
# 验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=epoch)
val_dice, val_jaccard = val_scores
history['Train Loss'].append(train_loss)
history['Valid Loss'].append(val_loss)
history['Valid Dice'].append(val_dice)
history['Valid Jaccard'].append(val_jaccard)
print(f'Valid Dice: {val_dice:0.4f} | Valid Jaccard: {val_jaccard:0.4f}')
print(f'Valid Loss: {val_loss}')
# deep copy the model
if val_loss <= best_loss:
print(f"{c_}Valid loss Improved ({best_loss} ---> {val_loss})")
best_dice = val_dice
best_jaccard = val_jaccard
best_loss = val_loss
best_epoch = epoch
best_model_wts = copy.deepcopy(model.state_dict())
PATH = "best_epoch.bin"
torch.save(model.state_dict(), PATH)
print(f"Model Saved{sr_}")
last_model_wts = copy.deepcopy(model.state_dict())
PATH = "last_epoch.bin"
torch.save(model.state_dict(), PATH)
print();
print()
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}h {:.0f}m {:.0f}s'.format(
time_elapsed // 3600, (time_elapsed % 3600) // 60, (time_elapsed % 3600) % 60))
print("Best Loss: {:.4f}".format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model, history
多折模型提交
import cv2
import pandas as pd
from torch.utils.data import DataLoader
from tqdm import tqdm
import torch
from major_config import CFG
from major_utils import rle_encode
from major_dataset import BuildDataset
import numpy as np
import torch.nn as nn
from major_BuildModel import build_model,build_model_vit
import os
from glob import glob
from tqdm import tqdm
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
'''
二 数据加载
'''
# 读取数据集路径
valid_img_paths =[]
for root, dirs, files in os.walk(r"D:\Kaggle_3DSeg\blood-vessel-segmentation\test"):
for idx, file in enumerate(tqdm(files)):
valid_img_paths.append(os.path.join(root,file).replace('\\','/'))
test_dataset = BuildDataset(valid_img_paths, [], transforms=CFG.data_transforms['valid'])
test_loader = DataLoader(test_dataset, batch_size=2, num_workers=0, shuffle=False, pin_memory=True)
### Inference
rles = []
pbar = tqdm(enumerate(test_loader), total=len(test_loader), desc='Inference ')
'''
模型加载
'''
model_1_path = "se_resnext50_32x4d_6_loss0.15_score0.80_val_loss0.15_val_score0.80_0_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model_1 = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model_1 = DataParallel(model_1)
model_1.load_state_dict(torch.load(model_1_path))
model_2_path = "mit_b1_6_loss0.24_score0.70_val_loss0.24_val_score0.70_0_Fold.pt"
CFG.backbone = "mit_b1"
model_2 = build_model_vit(CFG.backbone, CFG.num_classes, CFG.device)
model_2 = DataParallel(model_2)
model_2.load_state_dict(torch.load(model_2_path))
#
rles = []
for step, (images, shapes) in pbar:
shapes = shapes.numpy()
images = images.to(CFG.device, dtype=torch.float)
with torch.no_grad():
# 方式1:
preds_1 = model_1(images)
preds_2 = model_2(images)
preds = preds_1+preds_2
preds = (nn.Sigmoid()(preds)>0.3).double()
# 方式2:
preds_1 = model_1(images)
preds_2 = model_2(images)
preds = nn.Sigmoid()(preds_2) + nn.Sigmoid()(preds_1)
preds = (preds>0.3).double()
preds = preds.cpu().numpy().astype(np.uint8)
for pred, shape in zip(preds, shapes):
pred = cv2.resize(pred[0], (shape[1], shape[0]), cv2.INTER_NEAREST)
rle = rle_encode(pred)
rles.append(rle)
ids =[f'{p.split("/")[-3]}_{os.path.basename(p).split(".")[0]}' for p in valid_img_paths]
submission = pd.DataFrame.from_dict({
"id": ids,
"rle": rles
})
submission.head()
submission.to_csv('submission.csv', index=False)
cpu版
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from major_config import CFG
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
import numpy as np
import torch
from tqdm import tqdm
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
calculate_mead_std_imgPath = gt_df["img_path"].values.tolist()
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
calculate_mead_std_maskPath = gt_df["msk_path"].values.tolist()
if CFG.debug:
calculate_mead_std_imgPath = calculate_mead_std_imgPath[:100]
calculate_mead_std_maskPath = calculate_mead_std_maskPath[:100]
# 验证集
# 图像预处理
valid_dataset = BuildDataset(calculate_mead_std_imgPath, calculate_mead_std_maskPath, transforms=CFG.data_transforms['valid'])
valid_loader = DataLoader(valid_dataset, batch_size=1000, num_workers=0, shuffle=False, pin_memory=True)
pbar = tqdm(enumerate(valid_loader), total=len(valid_loader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to("cpu", dtype=torch.float)
train_mean = np.mean(images.numpy(), axis=(0, 2, 3))
train_std = np.std(images.numpy(), axis=(0, 2, 3))
print("train_mean:",train_mean)
print("train_std:",train_std)
# train_mean: [0.5785608 0.5785608 0.5785608]
# train_std: [0.12644446 0.12644446 0.12644446]
# train_mean: [0.56037647 0.56037647 0.56037647]
# train_std: [0.12725429 0.12725429 0.12725429]
五折模型的输出融合
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model,build_model_vit
from major_optimizer import fetch_scheduler
from major_TrainAndVal import valid_one_epoch,valid_one_epoch_MultiModel2,valid_one_epoch_MultiModel
from major_loss import criterion
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
CFG.train_groups = ["kidney_1_dense", "kidney_3_dense"]
CFG.valid_groups = [ "kidney_2"]
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# 判断是否是Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs*50]
train_msk_paths = train_msk_paths[:CFG.train_bs*50]
valid_img_paths = valid_img_paths[:CFG.valid_bs*30]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs*30]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
model_list = []
'''
三 构建模型
'''
model_1_path = "mit_b1_1_loss0.12_score0.86_val_loss0.12_val_score0.86.pt"
CFG.backbone = "mit_b1"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load(model_1_path))
model = DataParallel(model)
model_list.append(model)
'''
四 损失函数
'''
criterion = criterion
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 训练和验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
#############################################################################################################################################
# 提交
model_1_path = "timm-efficientnet-b2_32_loss0.06_score0.94_val_loss0.06_val_score0.94.pt"
CFG.backbone = "timm-efficientnet-b2"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load(model_1_path))
model = DataParallel(model)
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
model_1_path = "se_resnext50_32x4d_16_loss0.12_score0.88_val_loss0.12_val_score0.88_2_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
#############################################################################################################################################
model_1_path = "se_resnext50_32x4d_19_loss0.08_score0.92_val_loss0.08_val_score0.92_1_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
model_1_path = "se_resnext50_32x4d_15_loss0.26_score0.64_val_loss0.26_val_score0.64_0_Fold.pt"
CFG.backbone = "se_resnext50_32x4d"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model = DataParallel(model)
model.load_state_dict(torch.load(model_1_path))
model_list.append(model)
# 验证
# val_loss, val_scores = valid_one_epoch(model=model,
# dataloader=valid_loader,
# criterion=criterion,
# optimizer=optimizer,
# device=CFG.device,
# epoch=1)
#
# print("val_loss",val_loss)
# print("val_DiceScores",val_scores)
# model_1_path = "se_resnext50_32x4d_6_loss0.15_score0.80_val_loss0.15_val_score0.80_0_Fold.pt"
# CFG.backbone = "se_resnext50_32x4d"
#
# model_1 = build_model(CFG.backbone, CFG.num_classes, CFG.device)
# model_1 = DataParallel(model_1)
# model_1.load_state_dict(torch.load(model_1_path))
#
#
# model_2_path = "mit_b1_6_loss0.24_score0.70_val_loss0.24_val_score0.70_0_Fold.pt"
# CFG.backbone = "mit_b1"
# model_2 = build_model_vit(CFG.backbone, CFG.num_classes, CFG.device)
# model_2 = DataParallel(model_2)
# model_2.load_state_dict(torch.load(model_2_path))
#
# model_list= [model_1,model_2]
val_loss, val_scores = valid_one_epoch_MultiModel2(model_list=model_list,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
@torch.no_grad()
def valid_one_epoch_MultiModel2(model_list, dataloader,criterion, optimizer,device, epoch):
# model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
preds_1 = model_list[0](images)
preds_2 = model_list[1](images)
preds_3 = model_list[2](images)
preds_4 = model_list[3](images)
preds_5 = model_list[4](images)
y_pred = preds_1+preds_2+preds_3+preds_4+preds_5
# y_pred = model(images)
# preds_1 = model_list[0](images)
# preds_2 = model_list[1](images)
# y_pred = 0.7*preds_1 + 0.3*preds_2
# preds = (preds>0.3).double()
#
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
VIt、CNN、Vit和CNN进行输出概率图融合的比较
@torch.no_grad()
def valid_one_epoch(model, dataloader,criterion, optimizer,device, epoch):
model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
y_pred = model(images)
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
@torch.no_grad()
def valid_one_epoch_MultiModel(model_list, dataloader,criterion, optimizer,device, epoch):
# model.eval()
dataset_size = 0
running_loss = 0.0
val_scores = []
pbar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Valid ')
for step, (images, masks) in pbar:
images = images.to(device, dtype=torch.float)
masks = masks.to(device, dtype=torch.float)
batch_size = images.size(0)
with autocast():
# y_pred = model(images)
preds_1 = model_list[0](images)
preds_2 = model_list[1](images)
y_pred = 0.7*preds_1 + 0.3*preds_2
# preds = (preds>0.3).double()
#
loss = criterion(y_pred, masks)
running_loss += (loss.item() * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn.Sigmoid()(y_pred)
val_dice = dice_coef(masks, y_pred).cpu().detach().numpy()
val_jaccard = iou_coef(masks, y_pred).cpu().detach().numpy()
val_scores.append([val_dice, val_jaccard])
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0
current_lr = optimizer.param_groups[0]['lr']
pbar.set_postfix(valid_loss=f'{epoch_loss:0.4f}',
lr=f'{current_lr:0.5f}',
gpu_memory=f'{mem:0.2f} GB')
val_scores = np.mean(val_scores, axis=0)
torch.cuda.empty_cache()
gc.collect()
return epoch_loss, val_scores
import os
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
# 导入配置文件
from major_config import CFG
from major_utils import set_seed
from major_dataset import BuildDataset
from major_BuildModel import build_model,build_model_vit
from major_optimizer import fetch_scheduler
from major_TrainAndVal import valid_one_epoch,valid_one_epoch_MultiModel2,valid_one_epoch_MultiModel
from major_loss import criterion
from torch.nn.parallel import DataParallel # 单机多卡的分布式训练(数据并行) 模型训练加速
import torch
'''
一 配置参数
'''
# 设置随机种子
set_seed(CFG.seed)
CFG.gt_df = r"gt.csv"
CFG.data_root = r"D:\Kaggle_3DSeg"
CFG.debug = False
CFG.train_groups = ["kidney_1_dense", "kidney_3_dense"]
CFG.valid_groups = [ "kidney_2"]
CFG.valid_bs = 64
'''
二 数据加载
'''
# 读取数据集路径
gt_df = pd.read_csv(CFG.gt_df)
# 训练集组别
train_groups = CFG.train_groups
valid_groups = CFG.valid_groups
# 替换图像路径为真实路径
gt_df["img_path"] = gt_df["img_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 替换mask路径为真实路径
gt_df["msk_path"] = gt_df["msk_path"].apply(lambda x: os.path.join(CFG.data_root, x))
# 重置索引
train_df = gt_df.query("group in @train_groups").reset_index(drop=True)
valid_df = gt_df.query("group in @valid_groups").reset_index(drop=True)
# 训练集图像路径
train_img_paths = train_df["img_path"].values.tolist()
# 训练集mask路径
train_msk_paths = train_df["msk_path"].values.tolist()
# 验证集图像路径
valid_img_paths = valid_df["img_path"].values.tolist()
# 训练集mask路径
valid_msk_paths = valid_df["msk_path"].values.tolist()
# 判断是否是Debug模式
if CFG.debug:
train_img_paths = train_img_paths[:CFG.train_bs*50]
train_msk_paths = train_msk_paths[:CFG.train_bs*50]
valid_img_paths = valid_img_paths[:CFG.valid_bs*30]
valid_msk_paths = valid_msk_paths[:CFG.valid_bs*30]
# 训练集
train_dataset = BuildDataset(train_img_paths, train_msk_paths, transforms=CFG.data_transforms['train'])
# 验证集
valid_dataset = BuildDataset(valid_img_paths, valid_msk_paths, transforms=CFG.data_transforms['valid'])
# 训练集加载器
train_loader = DataLoader(train_dataset, batch_size=CFG.train_bs, num_workers=0, shuffle=True, pin_memory=True,
drop_last=False)
# 验证集加载器
valid_loader = DataLoader(valid_dataset, batch_size=CFG.valid_bs, num_workers=0, shuffle=False, pin_memory=True)
model_list = []
# 提交
model_1_path = "timm-efficientnet-b2_32_loss0.06_score0.94_val_loss0.06_val_score0.94.pt"
CFG.backbone = "timm-efficientnet-b2"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load(model_1_path))
model = DataParallel(model)
model_list.append(model)
'''
四 损失函数
'''
criterion = criterion
'''
六 优化策略
'''
optimizer = optim.Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.wd)
scheduler = fetch_scheduler(optimizer)
# 验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
#############################################################################################################################################
'''
三 构建模型
'''
model_1_path = "mit_b1_1_loss0.12_score0.86_val_loss0.12_val_score0.86.pt"
CFG.backbone = "mit_b1"
model = build_model(CFG.backbone, CFG.num_classes, CFG.device)
model.load_state_dict(torch.load(model_1_path))
model = DataParallel(model)
model_list.append(model)
# 训练和验证
val_loss, val_scores = valid_one_epoch(model=model,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
#############################################################################################################################################
val_loss, val_scores = valid_one_epoch_MultiModel(model_list=model_list,
dataloader=valid_loader,
criterion=criterion,
optimizer=optimizer,
device=CFG.device,
epoch=1)
print("val_loss",val_loss)
print("val_DiceScores",val_scores)
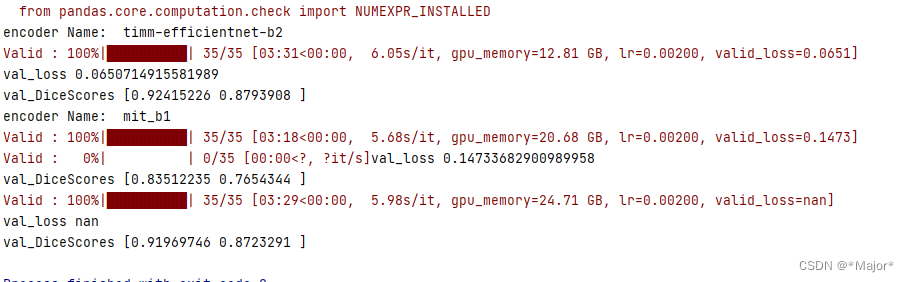
vit和cnn联合起来,可能没有单CNN好















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









