








LDPC基础概念
对于这个问题,还是需要对LDPC码有初步的了解,下面先由一个普通的规则LDPC校验矩阵引出一些基础概念和其工作方式。
对于一个简单的LDPC校验矩阵H:
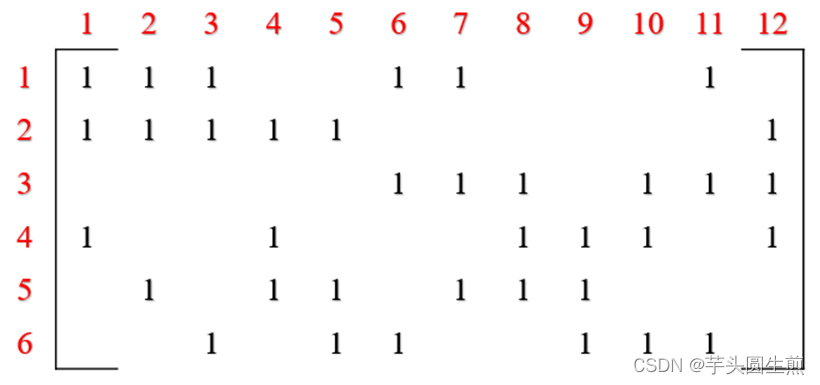
其中,行数表示校验节点的个数,列数表示变量节点的个数。在此例中,校验节点个数为6,变量节点个数为12.
可以将其表示为Tanner图的形式,一类为校验节点,一类为可变节点:
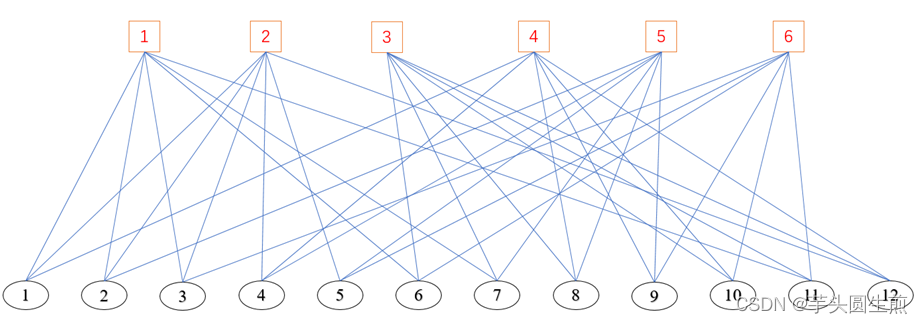
在Tanner图中,与每一个校验节点相连的变量节点构成一个Parity Check Set,在实际进行校验时,若要校验某个变量节点对应的信息位是否错误,则需要对所有包含此个变量节点的Parity Check Set进行奇偶校验。
下面用一个基础矩阵的一部分进行说明为何要去掉部分信息位:
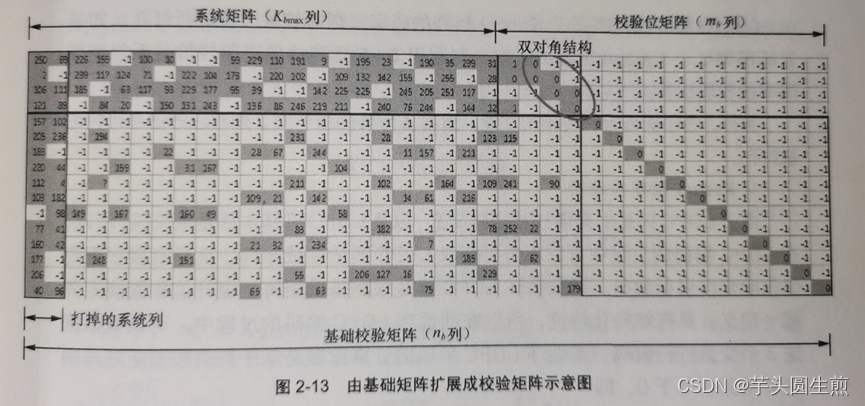
可以观察到,此基础矩阵最左边列的列重很大,目的是保证校验节点通过与前几个变量节点的充分连接,来达到校验节点彼此之间信息的顺畅流通——体现在Tanner图中,就是前两个变量节点与大多数校验节点相连。单从理论上分析:若不对其进行任何操作,则前两个系统比特需要跟所有 在同一个Parity Check Set中的其他变量节点对应的系统比特 进行奇偶校验操作,但由于此两个系统比特出现在几乎所有Parity Check Set中,因此这种校验在大多数情况下是重复的。
大量分析和仿真也表明,如果不传输左边列重很大的变量节点所对应的系统比特,LDPC码的性能会进一步提高。“为了保证首次传输的性能,通常A矩阵最前面两列对应的信息比特也被打孔。”
结论
在实际编码中,需要首先确定一个基础矩阵和一个扩展因子(Lifting Size),它们共同构造一个扩展矩阵,并基于这个扩展矩阵对输出的信息位进行编码、对接收端的信息进行校验。比如:对于一个[2, 4]的基础矩阵和Lifting Size=3,扩展矩阵的大小为[23, 43]=[6, 12]。
因此,在实际编码中,需要打掉前 2Zc 的信息位长度,从而提高编码性能,而且由于打孔的同时还引入了冗余比特,所以接收端可以进行译码,而不会对信息传输造成影响。















 3817
3817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









