









EDA部分
比赛的任务是识别给定图片属于哪个鲸鱼或海豚。只预测ID,不预测品种
1、样本是什么样的
有2个jpg格式存储的训练集和测试集,2个csv文件存储样本标签信息,1个submission.csv标明对每张图像预测对应id
2、标签是什么样的
对于每张图像指明所属id(用individual_id)
id有1万5千多个,共有28个种类
3、样本量有多大
训练集有5万多张,测试集有近3万张
4、EDA做了哪些工作
查看样本、标签情况,处理脏数据、样本分布、数据增强(调用库:HSV、旋转)
 样本分布情况:鲸鱼 67% 海豚33%
样本分布情况:鲸鱼 67% 海豚33%
排名前三的种类:宽吻海豚、白鲸、座头鲸
5、评价指标
top 5的mAP:预测的前5个有1个正确则正确
top-5预测就是预测出最可能属于哪个类、第二可能属于哪个类……第五可能属于哪个类,这五个预测值中,只要有一个跟真实的label能对应上,计算top-5 mAP时就判定为预测正确。
6、介绍一下鲸鱼比赛
分为两个部分,训练过程EfficientNet + Arcface Loss进行训练得到n个类别,预测时将图像输入EfficientNet得到每张图的embedding,计算每幅图的embedding跟训练集中已知id的图像对应的embedding之间(训练过程的efficientnet得到)的余弦距离,取最近的5个id作为预测结果。
Arcface Loss详解
人脸识别的目标:类内聚,类间开(同一类的embedding靠近,不同类的远离)
triplet loss
每条训练样本包括三张图像:a、p、n,其中a和p属于同一个人,n是另一个人,f(x)表示图像经过神经网络学到的特征向量。a和p的特征向量的距离应该小于a和n的特征向量的距离。为了加强区分度,约束a和p的特征向量的距离比a和n的特征向量的距离小:
![]()
triplet loss的缺点是需要image2image地比较(预测时,需要将输入图像的特征向量跟训练集所有图像的特征向量计算距离,比较距离大小,将距离最小的作为预测的类别),时间复杂度太高。
softmax loss
将人脸识别当做多分类任务,每个人对应一个类别。将神经网络得到的向量进行softmax激活后利用softmax损失函数进行训练,预测时用softmax激活的结果判断当前图片属于哪个人
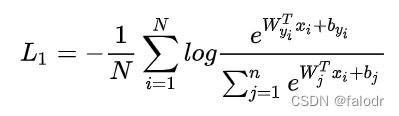
softmax loss做人脸识别存在两个缺点:
(1)类间没有margin:margin作用是让不同的类距离越远越好
(2)W矩阵随着类别数线性增长:w的行数=类别数
arcface loss
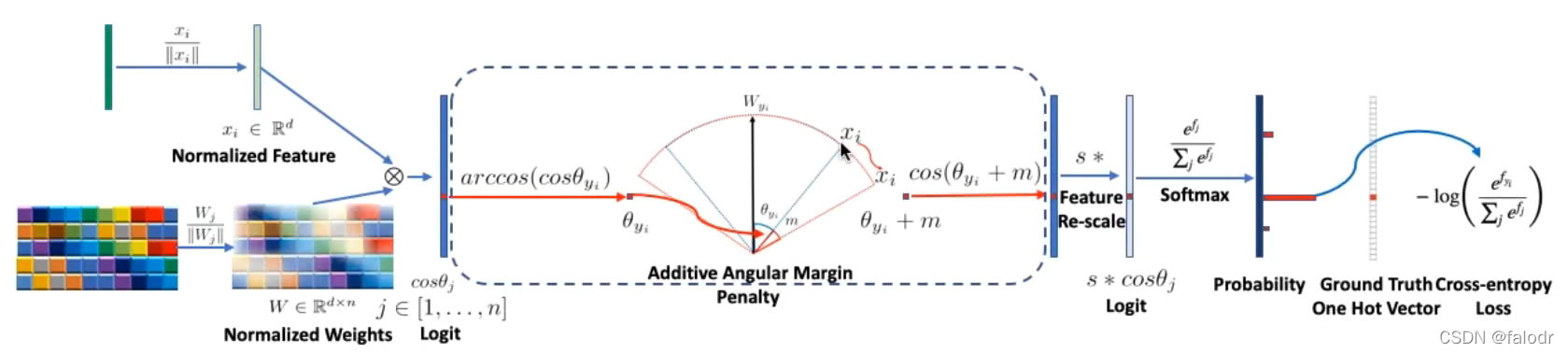
如上图,arcface loss是在softmax loss的基础上改进来的:是类别j的向量表示(类中心),
是当前这幅图的向量表示,在
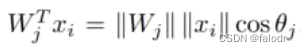
中,当 和
等于1时,
![]() 就等于
就等于![]() ,
,![]() 就是
就是和
的夹角,
![]() 是加上一个 margin之后的夹角,
是加上一个 margin之后的夹角,![]()
就是带margin的和
的向量内积,s是缩放因子。由此我们推出arcface loss:
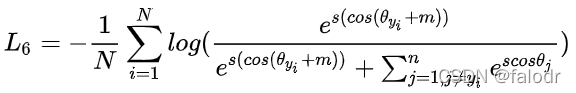
7、各部分的输入输出
训练时:提取的特征具有类内聚,类间开的效果
efficientnet B5的输入是图像512 * 512,输出是1*512维的embedding(arcface规定尺寸)
arcface输入是1*512维的embedding和512*n_class的权重矩阵,输出是n_class*1维度的向量
预测时:
训练完成后,将训练集每张图像都输入efficient B5得到训练集所有图像的embedding矩阵
efficientnet B5的输入是图像512 * 512,输出是1*512维的embedding,找到该embedding跟训练集embedding最近(使用余弦距离作为距离度量)的N个邻居,用这N个邻居的ID作为预测结果。
7.1 Efficient B5的输入尺寸不是456 * 456吗?(Efficient B5的输入尺寸不是512 * 512吧?)你说是512?
456 * 456是论文提出的最佳实践,而且跟论文中全连接层的神经元数有关;这个项目中神经元数跟论文中不同。
8、人脸识别你还了解哪些其它算法
triplet loss、softmax loss
9、人脸识别和普通的分类有什么区别
普通的分类类别数一般很少,类之间的特征一般差异很大,模型比较容易区分不同的类;人脸识别类别数很多(每个人都是一个类别),不同类别之间的特征差异不大,为了更好地区分各个类别,需要做到“类内聚,类间开”。
10、你有哪些创新点/你有哪些idea
1、先做目标检测,检测出图像中鲸鱼/海豚的位置,再进行ID识别,这样可以降低背景对识别的干扰。要做到这一点,需要人工打标签,标出每只海豚/鲸鱼的位置
2、先做分类,分类出鲸鱼/海豚,再进行ID识别
3、解决各个ID样本数呈现长尾分布的问题
4、使用focal loss提升难分样本的权重
11、参数设置
batch_size = 32,learning_rate =10^-3,EPOCHS=20,KNN的K=1000
12、你是根据什么来做的earlying stop/学习率衰减
根据验证集的loss,如果连续两个epoch的loss不再下降就停止训练
设置学习率的衰减率,监控指标是val_loss,超过3个epoch监控指标不提升就降低LR,监控指标最小就是最好,LR最低为1e-6
训练集的loss只要模型是收敛的,那么loss一定是在下降的,所以通过val_loss来刻画模型是否过拟合(表现为训练loss越来越小,验证loss越来越大),如果训练loss不下降是欠拟合
13、图片输入前怎么做的归一化 / 为什么不用零均值归一化呢
线性归一化 / 因为图像的像素值全都是正数,用线性归一化将其归一化到0-1之间比0均值归一化(会有负值)更符合实际物理意义
14、遇到过什么样的挑战?怎么解决的
类别不均衡问题很严重,有的ID有几十张样本,而很多ID只有一两个样本。
通过在loss里设置权重解决了这个问题。
15、你做了哪些工作
做了数据的分析,清理脏数据;用efficient + arcface训练模型,保存训练数据的embedding,使用KNN做测试样本的top5预测。
16、训练时长,为什么能这么快,你是把原始的图片直接送到模型进行训练吗
每个epoch3分多钟(因为是用TPU训练的才这么快,尝试过用GPU训练,一个epoch要两个多小时,太慢了),共20个epoch。
17、各项参数以及超参存放在哪里
写在代码的变量里,用字典存储
18、鲸鱼这个比赛你没有做数据扩增吗
做了,旋转平移缩放
19、为什么要用KNN算法,而不是直接用softmax激活后各个分类得分的top 5结果
在训练的时候监控验证集的top 5结果的正确性,发现训练集准确率99%以上时,验证集准确率只有20%多;这说明用测试集去预测准确率肯定更低。
所以预测时不适用softmax激活后各个分类的得分结果,而是用待预测样本的embedding去跟训练集得到的embedding去做KNN,用最近(余弦距离)的5个邻居对应的类别作为预测结果。
用KNN去做预测,相比于softmax激活后的得分值,省去了embedding跟W权重矩阵相乘这一步,W权重有可能学得不好,跟真正的类中心存在误差,省去embedding跟W权重矩阵相乘这一步减小了误差。
20、为什么KNN的K要设置为1000,而不是直接设置为5就行?
因为最近的N个邻居中,可能有很多邻居对应的类别是一样的,要做去重。
21、如果KNN的结果中,有多个邻居对应的是同一个类(同一个鲸鱼/海豚个体),该怎么处理?(怎么去重?)
取这些邻居中,余弦夹角最小的那个邻居作为预测结果进行去重
20、为什么要用的Efficient B5 + B6 + B7这样做融合,新冠的比赛也是这样做的融合吗?为什么融合方法不一样?
这样尽量让不同的模型的预测结果不同,泛化性强
新冠的比赛模型都是用的B7,当时没想到这样去做,是这次才想到的
21、有没有对同一个模型的结果做融合?有没有用多个B5的结果做融合?
做了。训练了5个模型,把这5个模型的训练集embedding做了平均。
22、你做了交叉验证吗?
鲸鱼比赛中用了。
21、为什么不用EfficientV2?对V2有了解吗?
之前的新冠比赛用的V1,比较熟悉,这个比赛继续沿用。
有一点简单的了解,EfficientV2分为small、medium、large模型,推理速度比同等参数量的V1更快。
22、长尾分布是什么?除了reWeight还有什么办法解决这个问题
是样本不均衡的一种表现,即少数几个类样本数很多,大量类别样本数很少
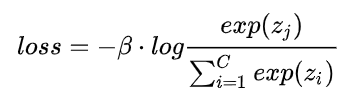 ,
,
对softmax添加一个经过计算的权重,来给头部类别更低的权重,给尾部类别更高的权重,来抵消长尾效应。
还可以对头部类别下采样,对尾部类别上采样
22、你对数据做了什么探索,清理了什么脏数据?
有两个品种写错了,进行了更正。
23、为什么你要用ArcFace和Efficient B5来做这个比赛呢?
这个比赛数据量很大,B5参数量小一些,训练时间短。
24、你这些项目中的改进都是你自己想到的吗?
数据增强、模型融合是自己学习基础知识时迁移过来的。
YOLO V5 + efficient是别人想到的

















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









