







1. 参考文本载入
from bs4 import BeautifulSoup as Soup
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
# LCEL docs
url = "https://python.langchain.com/docs/concepts/lcel/"
loader = RecursiveUrlLoader(
url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# Sort the list based on the URLs and get the text
d_sorted = sorted(docs, key=lambda x: x.metadata["source"])
d_reversed = list(reversed(d_sorted))
concatenated_content = "\n\n\n --- \n\n\n".join(
[doc.page_content for doc in d_reversed]
)
print(concatenated_content)
LangChain Expression Language (LCEL) | 🦜️🔗 LangChain
Skip to main contentIntegrationsAPI ReferenceMoreContributingPeopleError referenceLangSmithLangGraphLangChain HubLangChain JS/TSv0.3v0.3v0.2v0.1💬SearchIntroductionTutorialsBuild a Question Answering application over a Graph DatabaseTutorialsBuild a simple LLM application with chat models and prompt templatesBuild a ChatbotBuild a Retrieval Augmented Generation (RAG) App: Part 2Build an Extraction ChainBuild an AgentTaggingBuild a Retrieval Augmented Generation (RAG) App: Part 1Build a semantic search engineBuild a Question/Answering system over SQL dataSummarize TextHow-to guidesHow-to guidesHow to use tools in a chainHow to use a vectorstore as a retrieverHow to add memory to chatbotsHow to use example selectorsHow to add a semantic layer over graph databaseHow to invoke runnables in parallelHow to stream chat model responsesHow to add default invocation args to a RunnableHow to add retrieval to chatbotsHow to use few shot examples in chat modelsHow to do tool/function callingHow to install LangChain packagesHow to add examples to the prompt for query analysisHow to use few shot examplesHow to run custom functionsHow to use output parsers to parse an LLM response into structured formatHow to handle cases where no queries are generatedHow to route between sub-chainsHow to return structured data from a modelHow to summarize text through parallelizationHow to summarize text through iterative refinementHow to summarize text in a single LLM callHow to use toolkitsHow to add ad-hoc tool calling capability to LLMs and Chat ModelsBuild an Agent with AgentExecutor (Legacy)How to construct knowledge graphsHow to partially format prompt templatesHow to handle multiple queries when doing query analysisHow to use built-in tools and toolkitsHow to pass through arguments from one step to the nextHow to compose prompts togetherHow to handle multiple retrievers when doing query analysisHow to add values to a chain's stateHow to construct filters for query analysisHow to configure runtime chain internalsHow deal with high cardinality categoricals when doing query analysisCustom Document LoaderHow to split by HTML headerHow to split by HTML sectionsHow to use the MultiQueryRetrieverHow to add scores to retriever resultsCachingHow to use callbacks in async environmentsHow to attach callbacks to a runnableHow to propagate callbacks constructorHow to dispatch custom callback eventsHow to pass callbacks in at runtimeHow to split by characterHow to cache chat model responsesHow to handle rate limitsHow to init any model in one lineHow to track token usage in ChatModelsHow to add tools to chatbotsHow to split codeHow to do retrieval with contextual compressionHow to convert Runnables to ToolsHow to create custom callback handlersHow to create a custom chat model classHow to create a custom LLM classCustom RetrieverHow to create toolsHow to debug your LLM appsHow to load CSVsHow to load documents from a directoryHow to load HTMLHow to load JSONHow to load MarkdownHow to load Microsoft Office filesHow to load PDFsHow to load web pagesHow to create a dynamic (self-constructing) chainText embedding modelsHow to combine results from multiple retrieversHow to select examples from a LangSmith datasetHow to select examples by lengthHow to select examples by maximal marginal relevance (MMR)How to select examples by n-gram overlapHow to select examples by similarityHow to use reference examples when doing extractionHow to handle long text when doing extractionHow to use prompting alone (no tool calling) to do extractionHow to add fallbacks to a runnableHow to filter messagesHybrid SearchHow to use the LangChain indexing APIHow to inspect runnablesLangChain Expression Language CheatsheetHow to cache LLM responsesHow to track token usage for LLMsRun models locallyHow to get log probabilitiesHow to reorder retrieved results to mitigate the "lost in the middle" effectHow to split Markdown by HeadersHow to merge consecutive messages of the same typeHow to add message historyHow to migrate from legacy LangChain agents to LangGraphHow to retrieve using multiple vectors per documentHow to pass multimodal data directly to modelsHow to use multimodal promptsHow to create a custom Output ParserHow to use the output-fixing parserHow to parse JSON outputHow to retry when a parsing error occursHow to parse text from message objectsHow to parse XML outputHow to parse YAML outputHow to use the Parent Document RetrieverHow to use LangChain with different Pydantic versionsHow to add chat historyHow to get a RAG application to add citationsHow to do per-user retrievalHow to get your RAG application to return sourcesHow to stream results from your RAG applicationHow to split JSON dataHow to recursively split text by charactersResponse metadataHow to pass runtime secrets to runnablesHow to do "self-querying" retrievalHow to split text based on semantic similarityHow to chain runnablesHow to save and load LangChain objectsHow to split text by tokensHow to do question answering over CSVsHow to deal with large databases when doing SQL question-answeringHow to better prompt when doing SQL question-answeringHow to do query validation as part of SQL question-answeringHow to stream runnablesHow to stream responses from an LLMHow to use a time-weighted vector store retrieverHow to return artifacts from a toolHow to use chat models to call toolsHow to disable parallel tool callingHow to force models to call a toolHow to access the RunnableConfig from a toolHow to pass tool outputs to chat modelsHow to pass run time values to toolsHow to stream events from a toolHow to stream tool callsHow to convert tools to OpenAI FunctionsHow to handle tool errorsHow to use few-shot prompting with tool callingHow to add a human-in-the-loop for toolsHow to bind model-specific toolsHow to trim messagesHow to create and query vector storesConceptual guideAgentsArchitectureAsync programming with langchainCallbacksChat historyChat modelsDocument loadersEmbedding modelsEvaluationExample selectorsFew-shot promptingConceptual guideKey-value storesLangChain Expression Language (LCEL)MessagesMultimodalityOutput parsersPrompt TemplatesRetrieval augmented generation (RAG)RetrievalRetrieversRunnable interfaceStreamingStructured outputsTestingString-in, string-out llmsText splittersTokensTool callingToolsTracingVector storesWhy LangChain?Ecosystem🦜🛠️ LangSmith🦜🕸️ LangGraphVersionsv0.3v0.2Pydantic compatibilityMigrating from v0.0 chainsHow to migrate from v0.0 chainsMigrating from ConstitutionalChainMigrating from ConversationalChainMigrating from ConversationalRetrievalChainMigrating from LLMChainMigrating from LLMMathChainMigrating from LLMRouterChainMigrating from MapReduceDocumentsChainMigrating from MapRerankDocumentsChainMigrating from MultiPromptChainMigrating from RefineDocumentsChainMigrating from RetrievalQAMigrating from StuffDocumentsChainUpgrading to LangGraph memoryHow to migrate to LangGraph memoryHow to use BaseChatMessageHistory with LangGraphMigrating off ConversationBufferMemory or ConversationStringBufferMemoryMigrating off ConversationBufferWindowMemory or ConversationTokenBufferMemoryMigrating off ConversationSummaryMemory or ConversationSummaryBufferMemoryA Long-Term Memory AgentRelease policySecurity PolicyConceptual guideLangChain Expression Language (LCEL)On this pageLangChain Expression Language (LCEL)
Prerequisites
Runnable Interface
The LangChain Expression Language (LCEL) takes a declarative approach to building new Runnables from existing Runnables.
This means that you describe what should happen, rather than how it should happen, allowing LangChain to optimize the run-time execution of the chains.
We often refer to a Runnable created using LCEL as a "chain". It's important to remember that a "chain" is Runnable and it implements the full Runnable Interface.
note
The LCEL cheatsheet shows common patterns that involve the Runnable interface and LCEL expressions.
Please see the following list of how-to guides that cover common tasks with LCEL.
A list of built-in Runnables can be found in the LangChain Core API Reference. Many of these Runnables are useful when composing custom "chains" in LangChain using LCEL.
Benefits of LCEL
LangChain optimizes the run-time execution of chains built with LCEL in a number of ways:
Optimized parallel execution: Run Runnables in parallel using RunnableParallel or run multiple inputs through a given chain in parallel using the Runnable Batch API. Parallel execution can significantly reduce the latency as processing can be done in parallel instead of sequentially.
Guaranteed Async support: Any chain built with LCEL can be run asynchronously using the Runnable Async API. This can be useful when running chains in a server environment where you want to handle large number of requests concurrently.
Simplify streaming: LCEL chains can be streamed, allowing for incremental output as the chain is executed. LangChain can optimize the streaming of the output to minimize the time-to-first-token(time elapsed until the first chunk of output from a chat model or llm comes out).
Other benefits include:
Seamless LangSmith tracing
As your chains get more and more complex, it becomes increasingly important to understand what exactly is happening at every step.
With LCEL, all steps are automatically logged to LangSmith for maximum observability and debuggability.
Standard API: Because all chains are built using the Runnable interface, they can be used in the same way as any other Runnable.
Deployable with LangServe: Chains built with LCEL can be deployed using for production use.
Should I use LCEL?
LCEL is an orchestration solution -- it allows LangChain to handle run-time execution of chains in an optimized way.
While we have seen users run chains with hundreds of steps in production, we generally recommend using LCEL for simpler orchestration tasks. When the application requires complex state management, branching, cycles or multiple agents, we recommend that users take advantage of LangGraph.
In LangGraph, users define graphs that specify the application's flow. This allows users to keep using LCEL within individual nodes when LCEL is needed, while making it easy to define complex orchestration logic that is more readable and maintainable.
Here are some guidelines:
If you are making a single LLM call, you don't need LCEL; instead call the underlying chat model directly.
If you have a simple chain (e.g., prompt + llm + parser, simple retrieval set up etc.), LCEL is a reasonable fit, if you're taking advantage of the LCEL benefits.
If you're building a complex chain (e.g., with branching, cycles, multiple agents, etc.) use LangGraph instead. Remember that you can always use LCEL within individual nodes in LangGraph.
Composition Primitives
LCEL chains are built by composing existing Runnables together. The two main composition primitives are RunnableSequence and RunnableParallel.
Many other composition primitives (e.g., RunnableAssign) can be thought of as variations of these two primitives.
noteYou can find a list of all composition primitives in the LangChain Core API Reference.
RunnableSequence
RunnableSequence is a composition primitive that allows you "chain" multiple runnables sequentially, with the output of one runnable serving as the input to the next.
from langchain_core.runnables import RunnableSequencechain = RunnableSequence([runnable1, runnable2])API Reference:RunnableSequence
Invoking the chain with some input:
final_output = chain.invoke(some_input)
corresponds to the following:
output1 = runnable1.invoke(some_input)final_output = runnable2.invoke(output1)
noterunnable1 and runnable2 are placeholders for any Runnable that you want to chain together.
RunnableParallel
RunnableParallel is a composition primitive that allows you to run multiple runnables concurrently, with the same input provided to each.
from langchain_core.runnables import RunnableParallelchain = RunnableParallel({ "key1": runnable1, "key2": runnable2,})API Reference:RunnableParallel
Invoking the chain with some input:
final_output = chain.invoke(some_input)
Will yield a final_output dictionary with the same keys as the input dictionary, but with the values replaced by the output of the corresponding runnable.
{ "key1": runnable1.invoke(some_input), "key2": runnable2.invoke(some_input),}
Recall, that the runnables are executed in parallel, so while the result is the same as
dictionary comprehension shown above, the execution time is much faster.
noteRunnableParallelsupports both synchronous and asynchronous execution (as all Runnables do).
For synchronous execution, RunnableParallel uses a ThreadPoolExecutor to run the runnables concurrently.
For asynchronous execution, RunnableParallel uses asyncio.gather to run the runnables concurrently.
Composition Syntax
The usage of RunnableSequence and RunnableParallel is so common that we created a shorthand syntax for using them. This helps
to make the code more readable and concise.
The | operator
We have overloaded the | operator to create a RunnableSequence from two Runnables.
chain = runnable1 | runnable2
is Equivalent to:
chain = RunnableSequence([runnable1, runnable2])
The .pipe method`
If you have moral qualms with operator overloading, you can use the .pipe method instead. This is equivalent to the | operator.
chain = runnable1.pipe(runnable2)
Coercion
LCEL applies automatic type coercion to make it easier to compose chains.
If you do not understand the type coercion, you can always use the RunnableSequence and RunnableParallel classes directly.
This will make the code more verbose, but it will also make it more explicit.
Dictionary to RunnableParallel
Inside an LCEL expression, a dictionary is automatically converted to a RunnableParallel.
For example, the following code:
mapping = { "key1": runnable1, "key2": runnable2,}chain = mapping | runnable3
It gets automatically converted to the following:
chain = RunnableSequence([RunnableParallel(mapping), runnable3])
cautionYou have to be careful because the mapping dictionary is not a RunnableParallel object, it is just a dictionary. This means that the following code will raise an AttributeError:mapping.invoke(some_input)
Function to RunnableLambda
Inside an LCEL expression, a function is automatically converted to a RunnableLambda.
def some_func(x): return xchain = some_func | runnable1
It gets automatically converted to the following:
chain = RunnableSequence([RunnableLambda(some_func), runnable1])
cautionYou have to be careful because the lambda function is not a RunnableLambda object, it is just a function. This means that the following code will raise an AttributeError:lambda x: x + 1.invoke(some_input)
Legacy chains
LCEL aims to provide consistency around behavior and customization over legacy subclassed chains such as LLMChain and
ConversationalRetrievalChain. Many of these legacy chains hide important details like prompts, and as a wider variety
of viable models emerge, customization has become more and more important.
If you are currently using one of these legacy chains, please see this guide for guidance on how to migrate.
For guides on how to do specific tasks with LCEL, check out the relevant how-to guides.Edit this pageWas this page helpful?PreviousKey-value storesNextMessagesBenefits of LCELShould I use LCEL?Composition PrimitivesRunnableSequenceRunnableParallelComposition SyntaxThe | operatorThe .pipe method`CoercionLegacy chainsCommunityTwitterGitHubOrganizationPythonJS/TSMoreHomepageBlogYouTubeCopyright © 2024 LangChain, Inc.
2. 代码生成节点
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
### OpenAI
# Grader prompt
code_gen_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are a coding assistant with expertise in LCEL, LangChain expression language. \n
Here is a full set of LCEL documentation: \n ------- \n {context} \n ------- \n Answer the user
question based on the above provided documentation. Ensure any code you provide can be executed \n
with all required imports and variables defined. Structure your answer with a description of the code solution. \n
Then list the imports. And finally list the functioning code block. Here is the user question:""",
),
("placeholder", "{messages}"),
]
)
# Data model
class code(BaseModel):
"""Schema for code solutions to questions about LCEL."""
prefix: str = Field(description="Description of the problem and approach")
imports: str = Field(description="Code block import statements")
code: str = Field(description="Code block not including import statements")
from langchain_openai import ChatOpenAI
"""
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
"""
llm = ChatOpenAI(
temperature=0,
model="deepseek-chat",
openai_api_key="your api key",
openai_api_base="https://api.deepseek.com"
)
code_gen_chain_oai = code_gen_prompt | llm.with_structured_output(code)
question = "How do I build a RAG chain in LCEL?"
solution = code_gen_chain_oai.invoke(
{"context": concatenated_content, "messages": [("user", question)]}
)
solution
输出
code(prefix='To build a Retrieval Augmented Generation (RAG) chain in LCEL, we will use the RunnableSequence to chain together a retriever and a language model. The retriever will fetch relevant documents, and the language model will generate a response based on those documents.', imports='from langchain_core.runnables import RunnableSequence\nfrom langchain.chat_models import ChatOpenAI\nfrom langchain.schema import StrOutputParser\nfrom langchain.retrievers import VectorStoreRetriever', code='retriever = VectorStoreRetriever(vectorstore=vectorstore)\nllm = ChatOpenAI()\nrag_chain = retriever | llm | StrOutputParser()\nresponse = rag_chain.invoke("Your query here")')
print(solution)
输出
prefix='To build a Retrieval Augmented Generation (RAG) chain in LCEL, we will use the RunnableSequence to chain together a retriever and a language model. The retriever will fetch relevant documents, and the language model will generate a response based on those documents.' imports='from langchain_core.runnables import RunnableSequence\nfrom langchain.chat_models import ChatOpenAI\nfrom langchain.schema import StrOutputParser\nfrom langchain.retrievers import VectorStoreRetriever' code='retriever = VectorStoreRetriever(vectorstore=vectorstore)\nllm = ChatOpenAI()\nrag_chain = retriever | llm | StrOutputParser()\nresponse = rag_chain.invoke("Your query here")'
3. graph状态 (graph运行时的数据结构)
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
error : Binary flag for control flow to indicate whether test error was tripped
messages : With user question, error messages, reasoning
generation : Code solution
iterations : Number of tries
"""
error: str
messages: List
generation: str
iterations: int
4. 生成节点、执行节点、反思节点函数
### Parameter
# Max tries
max_iterations = 3
# Reflect
# flag = 'reflect'
flag = "do not reflect"
### Nodes
def generate(state: GraphState):
"""
Generate a code solution
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation
"""
print("---GENERATING CODE SOLUTION---")
# State
messages = state["messages"]
iterations = state["iterations"]
error = state["error"]
# We have been routed back to generation with an error
if error == "yes":
messages += [
(
"user",
"Now, try again. Invoke the code tool to structure the output with a prefix, imports, and code block:",
)
]
# Solution
code_solution = code_gen_chain_oai.invoke(
{"context": concatenated_content, "messages": messages}
)
messages += [
(
"assistant",
f"{code_solution.prefix} \n Imports: {code_solution.imports} \n Code: {code_solution.code}",
)
]
# Increment
iterations = iterations + 1
return {"generation": code_solution, "messages": messages, "iterations": iterations}
def code_check(state: GraphState):
"""
Check code
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, error
"""
print("---CHECKING CODE---")
# State
messages = state["messages"]
code_solution = state["generation"]
iterations = state["iterations"]
# Get solution components
imports = code_solution.imports
code = code_solution.code
# Check imports
try:
exec(imports)
except Exception as e:
print("---CODE IMPORT CHECK: FAILED---")
error_message = [("user", f"Your solution failed the import test: {e}")]
messages += error_message
return {
"generation": code_solution,
"messages": messages,
"iterations": iterations,
"error": "yes",
}
# Check execution
try:
exec(imports + "\n" + code)
except Exception as e:
print("---CODE BLOCK CHECK: FAILED---")
error_message = [("user", f"Your solution failed the code execution test: {e}")]
messages += error_message
return {
"generation": code_solution,
"messages": messages,
"iterations": iterations,
"error": "yes",
}
# No errors
print("---NO CODE TEST FAILURES---")
return {
"generation": code_solution,
"messages": messages,
"iterations": iterations,
"error": "no",
}
def reflect(state: GraphState):
"""
Reflect on errors
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation
"""
print("---GENERATING CODE SOLUTION---")
# State
messages = state["messages"]
iterations = state["iterations"]
code_solution = state["generation"]
# Prompt reflection
# Add reflection
reflections = code_gen_chain_oai.invoke(
{"context": concatenated_content, "messages": messages}
)
messages += [("assistant", f"Here are reflections on the error: {reflections}")]
return {"generation": code_solution, "messages": messages, "iterations": iterations}
### Edges
def decide_to_finish(state: GraphState):
"""
Determines whether to finish.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
error = state["error"]
iterations = state["iterations"]
if error == "no" or iterations == max_iterations:
print("---DECISION: FINISH---")
return "end"
else:
print("---DECISION: RE-TRY SOLUTION---")
if flag == "reflect":
return "reflect"
else:
return "generate"
5. graph 各个边连接
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("generate", generate) # generation solution
workflow.add_node("check_code", code_check) # check code
workflow.add_node("reflect", reflect) # reflect
# Build graph
workflow.add_edge(START, "generate")
workflow.add_edge("generate", "check_code")
workflow.add_conditional_edges(
"check_code",
decide_to_finish,
{
"end": END,
"reflect": "reflect",
"generate": "generate",
},
)
workflow.add_edge("reflect", "generate")
app = workflow.compile()
可视化
from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
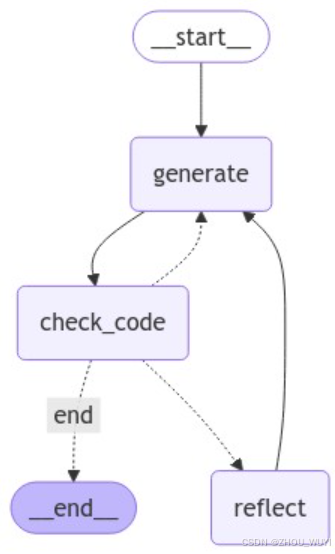
6. 示例
question = "How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?"
solution = app.invoke({"messages": [("user", question)], "iterations": 0, "error": ""})
---GENERATING CODE SOLUTION---
---CHECKING CODE---
---CODE BLOCK CHECK: FAILED---
---DECISION: RE-TRY SOLUTION---
---GENERATING CODE SOLUTION---
---CHECKING CODE---
text='This is a prompt with processed input: HELLO WORLD'
---NO CODE TEST FAILURES---
---DECISION: FINISH---
输出
print(solution)
{'error': 'no', 'messages': [('user', 'How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?'), ('assistant', "To directly pass a string to a runnable and use it to construct the input needed for your prompt, you can use the RunnableLambda to wrap a function that processes the string and then chain it with other runnables to form the final input for your prompt. \n Imports: from langchain_core.runnables import RunnableLambda, RunnableSequence\nfrom langchain.prompts import PromptTemplate \n Code: def process_string(input_string):\n # Example function to process the string\n return {'processed_input': input_string.upper()}\n\n# Define your prompt template\nprompt_template = PromptTemplate.from_template('This is a prompt with processed input: {processed_input}')\n\n# Create the chain\nchain = RunnableSequence([\n RunnableLambda(process_string),\n prompt_template\n])\n\n# Example input string\ninput_string = 'hello world'\n\n# Invoke the chain\nfinal_output = chain.invoke(input_string)\nprint(final_output)"), ('user', "Your solution failed the code execution test: Expected a Runnable, callable or dict.Instead got an unsupported type: <class 'list'>"), ('user', 'Now, try again. Invoke the code tool to structure the output with a prefix, imports, and code block:'), ('assistant', "To directly pass a string to a runnable and use it to construct the input needed for your prompt, you can use the RunnableLambda to wrap a function that processes the string and then chain it with other runnables to form the final input for your prompt. \n Imports: from langchain_core.runnables import RunnableLambda, RunnableSequence\nfrom langchain.prompts import PromptTemplate \n Code: def process_string(input_string):\n # Example function to process the string\n return {'processed_input': input_string.upper()}\n\n# Define your prompt template\nprompt_template = PromptTemplate.from_template('This is a prompt with processed input: {processed_input}')\n\n# Create the chain\nchain = RunnableLambda(process_string) | prompt_template\n\n# Example input string\ninput_string = 'hello world'\n\n# Invoke the chain\nfinal_output = chain.invoke(input_string)\nprint(final_output)")], 'generation': code(prefix='To directly pass a string to a runnable and use it to construct the input needed for your prompt, you can use the RunnableLambda to wrap a function that processes the string and then chain it with other runnables to form the final input for your prompt.', imports='from langchain_core.runnables import RunnableLambda, RunnableSequence\nfrom langchain.prompts import PromptTemplate', code="def process_string(input_string):\n # Example function to process the string\n return {'processed_input': input_string.upper()}\n\n# Define your prompt template\nprompt_template = PromptTemplate.from_template('This is a prompt with processed input: {processed_input}')\n\n# Create the chain\nchain = RunnableLambda(process_string) | prompt_template\n\n# Example input string\ninput_string = 'hello world'\n\n# Invoke the chain\nfinal_output = chain.invoke(input_string)\nprint(final_output)"), 'iterations': 2}
print(solution["generation"].imports)
print(solution["generation"].code)
输出
from langchain_core.runnables import RunnableLambda, RunnableSequence
from langchain.prompts import PromptTemplate
def process_string(input_string):
# Example function to process the string
return {'processed_input': input_string.upper()}
# Define your prompt template
prompt_template = PromptTemplate.from_template('This is a prompt with processed input: {processed_input}')
# Create the chain
chain = RunnableLambda(process_string) | prompt_template
# Example input string
input_string = 'hello world'
# Invoke the chain
final_output = chain.invoke(input_string)
print(final_output)
自己代码测试,运行成功
from langchain_core.runnables import RunnableLambda, RunnableSequence
from langchain.prompts import PromptTemplate
def process_string(input_string):
# Example function to process the string
return {'processed_input': input_string.upper()}
# Define your prompt template
prompt_template = PromptTemplate.from_template('This is a prompt with processed input: {processed_input}')
# Create the chain
chain = RunnableLambda(process_string) | prompt_template
# Example input string
input_string = 'hello world'
# Invoke the chain
final_output = chain.invoke(input_string)
print(final_output)
text='This is a prompt with processed input: HELLO WORLD'
参考链接: https://langchain-ai.github.io/langgraph/tutorials/code_assistant/langgraph_code_assistant/#graph

















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









