







突破代码生成瓶颈:S*框架如何让小模型超越GPT-4?
近年来,大型语言模型(LLMs)在代码生成任务中展现了惊人的潜力。然而,如何通过优化测试时的计算资源(Test-Time Scaling)提升模型性能,尤其是针对复杂代码生成任务,仍是一个待解的难题。近日,加州大学伯克利分校的研究团队提出了一种全新的混合测试时扩展框架——S*,在代码生成领域实现了多项突破。本文将从方法创新、实验结果和应用价值三个方面解析这一研究。
一、为什么代码生成需要新的测试时扩展方法?
传统的测试时扩展方法(如并行采样、顺序优化)在数学推理任务中已取得显著效果,但在代码生成领域却面临两大挑战:
- 正确性验证复杂
数学问题可通过字符串匹配快速验证答案,而代码的正确性需要执行大量测试用例,且测试输入的质量直接影响验证结果。 - 模型幻觉干扰选择
现有方法依赖模型生成测试用例或通过LLM直接判断代码优劣,但模型可能因幻觉生成不可靠的测试输入或误判代码行为。
针对这些问题,S*框架提出了混合扩展策略,结合并行采样与顺序调试,并引入自适应输入合成机制,显著提升了代码生成的覆盖率和选择准确性。
二、S*框架:两大阶段突破性能瓶颈
阶段一:混合生成——并行+顺序扩展
- 并行采样:生成多个候选代码样本,利用多样性提高覆盖率。
- 迭代调试:基于公共测试用例的反馈(如执行结果或报错信息),对每个样本进行多轮优化。例如,若代码在某个测试用例中报错,模型会分析错误原因并修正代码,直到通过所有公共测试或达到最大调试轮数。
阶段二:自适应选择——执行驱动的智能筛选
- 输入合成:针对每对候选代码,提示LLM生成能够区分两者的测试输入。例如,对于两个排序算法,可能生成包含重复元素的输入以检验稳定性。
- 执行验证:实际运行合成输入,根据执行结果(如输出正确性或报错信息)选择更优的代码。这一过程通过真实执行结果而非模型预测,大幅降低了幻觉干扰。
三、实验结果:小模型逆袭,性能逼近SOTA
研究团队在LiveCodeBench和CodeContests两大基准上评估了S*,覆盖12种不同规模的模型(从0.5B到32B),包括开源模型(如Qwen-Coder)和闭源模型(如GPT-4o-mini)。关键结论如下:
1. 小模型逆袭大模型
- Qwen2.5-7B + S* 在LiveCodeBench上比原版32B模型性能提升10.7%。
- 3B模型 + S* 直接超越未优化的GPT-4o-mini。
2. 非推理模型反超推理模型
- GPT-4o-mini + S* 在LiveCodeBench上以3.7%的优势击败专为推理设计的o1-preview模型。
3. 开源模型逼近闭源SOTA
- DeepSeek-R1-Distill-Qwen-32B + S* 达到85.7%的准确率,接近闭源模型o1-high(88.5%)。
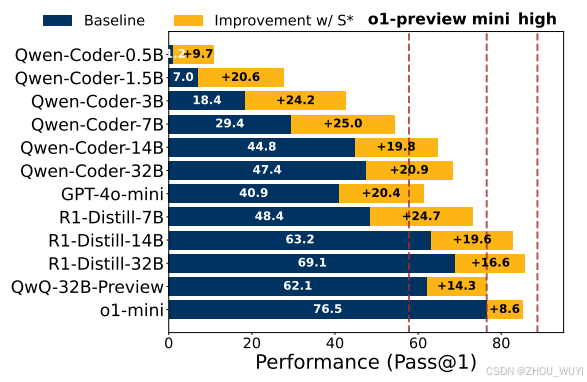
图:S*在不同模型上的性能提升(来源:论文Table 1)
四、技术细节:温度、样本数与提示工程
关键参数影响
- 温度(Temperature):适中的温度(0.7)平衡多样性与代码质量,过高(>0.9)会导致性能下降。
- 并行样本数:性能随样本数增加呈对数线性提升。例如,Qwen-Coder-7B在64个样本下性能提升35%。
提示工程优化
- 迭代调试提示:将历史代码与测试反馈整合到提示中,引导模型分析错误并修正。
- 自适应输入合成提示:要求模型生成覆盖边界条件的测试用例(如空数组、极端值),并以JSON格式返回输入输出对。
五、意义与展望
S*框架的提出为代码生成任务提供了新的优化方向:
- 低成本高性能:让小模型通过计算资源优化达到甚至超越大模型的表现,降低实际部署成本。
- 通用性:适用于不同架构的模型(指令型、推理型)和多种编程场景(竞赛题目、算法实现)。
- 可解释性:通过执行反馈和自适应输入合成,增强代码生成过程的透明性。
未来,这一框架可进一步扩展至软件工程任务(如代码补全、缺陷修复),并与强化学习结合,实现更智能的自动化编程。
论文地址:https://arxiv.org/abs/2502.14382
代码开源:https://github.com/NovaSky-AI/SkyThought

















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









