









本文实验中使用到的词向量为
https://github.com/Embedding/Chinese-Word-Vectors
上的sgns.baidubaike.bigram-char
如想复现实验,请自行下载。
实验的流程是:
1 先从预训练的词向量中词表的抽取二字词语,三字词语,四字词语分别20,30,40条,并根据字是否存在于词表中,保存三种词语各十条,以及其对应的字。
2 根据目前得到的数据在sgns.baidubaike.bigram-char中得到对应的词向量(这一步是因为词向量太大懒得等写的,可以用这个词向量直接比较的)
3 将词向量与字向量进行比较
首先请自行提取出该词向量的词表,我这里命名为baidubaike_vocab.txt。
def is_Chinese(word): # 修改过的
for ch in word:
if '\u4e00' > ch or ch > '\u9fff':
return False
return True
total=[]
#读取词表
with open("./baidubaike_vocab.txt","r",encoding="utf-8") as f:
lines=f.readlines()
for line in lines:
total.append(line.strip())
#提取词语
two=0
three=0
four=0
two_chars=[]
three_chars=[]
four_chars=[]
for i in total:
if is_Chinese(i) and len(i)==2 and two<20:#20条
two_chars.append(i.strip())
two+=1
if is_Chinese(i) and len(i)==3 and three<30:#防止等下拆分时,字向量不足,多拆几条
three_chars.append(i.strip())
three+=1
if is_Chinese(i) and len(i)==4 and four<40:#与上相同
four_chars.append(i.strip())
four+=1
print(len(two_chars))
print(two_chars)
#判断词向量中是否包含与词对应的字向量
two_char_contain=[]
three_char_contain=[]
four_char_contain=[]
num=0
for i in two_chars:#分解二字词分解为字
temp_num=0
for j in i:
if j in total:
temp_num+=1
if temp_num==2 and num<10 :
two_char_contain.append(i)
num+=1
num=0
for i in three_chars:#分解三字词分解为字
temp_num=0
for j in i:
if j in total:
temp_num+=1
if temp_num==3 and num<10 :
three_char_contain.append(i)
num+=1
num=0
for i in four_chars:#分解四字词分解为字
temp_num=0
for j in i:
if j in total:
temp_num+=1
if temp_num==4 and num<10 :
four_char_contain.append(i)
num+=1
#保存提取出来的词语
with open("./contain_word_chinese.txt","w",encoding="utf-8") as f:
for i in [two_char_contain,three_char_contain,four_char_contain]:
for j in i:
f.write(j+"\n")
就此,我们得到了一个contain_word_chinese.txt词表。
其中的提取的三十个词语为:
['一个', '中国', '可以', '发展', '主要', '工作', '研究', '自己', '进行', '第一', '出版社', '委员会', '平方米', '计算机', '研究生', '研究所', '副主任', '进一步', '实验室', '情况下', '有限公司', '平方公里', '内容提要', '出版日期', '社会主义', '人民政府', '作者简介', '中共党员', '经济发展', '硕士学位']
字,就不在这里列出了。
#获取前面得到的词表
total=[]
with open("./contain_word_chinese.txt","r",encoding="utf-8") as f:
lines=f.readlines()
for line in lines:
total.append(line.strip())
#加载词向量
tmp_file="./embedding/sgns.baidubaike.bigram-char/sgns.baidubaike.bigram-char"
from gensim.models import KeyedVectors
word2vec = KeyedVectors.load_word2vec_format(tmp_file, binary=False)
print("word2vec load finish!")
#提取词向量和字向量
word_to_vector={}
for word in total:
word_to_vector[word]=word2vec.word_vec(word)
for char in word:
word_to_vector[char] = word2vec.word_vec(char)
print("embedding extract finish!")
#将提取到的词向量和字向量保存起来
with open("./contain_word_chinese_embedding.txt","w",encoding="utf-8") as f:
lenght=len(word_to_vector)
f.write(str(lenght)+" "+str(300)+"\n")
for k ,v in word_to_vector.items():
f.write(str(k)+" ")
for e in v:
f.write(str(e)+" ")
f.write("\n")
print("all finish!")
之后我们就得到了一个word2vec格式的contain_word_chinese_embedding.txt文件。我们可以从中取得我们需要的词向量。之所以有这一步是因为那个baidubaike的词向量太大了,每次加载都花不少时间,因此我就自己划分一个词向量出来。(这一步是可以省略的)
from gensim.models import KeyedVectors
import numpy as np
import torch
word_to_score={}
#获取新的词向量
tmp_file="./contain_word_chinese_embedding.txt"
word2vec = KeyedVectors.load_word2vec_format(tmp_file, binary=False)
print("word2vec load finish!")
words=[]
#看一下非字词表
for word in word2vec.vocab:
if len(word)>1:
words.append(word)
print(words)
#比较
for word in words:
word_emb=word2vec.word_vec(word).reshape(1,300)
char_embs=[]
char_fusion_emb=np.zeros((1,300))
#char_fusion_emb=np.ones((1,300))
for char in word:
char_embs.append(word2vec.word_vec(char))
num=0
for char_emb in char_embs:#字向量融合
char_fusion_emb+=char_emb
num+=1
char_fusion_emb=char_fusion_emb/float(num)
#转tensor
word_tensor=torch.from_numpy(word_emb)
char_fusion_tensor=torch.from_numpy(char_fusion_emb)
#获取cos分数
similarity_score= torch.cosine_similarity(word_tensor,char_fusion_tensor)
word_to_score[word]=similarity_score
#输出cos分数
total_value=0
for k,v in word_to_score.items():
if abs(v.item()-1)>0.0001:
total_value+=v.item()
print(k,v.item())
total_value=total_value/float(len(words))
print("平均得分:",total_value)
字向量融合方式:
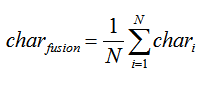
结果输出:
['一个', '中国', '可以', '发展', '主要', '工作', '研究', '自己', '进行', '第一', '出版社', '委员会', '平方米', '计算机', '研究生', '研究所', '副主任', '进一步', '实验室', '情况下', '有限公司', '平方公里', '内容提要', '出版日期', '社会主义', '人民政府', '作者简介', '中共党员', '经济发展', '硕士学位']
一个 0.7494857788982914
中国 0.28281657907023006
可以 0.764645060315011
发展 0.3223591478124087
主要 0.42099261801896987
工作 0.2471537364615638
研究 0.512840468591701
自己 0.391415603236476
进行 0.3320681787865863
第一 0.7475636377423762
出版社 0.4776548426505439
委员会 0.5351957844312847
平方米 0.5114881458334584
计算机 0.3960842065526681
研究生 0.41776947454667823
研究所 0.4871258125342379
副主任 0.585286646520381
进一步 0.3165391142475023
实验室 0.4385111738719156
情况下 0.4749211744490079
有限公司 0.36478330705994977
平方公里 0.3632623804984758
内容提要 0.361324782507569
出版日期 0.3973236135260835
社会主义 0.3189058267179325
人民政府 0.3457586875500742
作者简介 0.31306311227614875
中共党员 0.41065932379961617
经济发展 0.3462405601577103
硕士学位 0.511915979401771
平均得分: 0.4381718252688874
从上面可以看到直接通过字向量相加取平均的方式,并不能直接得到比较好的词向量表示。首先是每个字向量融合之后,与词向量表示之间的余弦差距不同意,从0.2到0.7之间,但还是有一定的关联的,毕竟余弦相似度取值范围为【-1,1】之间。并且10个样例的平均得分为0.43,这么来看的话,这种方式也不失为一种可行的字向量融合代替词向量的方式。不过我们还是得考虑一个问题,就是这样的词向量,会不会因为其中的不准确部分,导致最后的模型因为这种初始数据上的偏差出现性能下降的问题。
字向量融合方式:
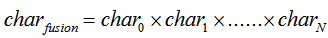
char_fusion_emb=np.ones((1,300))
for char_emb in char_embs:#字向量融合
char_fusion_emb*=char_emb
num+=1
输出结果如下:
一个 0.05366724256654402
中国 -0.03198817921911852
可以 0.16725042423293837
发展 -0.02650904047658194
主要 0.061339294141031314
工作 0.0017649052096961578
研究 0.03533298206002941
自己 -0.05138039834255122
进行 0.031241711138349292
第一 0.027186899924524797
出版社 0.05793666438896731
委员会 0.2895721749754044
平方米 0.2527875187816585
计算机 0.17356681270509203
研究生 0.12240461340542508
研究所 0.3123012973530254
副主任 0.34129465017536215
进一步 0.11455731120843657
实验室 0.1299015235965974
情况下 0.11276756413202814
有限公司 0.0513606279432186
平方公里 -0.07352041453539222
内容提要 -0.1725847405774953
出版日期 0.021079613038710043
社会主义 -0.10828211542734732
人民政府 0.10681433273184773
作者简介 -0.02566357955234621
中共党员 -0.008629310038142097
经济发展 -0.10853288376962895
硕士学位 -0.10074398790730817
平均得分: 0.05854311712876583
从上可得,通过叉乘的方式,并不适用于融合字向量代替词向量,这样做的效果实在太差,且不说平均得分只有0.058,其取值当中都出现了负值,这就意味着负相关,如果以此输入到模型当中,就不是在帮助模型改善性能,而是给数据添加噪声,添乱了。
字向量融合方式:
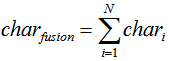
去掉后面那个取平均的操作。
结果输出:
一个 0.7494857788982914
中国 0.28281657907023006
可以 0.764645060315011
发展 0.3223591478124087
主要 0.42099261801896987
工作 0.2471537364615638
研究 0.512840468591701
自己 0.391415603236476
进行 0.3320681787865863
第一 0.7475636377423762
出版社 0.477654842650544
委员会 0.5351957844312848
平方米 0.5114881458334585
计算机 0.396084206552668
研究生 0.4177694745466782
研究所 0.48712581253423826
副主任 0.5852866465203809
进一步 0.31653911424750236
实验室 0.43851117387191557
情况下 0.4749211744490077
有限公司 0.36478330705994977
平方公里 0.3632623804984758
内容提要 0.361324782507569
出版日期 0.3973236135260835
社会主义 0.3189058267179325
人民政府 0.3457586875500742
作者简介 0.31306311227614875
中共党员 0.41065932379961617
经济发展 0.3462405601577103
硕士学位 0.511915979401771
平均得分: 0.4381718252688875
由此,可以看出对词向量是否取平均,对向量之间的余弦相似度基本没什么影响。
字向量融合方式:
先相加取平均再叉乘
一个 0.5356369548970294
中国 0.16384590742802865
可以 0.447768422114851
发展 0.16136117441456696
主要 0.25382697720323755
工作 0.23855267193204008
研究 0.3819086624759957
自己 0.26676186532975454
进行 0.1627686775022391
第一 0.4956039903761125
出版社 -0.10211437915128874
委员会 0.2432400639521136
平方米 -0.11853758895799987
计算机 0.009244957941026323
研究生 0.09964970194186082
研究所 -0.16535387530567175
副主任 0.03167745557801223
进一步 -0.0951938775467186
实验室 0.09900041068183729
情况下 0.07092348925295637
有限公司 0.15644153981398431
平方公里 0.0693196212531569
内容提要 0.2048515808144714
出版日期 0.0862387863839441
社会主义 0.10042687668347286
人民政府 0.13234729479829596
作者简介 0.015368276226672268
中共党员 0.10464287780139452
经济发展 -0.02957626380781289
硕士学位 0.1536932752221019
平均得分: 0.1391441842416555
字向量融合方式:
将相加平均得到的向量与叉乘得到的向量进行相加。
一个 0.6738984009317994
中国 0.25072466852818104
可以 0.7041446406060579
发展 0.2669400392576002
主要 0.4031035061899589
工作 0.21819265571682142
研究 0.4556827609812813
自己 0.3173517736803093
进行 0.31127031006351935
第一 0.6748640202866527
出版社 0.43289616478613074
委员会 0.5431898446429226
平方米 0.5042050361884618
计算机 0.38593212893225604
研究生 0.39825007578671195
研究所 0.5018878426064247
副主任 0.5782227366271816
进一步 0.3065305260042832
实验室 0.4186601995172072
情况下 0.46548866736794675
有限公司 0.36448886031071304
平方公里 0.364162543150963
内容提要 0.3443431425814262
出版日期 0.4014116000351594
社会主义 0.3048647882466499
人民政府 0.3534727355335636
作者简介 0.3037150853828897
中共党员 0.41270267906043295
经济发展 0.33902433558522044
硕士学位 0.4941423748788663
平均得分: 0.416458804782253
字符融合方式:
将相加平均和与叉乘向量相乘。
一个 0.5356369550511081
中国 0.1638459072076084
可以 0.4477684244445773
发展 0.16136117707421663
主要 0.253826975866132
工作 0.238552670963026
研究 0.38190866377069194
自己 0.2667618662150544
进行 0.1627686777371992
第一 0.4956039863953303
平均得分: 0.3108035304724944
再单纯将词向量和字向量进行比较:
一个 一 0.5554570734217611 个 0.6333395499230653
中国 中 0.1680185193513254 国 0.25574843961055654
可以 可 0.7992089525150983 以 0.3962566200914077
发展 发 0.2718925320078519 展 0.23501813928783413
主要 主 0.37158452369850375 要 0.2676436739797587
工作 工 0.18906476486421747 作 0.2022498202751
研究 研 0.43832870563303733 究 0.3986796768467963
自己 自 0.24721947334845976 己 0.36323201388689186
进行 进 0.25298204208666464 行 0.2760127133270841
第一 第 0.6564191094482077 一 0.4967552317199194
平均得分: 0.373755578766177
由此可以看得出叉乘完全不适合于融合字向量代替词向量,甚至可以说还起了一些负作用。叉乘得到的结果,比字向量自身与所构成词向量的余弦相似度分数还要低。
开始尝试点乘
字符融合方式:
先把两个向量进行点乘得到一个值,当做相加平均向量的偏置。
一个 -0.1026713623529857
中国 0.012130197961910612
可以 0.15330499825610291
发展 0.0577054403129661
主要 0.06063512360914453
工作 0.0234366877003529
研究 -0.00307655306936887
自己 0.017086353148439357
进行 0.005921279799955162
第一 -0.038610004874634556
平均得分: 0.009293108024594121
效果差得很啊!后面发现这点乘的结果值太大了。
字符融合方式:
把点乘值除以他的维度300,
一个 0.7332613380449879
中国 0.2824574070476015
可以 0.7635968970441682
发展 0.3242811682756887
主要 0.4213054551712334
工作 0.24719399650644117
研究 0.50188912612058
自己 0.3878032948479616
进行 0.32925452815906453
第一 0.740717382459686
平均得分: 0.4731760593677413
由此可见,点乘也并不适合字向量融合成词向量。
下面开始尝试lstm的长线依赖得到的向量表示,是否可以真的和句子表示相当。
下面是lstm的代码
import torch
import torch.nn as nn
class MyLSTM(nn.Module):
def __init__(self):
super(MyLSTM, self).__init__()
self.input_size=300
self.hidden_size=300
self.lstm=nn.LSTM(self.input_size,self.hidden_size,bidirectional=False,batch_first=True)
def forward(self,input_emb,hidden,cell):
output,(h,c)=self.lstm(input_emb,(hidden,cell))
return output,h
这是导入的代码
from LSTM import MyLSTM
myLstm=MyLSTM()
hidden = torch.zeros(1, 1, 300)
cell=torch.zeros(1, 1, 300)
这是获取值并转换的。
temp_char_embs=torch.from_numpy(char_embs).float()
char_embs,h=myLstm(temp_char_embs,hidden,cell)
char_embs=char_embs.detach().numpy()
字符融合方式:
直接使用获取到长线依赖的char_embs进行相加求和再比较
一个 0.012399177712208323
中国 -0.07436072285160734
可以 -0.023090075943349383
发展 -0.03698107898793139
主要 -0.036023199927272494
工作 0.038841698874929435
研究 -0.07292080863004768
自己 -0.04078667848248942
进行 0.00917234770335674
第一 0.005893595406889161
平均得分: -0.021785574512531405
效果差得有些不敢相信,看来后续的训练部分也是很有必要的啊!
字符融合方式:
直接将隐藏最后一个状态的h向量作为句子表示与词向量进行比较。
一个 -0.06611631065607071
中国 0.0570465587079525
可以 0.055485062301158905
发展 -0.02687864378094673
主要 0.04550324007868767
工作 -0.006241649389266968
研究 -0.02167399227619171
自己 -0.005265453364700079
进行 0.09354227781295776
第一 -0.04773516207933426
hidden 平均得分: 0.007766592735424638
因为权重不定的问题,这里的分数其实不太能够参考的。
对权重进行初始化
def init_weights(self):
''' Initialize weights of lstm 1 '''
for name_1, param_1 in self.lstm.named_parameters():
if 'bias' in name_1:
nn.init.constant_(param_1, 0.0)
elif 'weight' in name_1:
nn.init.xavier_normal_(param_1)
初始化之后的四次结果
hidden 平均得分: 0.00947720806580037
hidden 平均得分: 0.01597743425518274
hidden 平均得分: 0.018736699223518373
hidden 平均得分: -0.04542800448834896
由此可见,初始权重之后的效果,果然有所上升。















 2533
2533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









